 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Geometry-Coherent Text-to-3D Generation with Multi-View Diffusion Priors and Gaussian Splatting
May 07, 2025



Score Distillation Sampling (SDS) leverages pretrained 2D diffusion models to advance text-to-3D generation but neglects multi-view correlations, being prone to geometric inconsistencies and multi-face artifacts in the generated 3D content. In this work, we propose Coupled Score Distillation (CSD), a framework that couples multi-view joint distribution priors to ensure geometrically consistent 3D generation while enabling the stable and direct optimization of 3D Gaussian Splatting. Specifically, by reformulating the optimization as a multi-view joint optimization problem, we derive an effective optimization rule that effectively couples multi-view priors to guide optimization across different viewpoints while preserving the diversity of generated 3D assets. Additionally, we propose a framework that directly optimizes 3D Gaussian Splatting (3D-GS) with random initialization to generate geometrically consistent 3D content. We further employ a deformable tetrahedral grid, initialized from 3D-GS and refined through CSD, to produce high-quality, refined meshes. Quantitative and qualitative experimental results demonstrate the efficiency and competitive quality of our approach.
Self Sparse Generative Adversarial Networks
Jan 26, 2021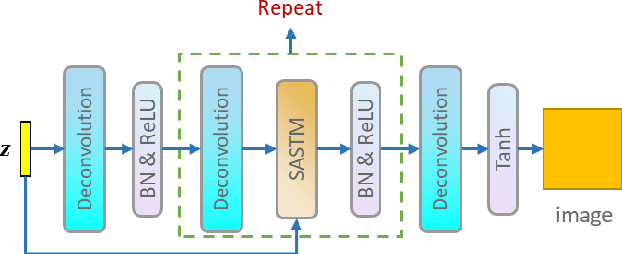
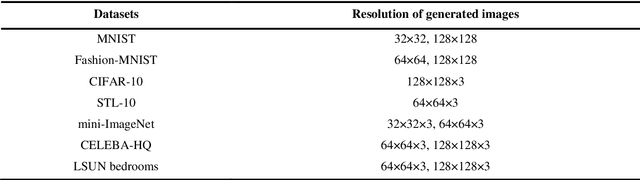
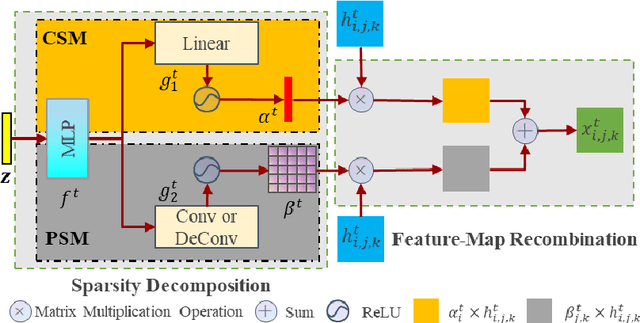
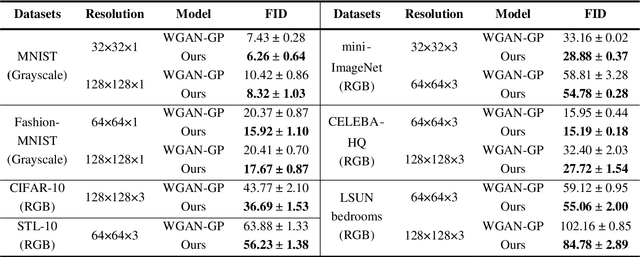
Generative Adversarial Networks (GANs) are an unsupervised generative model that learns data distribution through adversarial training. However, recent experiments indicated that GANs are difficult to train due to the requirement of optimization in the high dimensional parameter space and the zero gradient problem. In this work, we propose a Self Sparse Generative Adversarial Network (Self-Sparse GAN) that reduces the parameter space and alleviates the zero gradient problem. In the Self-Sparse GAN, we design a Self-Adaptive Sparse Transform Module (SASTM) comprising the sparsity decomposition and feature-map recombination, which can be applied on multi-channel feature maps to obtain sparse feature maps. The key idea of Self-Sparse GAN is to add the SASTM following every deconvolution layer in the generator, which can adaptively reduce the parameter space by utilizing the sparsity in multi-channel feature maps. We theoretically prove that the SASTM can not only reduce the search space of the convolution kernel weight of the generator but also alleviate the zero gradient problem by maintaining meaningful features in the Batch Normalization layer and driving the weight of deconvolution layers away from being negative. The experimental results show that our method achieves the best FID scores for image generation compared with WGAN-GP on MNIST, Fashion-MNIST, CIFAR-10, STL-10, mini-ImageNet, CELEBA-HQ, and LSUN bedrooms, and the relative decrease of FID is 4.76% ~ 21.84%.