 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProspective Learning: Back to the Future
Jan 19, 2022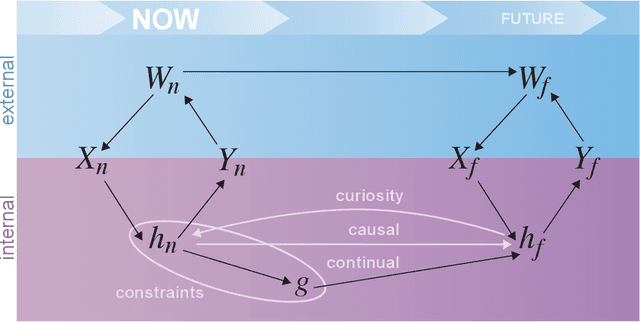

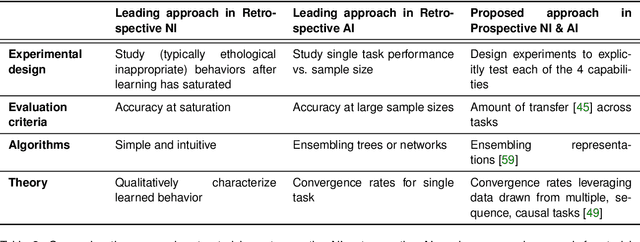
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
ABCD: A Graph Framework to Convert Complex Sentences to a Covering Set of Simple Sentences
Jun 22, 2021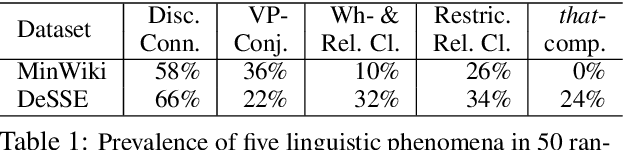
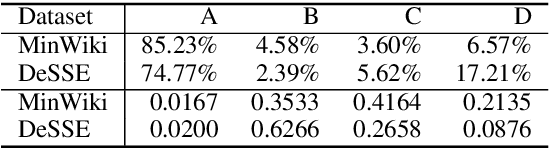
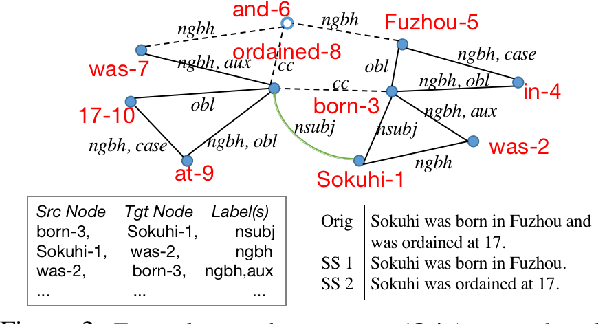
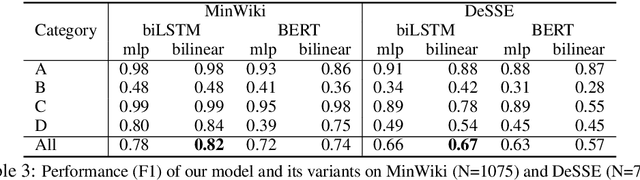
Atomic clauses are fundamental text units for understanding complex sentences. Identifying the atomic sentences within complex sentences is important for applications such as summarization, argument mining, discourse analysis, discourse parsing, and question answering. Previous work mainly relies on rule-based methods dependent on parsing. We propose a new task to decompose each complex sentence into simple sentences derived from the tensed clauses in the source, and a novel problem formulation as a graph edit task. Our neural model learns to Accept, Break, Copy or Drop elements of a graph that combines word adjacency and grammatical dependencies. The full processing pipeline includes modules for graph construction, graph editing, and sentence generation from the output graph. We introduce DeSSE, a new dataset designed to train and evaluate complex sentence decomposition, and MinWiki, a subset of MinWikiSplit. ABCD achieves comparable performance as two parsing baselines on MinWiki. On DeSSE, which has a more even balance of complex sentence types, our model achieves higher accuracy on the number of atomic sentences than an encoder-decoder baseline. Results include a detailed error analysis.
