 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Field Generation Based on Hybrid Mamba-Transformer with Physics-informed Fine-tuning
May 16, 2025This research confronts the challenge of substantial physical equation discrepancies encountered in the generation of spatiotemporal physical fields through data-driven trained models. A spatiotemporal physical field generation model, named HMT-PF, is developed based on the hybrid Mamba-Transformer architecture, incorporating unstructured grid information as input. A fine-tuning block, enhanced with physical information, is introduced to effectively reduce the physical equation discrepancies. The physical equation residuals are computed through a point query mechanism for efficient gradient evaluation, then encoded into latent space for refinement. The fine-tuning process employs a self-supervised learning approach to achieve physical consistency while maintaining essential field characteristics. Results show that the hybrid Mamba-Transformer model achieves good performance in generating spatiotemporal fields, while the physics-informed fine-tuning mechanism further reduces significant physical errors effectively. A MSE-R evaluation method is developed to assess the accuracy and realism of physical field generation.
Bridging Geometry-Coherent Text-to-3D Generation with Multi-View Diffusion Priors and Gaussian Splatting
May 07, 2025



Score Distillation Sampling (SDS) leverages pretrained 2D diffusion models to advance text-to-3D generation but neglects multi-view correlations, being prone to geometric inconsistencies and multi-face artifacts in the generated 3D content. In this work, we propose Coupled Score Distillation (CSD), a framework that couples multi-view joint distribution priors to ensure geometrically consistent 3D generation while enabling the stable and direct optimization of 3D Gaussian Splatting. Specifically, by reformulating the optimization as a multi-view joint optimization problem, we derive an effective optimization rule that effectively couples multi-view priors to guide optimization across different viewpoints while preserving the diversity of generated 3D assets. Additionally, we propose a framework that directly optimizes 3D Gaussian Splatting (3D-GS) with random initialization to generate geometrically consistent 3D content. We further employ a deformable tetrahedral grid, initialized from 3D-GS and refined through CSD, to produce high-quality, refined meshes. Quantitative and qualitative experimental results demonstrate the efficiency and competitive quality of our approach.
SDIGLM: Leveraging Large Language Models and Multi-Modal Chain of Thought for Structural Damage Identification
Apr 12, 2025Existing computer vision(CV)-based structural damage identification models demonstrate notable accuracy in categorizing and localizing damage. However, these models present several critical limitations that hinder their practical application in civil engineering(CE). Primarily, their ability to recognize damage types remains constrained, preventing comprehensive analysis of the highly varied and complex conditions encountered in real-world CE structures. Second, these models lack linguistic capabilities, rendering them unable to articulate structural damage characteristics through natural language descriptions. With the continuous advancement of artificial intelligence(AI), large multi-modal models(LMMs) have emerged as a transformative solution, enabling the unified encoding and alignment of textual and visual data. These models can autonomously generate detailed descriptive narratives of structural damage while demonstrating robust generalization across diverse scenarios and tasks. This study introduces SDIGLM, an innovative LMM for structural damage identification, developed based on the open-source VisualGLM-6B architecture. To address the challenge of adapting LMMs to the intricate and varied operating conditions in CE, this work integrates a U-Net-based semantic segmentation module to generate defect segmentation maps as visual Chain of Thought(CoT). Additionally, a multi-round dialogue fine-tuning dataset is constructed to enhance logical reasoning, complemented by a language CoT formed through prompt engineering. By leveraging this multi-modal CoT, SDIGLM surpasses general-purpose LMMs in structural damage identification, achieving an accuracy of 95.24% across various infrastructure types. Moreover, the model effectively describes damage characteristics such as hole size, crack direction, and corrosion severity.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
AI analysis of medical images at scale as a health disparities probe: a feasibility demonstration using chest radiographs
Apr 08, 2025



Health disparities (differences in non-genetic conditions that influence health) can be associated with differences in burden of disease by groups within a population. Social determinants of health (SDOH) are domains such as health care access, dietary access, and economics frequently studied for potential association with health disparities. Evaluating SDOH-related phenotypes using routine medical images as data sources may enhance health disparities research. We developed a pipeline for using quantitative measures automatically extracted from medical images as inputs into health disparities index calculations. Our study focused on the use case of two SDOH demographic correlates (sex and race) and data extracted from chest radiographs of 1,571 unique patients. The likelihood of severe disease within the lung parenchyma from each image type, measured using an established deep learning model, was merged into a single numerical image-based phenotype for each patient. Patients were then separated into phenogroups by unsupervised clustering of the image-based phenotypes. The health rate for each phenogroup was defined as the median image-based phenotype for each SDOH used as inputs to four imaging-derived health disparities indices (iHDIs): one absolute measure (between-group variance) and three relative measures (index of disparity, Theil index, and mean log deviation). The iHDI measures demonstrated feasible values for each SDOH demographic correlate, showing potential for medical images to serve as a novel probe for health disparities. Large-scale AI analysis of medical images can serve as a probe for a novel data source for health disparities research.
