 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation
Mar 13, 2025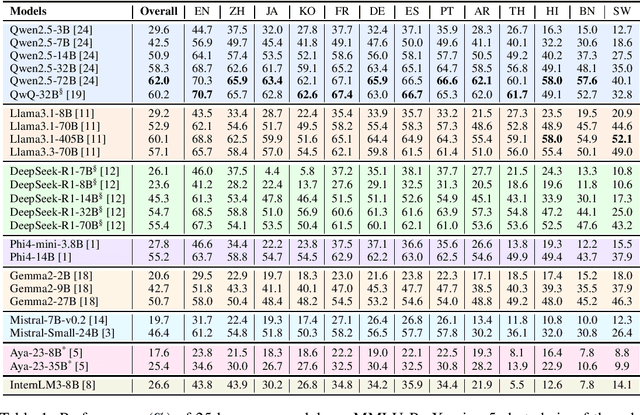
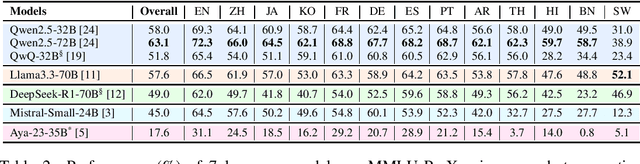
Traditional benchmarks struggle to evaluate increasingly sophisticated language models in multilingual and culturally diverse contexts. To address this gap, we introduce MMLU-ProX, a comprehensive multilingual benchmark covering 13 typologically diverse languages with approximately 11,829 questions per language. Building on the challenging reasoning-focused design of MMLU-Pro, our framework employs a semi-automatic translation process: translations generated by state-of-the-art large language models (LLMs) are rigorously evaluated by expert annotators to ensure conceptual accuracy, terminological consistency, and cultural relevance. We comprehensively evaluate 25 state-of-the-art LLMs using 5-shot chain-of-thought (CoT) and zero-shot prompting strategies, analyzing their performance across linguistic and cultural boundaries. Our experiments reveal consistent performance degradation from high-resource languages to lower-resource ones, with the best models achieving over 70% accuracy on English but dropping to around 40% for languages like Swahili, highlighting persistent gaps in multilingual capabilities despite recent advances. MMLU-ProX is an ongoing project; we are expanding our benchmark by incorporating additional languages and evaluating more language models to provide a more comprehensive assessment of multilingual capabilities.
ReAgent: Reversible Multi-Agent Reasoning for Knowledge-Enhanced Multi-Hop QA
Mar 10, 2025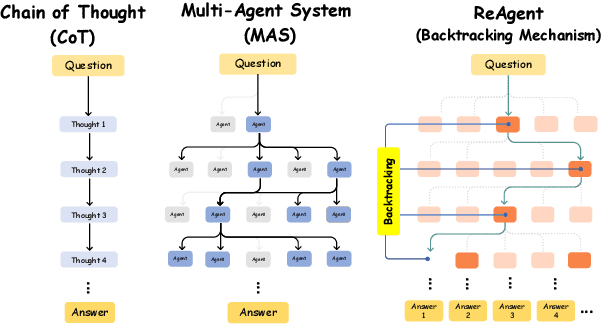
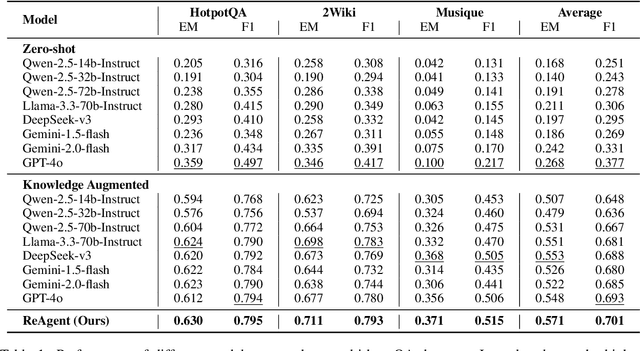
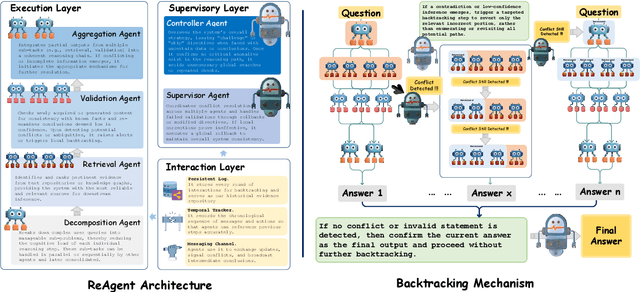
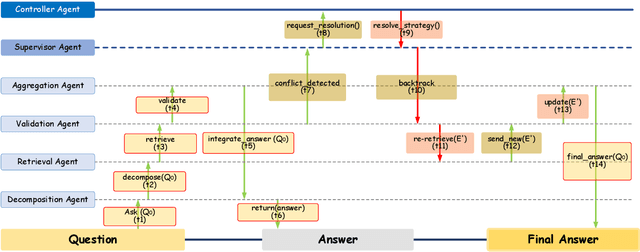
Recent advances in large language models (LLMs) have significantly improved multi-hop question answering (QA) through direct Chain-of-Thought (CoT) reasoning. However, the irreversible nature of CoT leads to error accumulation, making it challenging to correct mistakes in multi-hop reasoning. This paper introduces ReAgent: a Reversible multi-Agent collaborative framework augmented with explicit backtracking mechanisms, enabling reversible multi-hop reasoning. By incorporating text-based retrieval, information aggregation and validation, our system can detect and correct errors mid-reasoning, leading to more robust and interpretable QA outcomes. The framework and experiments serve as a foundation for future work on error-tolerant QA systems. Empirical evaluations across three benchmarks indicate ReAgent's efficacy, yielding average about 6\% improvements against baseline models.
GraphCheck: Breaking Long-Term Text Barriers with Extracted Knowledge Graph-Powered Fact-Checking
Feb 23, 2025Large language models (LLMs) are widely used, but they often generate subtle factual errors, especially in long-form text. These errors are fatal in some specialized domains such as medicine. Existing fact-checking with grounding documents methods face two main challenges: (1) they struggle to understand complex multihop relations in long documents, often overlooking subtle factual errors; (2) most specialized methods rely on pairwise comparisons, requiring multiple model calls, leading to high resource and computational costs. To address these challenges, we propose \textbf{\textit{GraphCheck}}, a fact-checking framework that uses extracted knowledge graphs to enhance text representation. Graph Neural Networks further process these graphs as a soft prompt, enabling LLMs to incorporate structured knowledge more effectively. Enhanced with graph-based reasoning, GraphCheck captures multihop reasoning chains which are often overlooked by existing methods, enabling precise and efficient fact-checking in a single inference call. Experimental results on seven benchmarks spanning both general and medical domains demonstrate a 6.1\% overall improvement over baseline models. Notably, GraphCheck outperforms existing specialized fact-checkers and achieves comparable performance with state-of-the-art LLMs, such as DeepSeek-V3 and OpenAI-o1, with significantly fewer parameters.
Graphusion: A RAG Framework for Knowledge Graph Construction with a Global Perspective
Oct 23, 2024