Personalized Keyphrase Detection using Speaker and Environment Information
Apr 28, 2021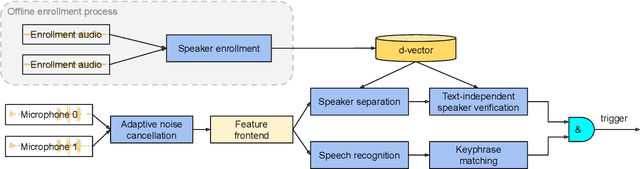
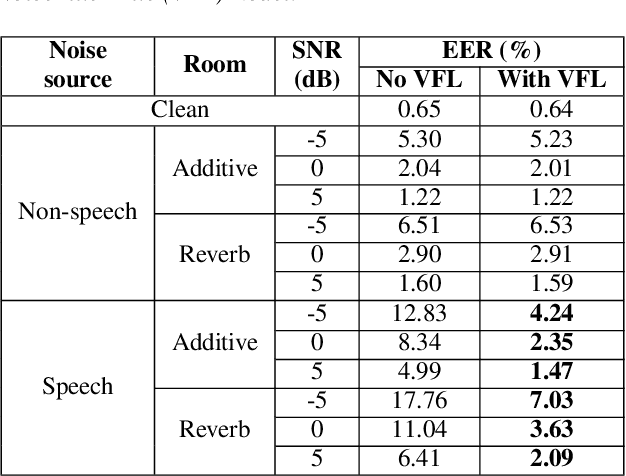
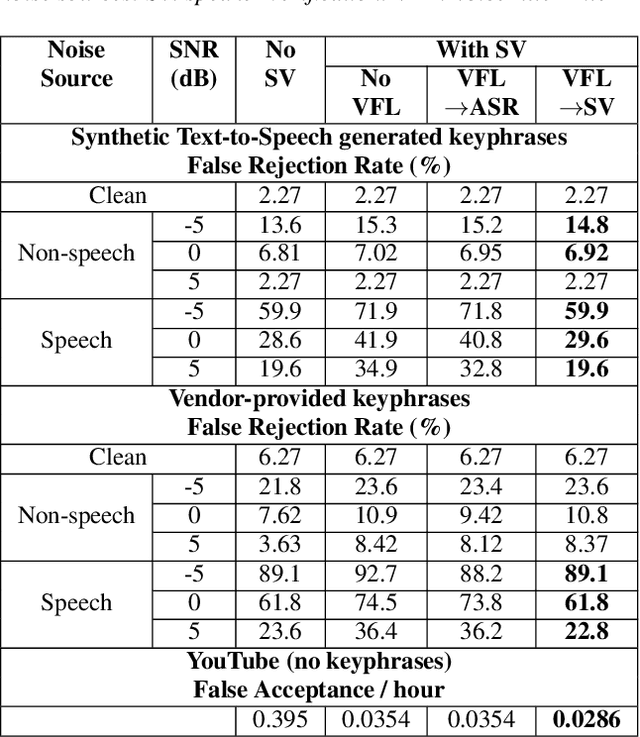
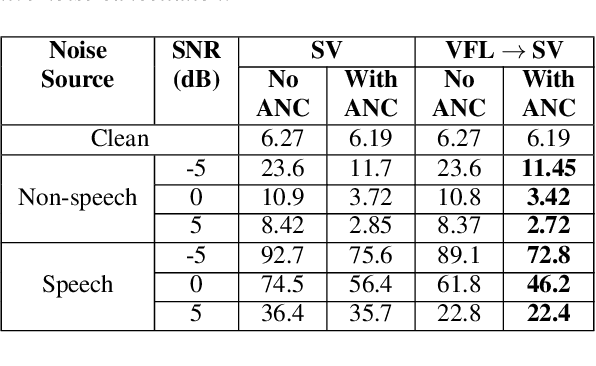
In this paper, we introduce a streaming keyphrase detection system that can be easily customized to accurately detect any phrase composed of words from a large vocabulary. The system is implemented with an end-to-end trained automatic speech recognition (ASR) model and a text-independent speaker verification model. To address the challenge of detecting these keyphrases under various noisy conditions, a speaker separation model is added to the feature frontend of the speaker verification model, and an adaptive noise cancellation (ANC) algorithm is included to exploit cross-microphone noise coherence. Our experiments show that the text-independent speaker verification model largely reduces the false triggering rate of the keyphrase detection, while the speaker separation model and adaptive noise cancellation largely reduce false rejections.