A Multi-Agent Framework with Automated Decision Rule Optimization for Cross-Domain Misinformation Detection
Mar 30, 2025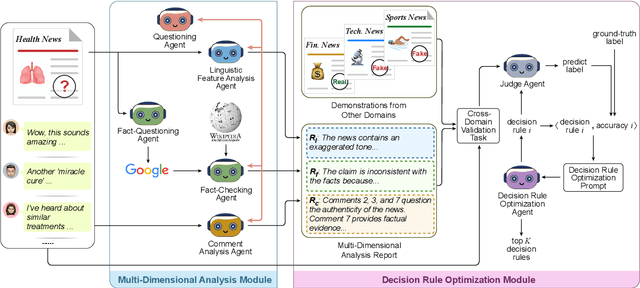
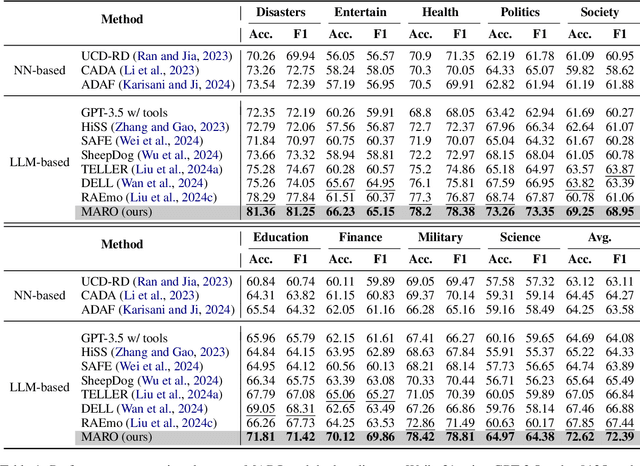
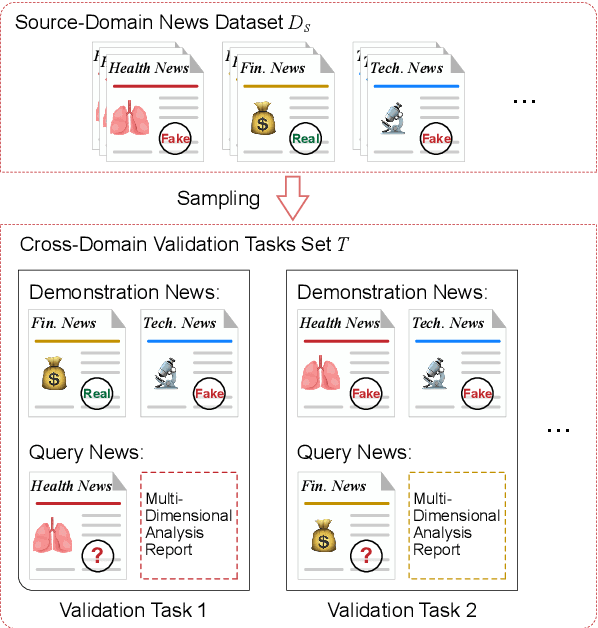
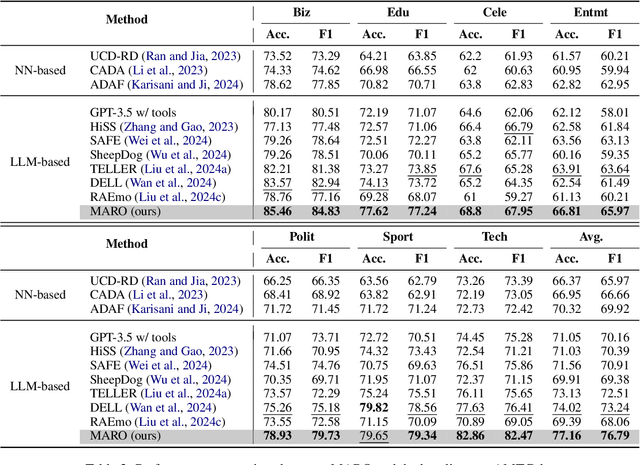
Misinformation spans various domains, but detection methods trained on specific domains often perform poorly when applied to others. With the rapid development of Large Language Models (LLMs), researchers have begun to utilize LLMs for cross-domain misinformation detection. However, existing LLM-based methods often fail to adequately analyze news in the target domain, limiting their detection capabilities. More importantly, these methods typically rely on manually designed decision rules, which are limited by domain knowledge and expert experience, thus limiting the generalizability of decision rules to different domains. To address these issues, we propose a MultiAgent Framework for cross-domain misinformation detection with Automated Decision Rule Optimization (MARO). Under this framework, we first employs multiple expert agents to analyze target-domain news. Subsequently, we introduce a question-reflection mechanism that guides expert agents to facilitate higherquality analysis. Furthermore, we propose a decision rule optimization approach based on carefully-designed cross-domain validation tasks to iteratively enhance the effectiveness of decision rules in different domains. Experimental results and in-depth analysis on commonlyused datasets demonstrate that MARO achieves significant improvements over existing methods.