Knowledge Graphs (KGs) are crucial in the field of artificial intelligence and are widely used in downstream tasks, such as question-answering (QA). The construction of KGs typically requires significant effort from domain experts. Large Language Models (LLMs) have recently been used for Knowledge Graph Construction (KGC). However, most existing approaches focus on a local perspective, extracting knowledge triplets from individual sentences or documents, missing a fusion process to combine the knowledge in a global KG. This work introduces Graphusion, a zero-shot KGC framework from free text. It contains three steps: in Step 1, we extract a list of seed entities using topic modeling to guide the final KG includes the most relevant entities; in Step 2, we conduct candidate triplet extraction using LLMs; in Step 3, we design the novel fusion module that provides a global view of the extracted knowledge, incorporating entity merging, conflict resolution, and novel triplet discovery. Results show that Graphusion achieves scores of 2.92 and 2.37 out of 3 for entity extraction and relation recognition, respectively. Moreover, we showcase how Graphusion could be applied to the Natural Language Processing (NLP) domain and validate it in an educational scenario. Specifically, we introduce TutorQA, a new expert-verified benchmark for QA, comprising six tasks and a total of 1,200 QA pairs. Using the Graphusion-constructed KG, we achieve a significant improvement on the benchmark, for example, a 9.2% accuracy improvement on sub-graph completion.
Transformers4NewsRec: A Transformer-based News Recommendation Framework
Oct 17, 2024



Pre-trained transformer models have shown great promise in various natural language processing tasks, including personalized news recommendations. To harness the power of these models, we introduce Transformers4NewsRec, a new Python framework built on the \textbf{Transformers} library. This framework is designed to unify and compare the performance of various news recommendation models, including deep neural networks and graph-based models. Transformers4NewsRec offers flexibility in terms of model selection, data preprocessing, and evaluation, allowing both quantitative and qualitative analysis.
AGENTiGraph: An Interactive Knowledge Graph Platform for LLM-based Chatbots Utilizing Private Data
Oct 15, 2024



Large Language Models~(LLMs) have demonstrated capabilities across various applications but face challenges such as hallucination, limited reasoning abilities, and factual inconsistencies, especially when tackling complex, domain-specific tasks like question answering~(QA). While Knowledge Graphs~(KGs) have been shown to help mitigate these issues, research on the integration of LLMs with background KGs remains limited. In particular, user accessibility and the flexibility of the underlying KG have not been thoroughly explored. We introduce AGENTiGraph (Adaptive Generative ENgine for Task-based Interaction and Graphical Representation), a platform for knowledge management through natural language interaction. It integrates knowledge extraction, integration, and real-time visualization. AGENTiGraph employs a multi-agent architecture to dynamically interpret user intents, manage tasks, and integrate new knowledge, ensuring adaptability to evolving user requirements and data contexts. Our approach demonstrates superior performance in knowledge graph interactions, particularly for complex domain-specific tasks. Experimental results on a dataset of 3,500 test cases show AGENTiGraph significantly outperforms state-of-the-art zero-shot baselines, achieving 95.12\% accuracy in task classification and 90.45\% success rate in task execution. User studies corroborate its effectiveness in real-world scenarios. To showcase versatility, we extended AGENTiGraph to legislation and healthcare domains, constructing specialized KGs capable of answering complex queries in legal and medical contexts.
Graphusion: Leveraging Large Language Models for Scientific Knowledge Graph Fusion and Construction in NLP Education
Jul 15, 2024