Unitary Approximate Message Passing for Sparse Bayesian Learning
Jan 25, 2021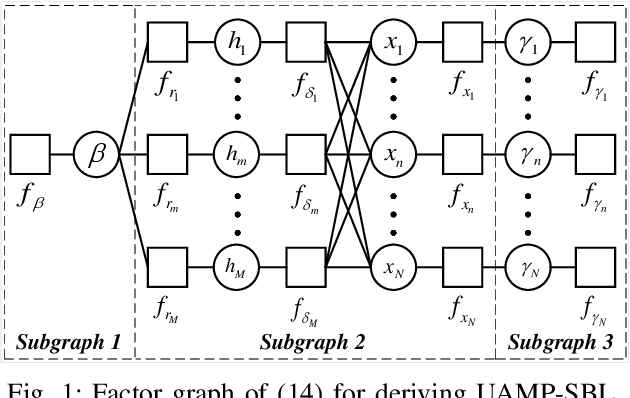
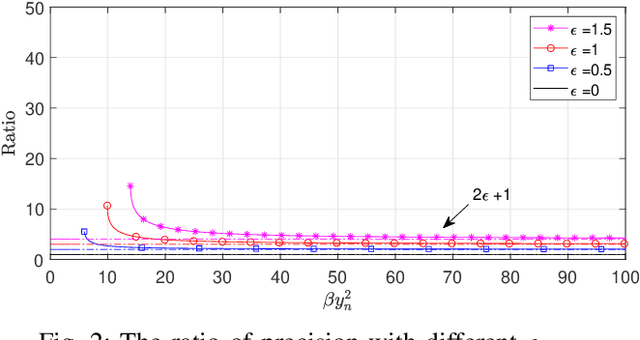
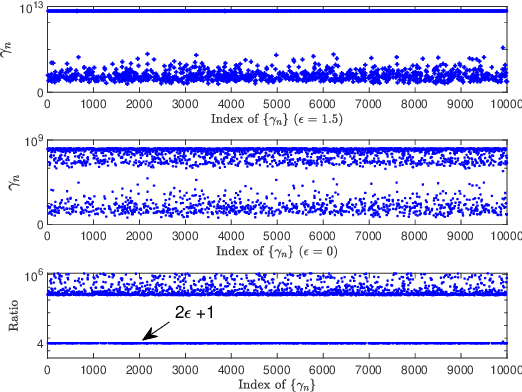
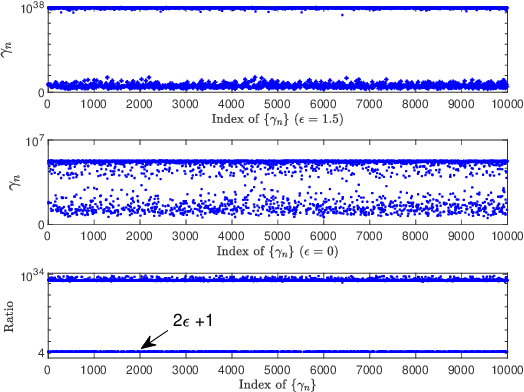
Sparse Bayesian learning (SBL) can be implemented with low complexity based on the approximate message passing (AMP) algorithm. However, it is vulnerable to 'difficult' measurement matrices, which may cause AMP to diverge. Damped AMP has been used for SBL to alleviate the problem at the cost of reducing convergence speed. In this work, we propose a new SBL algorithm based on structured variational inference, leveraging AMP with a unitary transformation (UAMP). Both single measurement vector and multiple measurement vector problems are investigated. It is shown that, compared to state-of-the-art AMP-based SBL algorithms, the proposed UAMPSBL is more robust and efficient, leading to remarkably better performance.