OCCO: LVM-guided Infrared and Visible Image Fusion Framework based on Object-aware and Contextual COntrastive Learning
Mar 24, 2025Image fusion is a crucial technique in the field of computer vision, and its goal is to generate high-quality fused images and improve the performance of downstream tasks. However, existing fusion methods struggle to balance these two factors. Achieving high quality in fused images may result in lower performance in downstream visual tasks, and vice versa. To address this drawback, a novel LVM (large vision model)-guided fusion framework with Object-aware and Contextual COntrastive learning is proposed, termed as OCCO. The pre-trained LVM is utilized to provide semantic guidance, allowing the network to focus solely on fusion tasks while emphasizing learning salient semantic features in form of contrastive learning. Additionally, a novel feature interaction fusion network is also designed to resolve information conflicts in fusion images caused by modality differences. By learning the distinction between positive samples and negative samples in the latent feature space (contextual space), the integrity of target information in fused image is improved, thereby benefiting downstream performance. Finally, compared with eight state-of-the-art methods on four datasets, the effectiveness of the proposed method is validated, and exceptional performance is also demonstrated on downstream visual task.
Volumetric Reconstruction From Partial Views for Task-Oriented Grasping
Mar 19, 2025



Object affordance and volumetric information are essential in devising effective grasping strategies under task-specific constraints. This paper presents an approach for inferring suitable grasping strategies from limited partial views of an object. To achieve this, a recurrent generative adversarial network (R-GAN) was proposed by incorporating a recurrent generator with long short-term memory (LSTM) units for it to process a variable number of depth scans. To determine object affordances, the AffordPose knowledge dataset is utilized as prior knowledge. Affordance retrieving is defined by the volume similarity measured via Chamfer Distance and action similarities. A Proximal Policy Optimization (PPO) reinforcement learning model is further implemented to refine the retrieved grasp strategies for task-oriented grasping. The retrieved grasp strategies were evaluated on a dual-arm mobile manipulation robot with an overall grasping accuracy of 89% for four tasks: lift, handle grasp, wrap grasp, and press.
Learning a Unified Degradation-aware Representation Model for Multi-modal Image Fusion
Mar 10, 2025



All-in-One Degradation-Aware Fusion Models (ADFMs), a class of multi-modal image fusion models, address complex scenes by mitigating degradations from source images and generating high-quality fused images. Mainstream ADFMs often rely on highly synthetic multi-modal multi-quality images for supervision, limiting their effectiveness in cross-modal and rare degradation scenarios. The inherent relationship among these multi-modal, multi-quality images of the same scene provides explicit supervision for training, but also raises above problems. To address these limitations, we present LURE, a Learning-driven Unified Representation model for infrared and visible Image Fusion, which is degradation-aware. LURE decouples multi-modal multi-quality data at the data level and recouples this relationship in a unified latent feature space (ULFS) by proposing a novel unified loss. This decoupling circumvents data-level limitations of prior models and allows leveraging real-world restoration datasets for training high-quality degradation-aware models, sidestepping above issues. To enhance text-image interaction, we refine image-text interaction and residual structures via Text-Guided Attention (TGA) and an inner residual structure. These enhances text's spatial perception of images and preserve more visual details. Experiments show our method outperforms state-of-the-art (SOTA) methods across general fusion, degradation-aware fusion, and downstream tasks. The code will be publicly available.
One Model for ALL: Low-Level Task Interaction Is a Key to Task-Agnostic Image Fusion
Feb 27, 2025Advanced image fusion methods mostly prioritise high-level missions, where task interaction struggles with semantic gaps, requiring complex bridging mechanisms. In contrast, we propose to leverage low-level vision tasks from digital photography fusion, allowing for effective feature interaction through pixel-level supervision. This new paradigm provides strong guidance for unsupervised multimodal fusion without relying on abstract semantics, enhancing task-shared feature learning for broader applicability. Owning to the hybrid image features and enhanced universal representations, the proposed GIFNet supports diverse fusion tasks, achieving high performance across both seen and unseen scenarios with a single model. Uniquely, experimental results reveal that our framework also supports single-modality enhancement, offering superior flexibility for practical applications. Our code will be available at https://github.com/AWCXV/GIFNet.