 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Localization and Affordance Prediction for Tasks in Egocentric Video
Jul 18, 2024



Vision-Language Models (VLMs) have shown great success as foundational models for downstream vision and natural language applications in a variety of domains. However, these models lack the spatial understanding necessary for robotics applications where the agent must reason about the affordances provided by the 3D world around them. We present a system which trains on spatially-localized egocentric videos in order to connect visual input and task descriptions to predict a task's spatial affordance, that is the location where a person would go to accomplish the task. We show our approach outperforms the baseline of using a VLM to map similarity of a task's description over a set of location-tagged images. Our learning-based approach has less error both on predicting where a task may take place and on predicting what tasks are likely to happen at the current location. The resulting system enables robots to use egocentric sensing to navigate to physical locations of novel tasks specified in natural language.
NH-TTC: A gradient-based framework for generalized anticipatory collision avoidance
Jul 12, 2019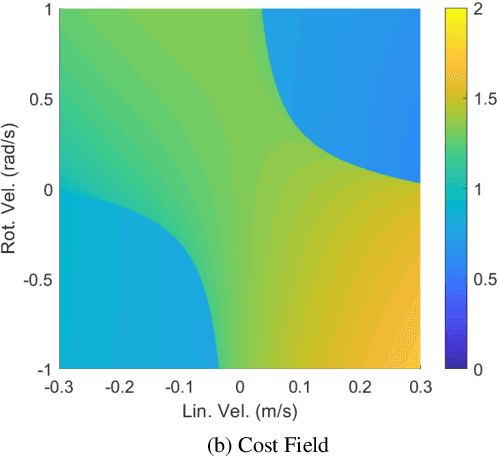
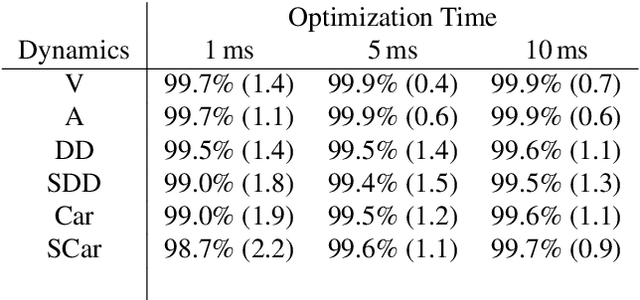
We propose NH-TTC, a general method for fast, anticipatory collision avoidance for autonomous robots having arbitrary equations of motions. Our proposed approach exploits implicit differentiation and subgradient descent to locally optimize the non-convex and non-smooth cost functions that arise from planning over the anticipated future positions of nearby obstacles. The result is a flexible framework capable of supporting high-quality, collision-free navigation with a wide variety of robot motion models in various challenging scenarios. We show results for different navigating tasks, with our method controlling various numbers of agents (with and without reciprocity), on both physical differential drive robots, and simulated robots with different motion models and kinematic and dynamic constraints, including acceleration-controlled agents, differential-drive agents, and smooth car-like agents. The resulting paths are high quality and collision-free, while needing only a few milliseconds of computation as part of an integrated sense-plan-act navigation loop.
ALAN: Adaptive Learning for Multi-Agent Navigation
Oct 11, 2017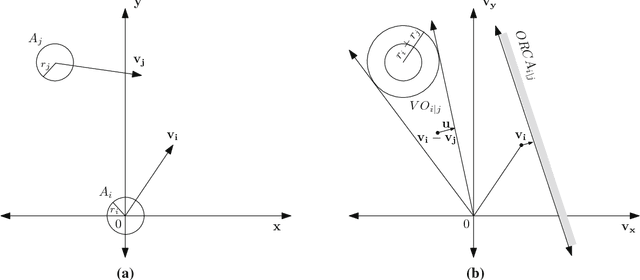
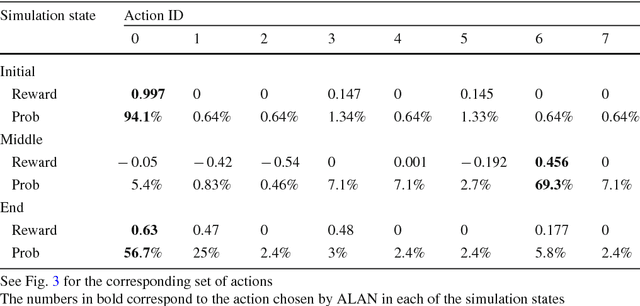
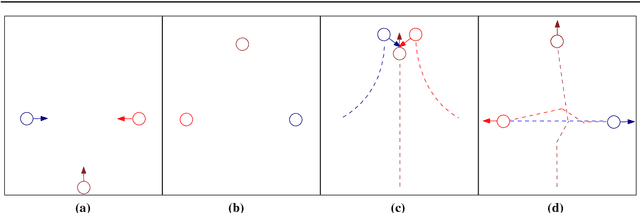
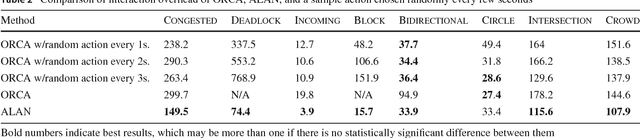
In multi-agent navigation, agents need to move towards their goal locations while avoiding collisions with other agents and static obstacles, often without communication with each other. Existing methods compute motions that are optimal locally but do not account for the aggregated motions of all agents, producing inefficient global behavior especially when agents move in a crowded space. In this work, we develop methods to allow agents to dynamically adapt their behavior to their local conditions. We accomplish this by formulating the multi-agent navigation problem as an action-selection problem, and propose an approach, ALAN, that allows agents to compute time-efficient and collision-free motions. ALAN is highly scalable because each agent makes its own decisions on how to move using a set of velocities optimized for a variety of navigation tasks. Experimental results show that the agents using ALAN, in general, reach their destinations faster than using ORCA, a state-of-the-art collision avoidance framework, the Social Forces model for pedestrian navigation, and a Predictive collision avoidance model.