 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Grasping Using Reinforcement Learning with a Contextual Reward Machine
Dec 11, 2025This paper presents a reinforcement learning framework that incorporates a Contextual Reward Machine for task-oriented grasping. The Contextual Reward Machine reduces task complexity by decomposing grasping tasks into manageable sub-tasks. Each sub-task is associated with a stage-specific context, including a reward function, an action space, and a state abstraction function. This contextual information enables efficient intra-stage guidance and improves learning efficiency by reducing the state-action space and guiding exploration within clearly defined boundaries. In addition, transition rewards are introduced to encourage or penalize transitions between stages which guides the model toward desirable stage sequences and further accelerates convergence. When integrated with the Proximal Policy Optimization algorithm, the proposed method achieved a 95% success rate across 1,000 simulated grasping tasks encompassing diverse objects, affordances, and grasp topologies. It outperformed the state-of-the-art methods in both learning speed and success rate. The approach was transferred to a real robot, where it achieved a success rate of 83.3% in 60 grasping tasks over six affordances. These experimental results demonstrate superior accuracy, data efficiency, and learning efficiency. They underscore the model's potential to advance task-oriented grasping in both simulated and real-world settings.
Volumetric Reconstruction From Partial Views for Task-Oriented Grasping
Mar 19, 2025



Object affordance and volumetric information are essential in devising effective grasping strategies under task-specific constraints. This paper presents an approach for inferring suitable grasping strategies from limited partial views of an object. To achieve this, a recurrent generative adversarial network (R-GAN) was proposed by incorporating a recurrent generator with long short-term memory (LSTM) units for it to process a variable number of depth scans. To determine object affordances, the AffordPose knowledge dataset is utilized as prior knowledge. Affordance retrieving is defined by the volume similarity measured via Chamfer Distance and action similarities. A Proximal Policy Optimization (PPO) reinforcement learning model is further implemented to refine the retrieved grasp strategies for task-oriented grasping. The retrieved grasp strategies were evaluated on a dual-arm mobile manipulation robot with an overall grasping accuracy of 89% for four tasks: lift, handle grasp, wrap grasp, and press.
Knowledge-Augmented Dexterous Grasping with Incomplete Sensing
Nov 17, 2020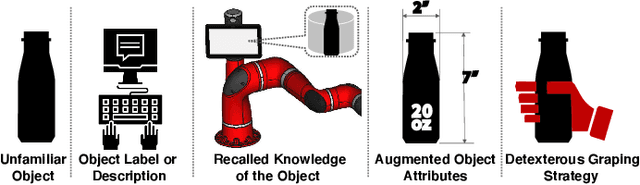

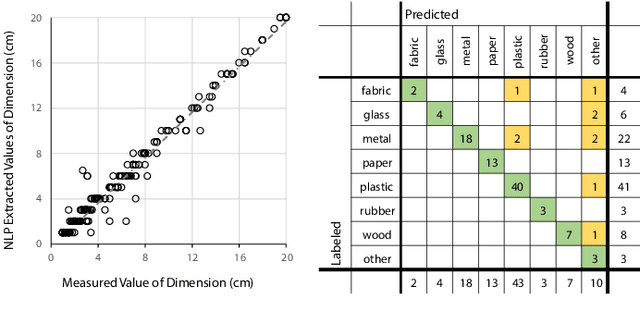
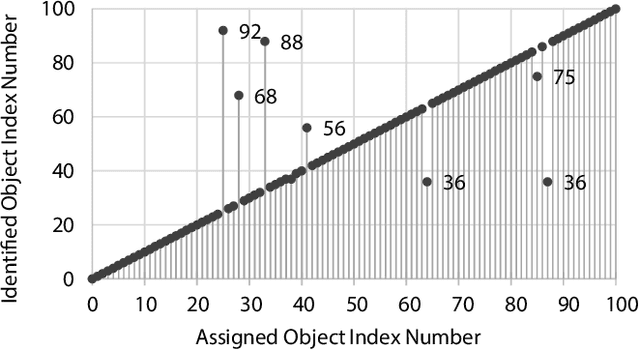
Humans can determine a proper strategy to grasp an object according to the measured physical attributes or the prior knowledge of the object. This paper proposes an approach to determining the strategy of dexterous grasping by using an anthropomorphic robotic hand simply based on a label or a description of an object. Object attributes are parsed from natural-language descriptions and augmented with an object knowledge base that is scraped from retailer websites. A novel metric named joint probability distance is defined to measure distance between object attributes. The probability distribution of grasp types for the given object is learned using a deep neural network which takes in object features as input. The action of the multi-fingered hand with redundant degrees of freedom (DoF) is controlled by a linear inverse-kinematics model of grasp topology and scales. The grasping strategy generated by the proposed approach is evaluated both by simulation and execution on a Sawyer robot with an AR10 robotic hand.