Robotic Knee Tracking Control to Mimic the Intact Human Knee Profile Based on Actor-critic Reinforcement Learning
Jan 22, 2021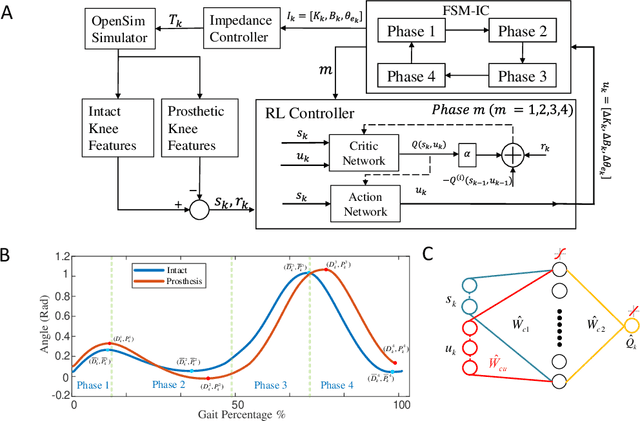
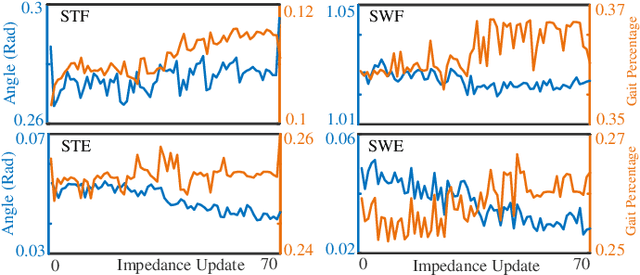
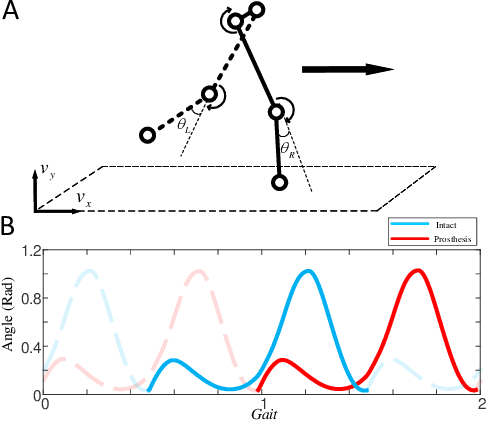
We address a state-of-the-art reinforcement learning (RL) control approach to automatically configure robotic prosthesis impedance parameters to enable end-to-end, continuous locomotion intended for transfemoral amputee subjects. Specifically, our actor-critic based RL provides tracking control of a robotic knee prosthesis to mimic the intact knee profile. This is a significant advance from our previous RL based automatic tuning of prosthesis control parameters which have centered on regulation control with a designer prescribed robotic knee profile as the target. In addition to presenting the complete tracking control algorithm based on direct heuristic dynamic programming (dHDP), we provide an analytical framework for the tracking controller with constrained inputs. We show that our proposed tracking control possesses several important properties, such as weight convergence of the learning networks, Bellman (sub)optimality of the cost-to-go value function and control input, and practical stability of the human-robot system under input constraint. We further provide a systematic simulation of the proposed tracking control using a realistic human-robot system simulator, the OpenSim, to emulate how the dHDP enables level ground walking, walking on different terrains and at different paces. These results show that our proposed dHDP based tracking control is not only theoretically suitable, but also practically useful.
