 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARTiS: Appearance-based Action Recognition in Task Space for Real-Time Human-Robot Collaboration
Mar 07, 2017
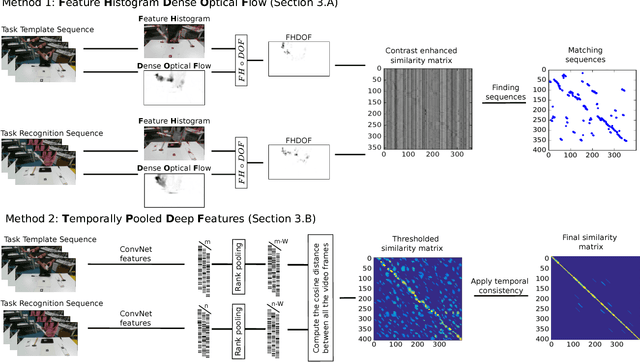
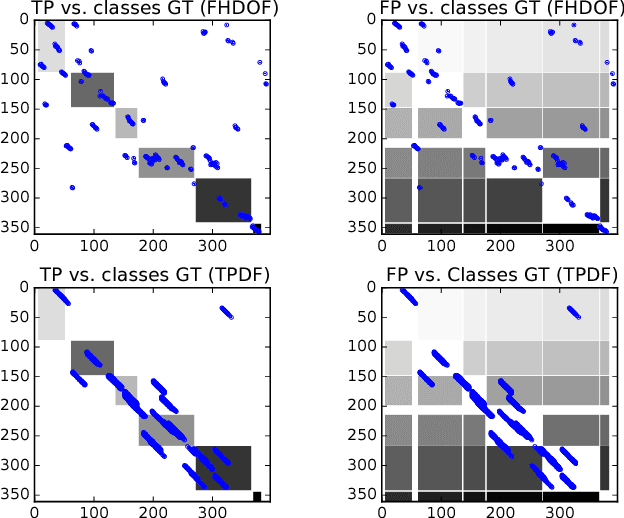
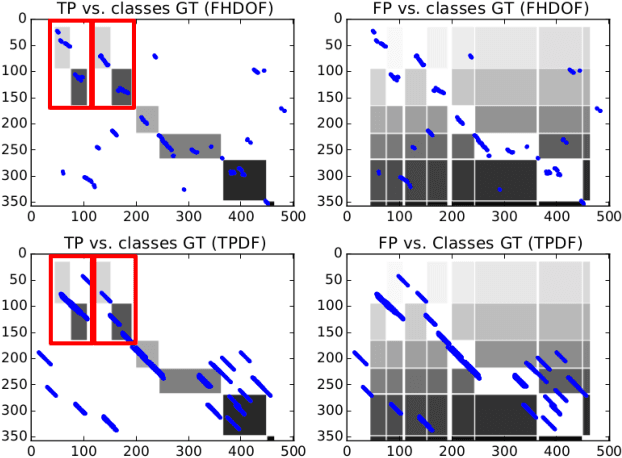
To have a robot actively supporting a human during a collaborative task, it is crucial that robots are able to identify the current action in order to predict the next one. Common approaches make use of high-level knowledge, such as object affordances, semantics or understanding of actions in terms of pre- and post-conditions. These approaches often require hand-coded a priori knowledge, time- and resource-intensive or supervised learning techniques. We propose to reframe this problem as an appearance-based place recognition problem. In our framework, we regard sequences of visual images of human actions as a map in analogy to the visual place recognition problem. Observing the task for the second time, our approach is able to recognize pre-observed actions in a one-shot learning approach and is thereby able to recognize the current observation in the task space. We propose two new methods for creating and aligning action observations within a task map. We compare and verify our approaches with real data of humans assembling several types of IKEA flat packs.
The ACRV Picking Benchmark : A Robotic Shelf Picking Benchmark to Foster Reproducible Research
Dec 14, 2016



Robotic challenges like the Amazon Picking Challenge (APC) or the DARPA Challenges are an established and important way to drive scientific progress. They make research comparable on a well-defined benchmark with equal test conditions for all participants. However, such challenge events occur only occasionally, are limited to a small number of contestants, and the test conditions are very difficult to replicate after the main event. We present a new physical benchmark challenge for robotic picking: the ACRV Picking Benchmark (APB). Designed to be reproducible, it consists of a set of 42 common objects, a widely available shelf, and exact guidelines for object arrangement using stencils. A well-defined evaluation protocol enables the comparison of \emph{complete} robotic systems -- including perception and manipulation -- instead of sub-systems only. Our paper also describes and reports results achieved by an open baseline system based on a Baxter robot.