Knowledge graphs (KGs) are crucial in the field of artificial intelligence and are widely applied in downstream tasks, such as enhancing Question Answering (QA) systems. The construction of KGs typically requires significant effort from domain experts. Recently, Large Language Models (LLMs) have been used for knowledge graph construction (KGC), however, most existing approaches focus on a local perspective, extracting knowledge triplets from individual sentences or documents. In this work, we introduce Graphusion, a zero-shot KGC framework from free text. The core fusion module provides a global view of triplets, incorporating entity merging, conflict resolution, and novel triplet discovery. We showcase how Graphusion could be applied to the natural language processing (NLP) domain and validate it in the educational scenario. Specifically, we introduce TutorQA, a new expert-verified benchmark for graph reasoning and QA, comprising six tasks and a total of 1,200 QA pairs. Our evaluation demonstrates that Graphusion surpasses supervised baselines by up to 10% in accuracy on link prediction. Additionally, it achieves average scores of 2.92 and 2.37 out of 3 in human evaluations for concept entity extraction and relation recognition, respectively.
KG-Rank: Enhancing Large Language Models for Medical QA with Knowledge Graphs and Ranking Techniques
Mar 09, 2024Large Language Models (LLMs) have significantly advanced healthcare innovation on generation capabilities. However, their application in real clinical settings is challenging due to potential deviations from medical facts and inherent biases. In this work, we develop an augmented LLM framework, KG-Rank, which leverages a medical knowledge graph (KG) with ranking and re-ranking techniques, aiming to improve free-text question-answering (QA) in the medical domain. Specifically, upon receiving a question, we initially retrieve triplets from a medical KG to gather factual information. Subsequently, we innovatively apply ranking methods to refine the ordering of these triplets, aiming to yield more precise answers. To the best of our knowledge, KG-Rank is the first application of ranking models combined with KG in medical QA specifically for generating long answers. Evaluation of four selected medical QA datasets shows that KG-Rank achieves an improvement of over 18% in the ROUGE-L score. Moreover, we extend KG-Rank to open domains, where it realizes a 14% improvement in ROUGE-L, showing the effectiveness and potential of KG-Rank.
Leveraging Large Language Models for Learning Complex Legal Concepts through Storytelling
Feb 26, 2024



Making legal knowledge accessible to non-experts is crucial for enhancing general legal literacy and encouraging civic participation in democracy. However, legal documents are often challenging to understand for people without legal backgrounds. In this paper, we present a novel application of large language models (LLMs) in legal education to help non-experts learn intricate legal concepts through storytelling, an effective pedagogical tool in conveying complex and abstract concepts. We also introduce a new dataset LegalStories, which consists of 295 complex legal doctrines, each accompanied by a story and a set of multiple-choice questions generated by LLMs. To construct the dataset, we experiment with various LLMs to generate legal stories explaining these concepts. Furthermore, we use an expert-in-the-loop method to iteratively design multiple-choice questions. Then, we evaluate the effectiveness of storytelling with LLMs through an RCT experiment with legal novices on 10 samples from the dataset. We find that LLM-generated stories enhance comprehension of legal concepts and interest in law among non-native speakers compared to only definitions. Moreover, stories consistently help participants relate legal concepts to their lives. Finally, we find that learning with stories shows a higher retention rate for non-native speakers in the follow-up assessment. Our work has strong implications for using LLMs in promoting teaching and learning in the legal field and beyond.
Leveraging Large Language Models for Concept Graph Recovery and Question Answering in NLP Education
Feb 22, 2024



In the domain of Natural Language Processing (NLP), Large Language Models (LLMs) have demonstrated promise in text-generation tasks. However, their educational applications, particularly for domain-specific queries, remain underexplored. This study investigates LLMs' capabilities in educational scenarios, focusing on concept graph recovery and question-answering (QA). We assess LLMs' zero-shot performance in creating domain-specific concept graphs and introduce TutorQA, a new expert-verified NLP-focused benchmark for scientific graph reasoning and QA. TutorQA consists of five tasks with 500 QA pairs. To tackle TutorQA queries, we present CGLLM, a pipeline integrating concept graphs with LLMs for answering diverse questions. Our results indicate that LLMs' zero-shot concept graph recovery is competitive with supervised methods, showing an average 3% F1 score improvement. In TutorQA tasks, LLMs achieve up to 26% F1 score enhancement. Moreover, human evaluation and analysis show that CGLLM generates answers with more fine-grained concepts.