Reinforcement Learning Enabled Automatic Impedance Control of a Robotic Knee Prosthesis to Mimic the Intact Knee Motion in a Co-Adapting Environment
Jan 10, 2021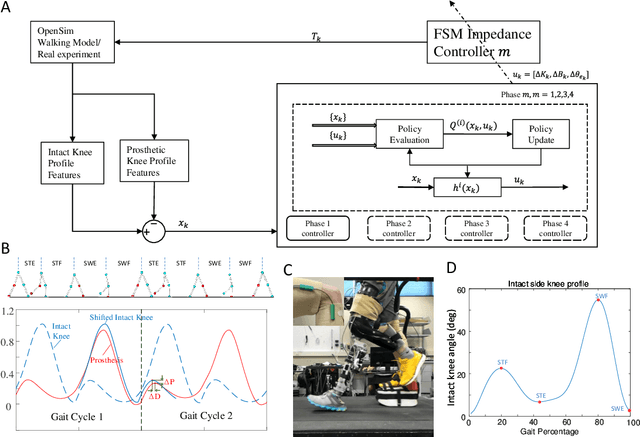
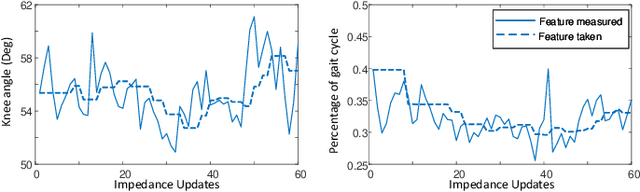
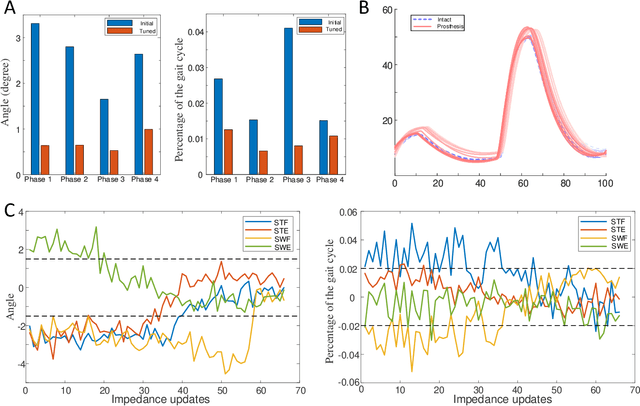
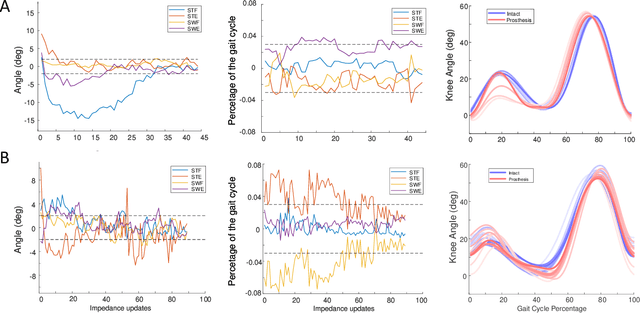
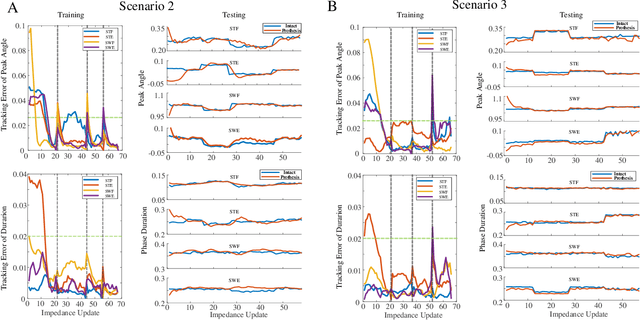
Automatically configuring a robotic prosthesis to fit its user's needs and physical conditions is a great technical challenge and a roadblock to the adoption of the technology. Previously, we have successfully developed reinforcement learning (RL) solutions toward addressing this issue. Yet, our designs were based on using a subjectively prescribed target motion profile for the robotic knee during level ground walking. This is not realistic for different users and for different locomotion tasks. In this study for the first time, we investigated the feasibility of RL enabled automatic configuration of impedance parameter settings for a robotic knee to mimic the intact knee motion in a co-adapting environment. We successfully achieved such tracking control by an online policy iteration. We demonstrated our results in both OpenSim simulations and two able-bodied (AB) subjects.
Assessing Post-Disaster Damage from Satellite Imagery using Semi-Supervised Learning Techniques
Nov 24, 2020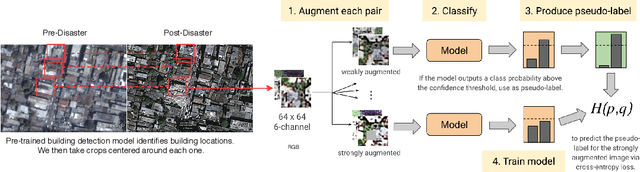
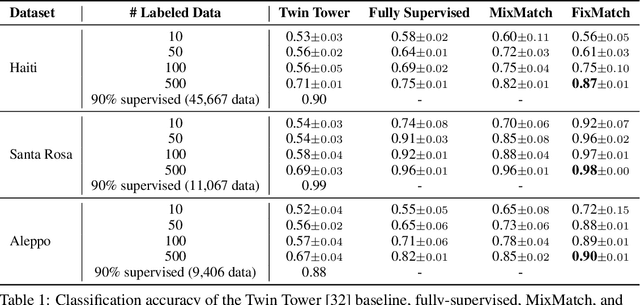
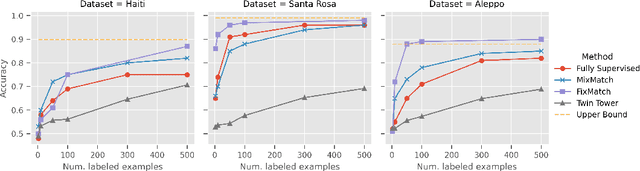
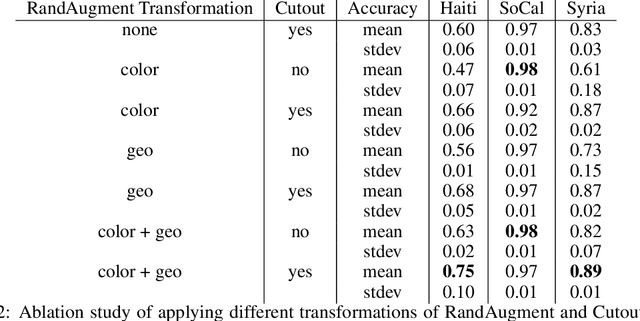
To respond to disasters such as earthquakes, wildfires, and armed conflicts, humanitarian organizations require accurate and timely data in the form of damage assessments, which indicate what buildings and population centers have been most affected. Recent research combines machine learning with remote sensing to automatically extract such information from satellite imagery, reducing manual labor and turn-around time. A major impediment to using machine learning methods in real disaster response scenarios is the difficulty of obtaining a sufficient amount of labeled data to train a model for an unfolding disaster. This paper shows a novel application of semi-supervised learning (SSL) to train models for damage assessment with a minimal amount of labeled data and large amount of unlabeled data. We compare the performance of state-of-the-art SSL methods, including MixMatch and FixMatch, to a supervised baseline for the 2010 Haiti earthquake, 2017 Santa Rosa wildfire, and 2016 armed conflict in Syria. We show how models trained with SSL methods can reach fully supervised performance despite using only a fraction of labeled data and identify areas for further improvements.
Dimensionality reduction, regularization, and generalization in overparameterized regressions
Nov 23, 2020
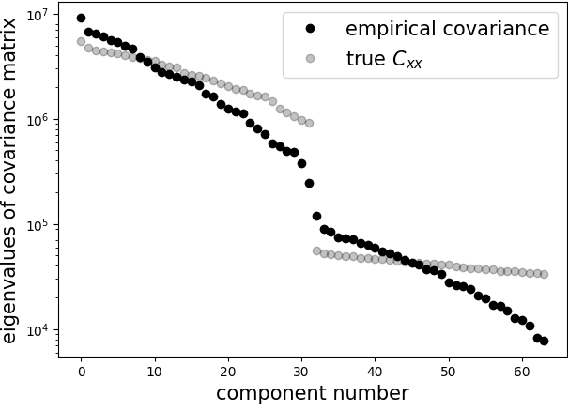
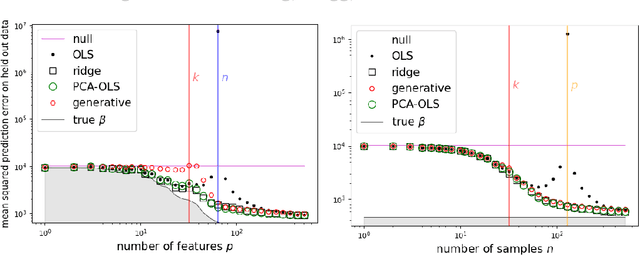
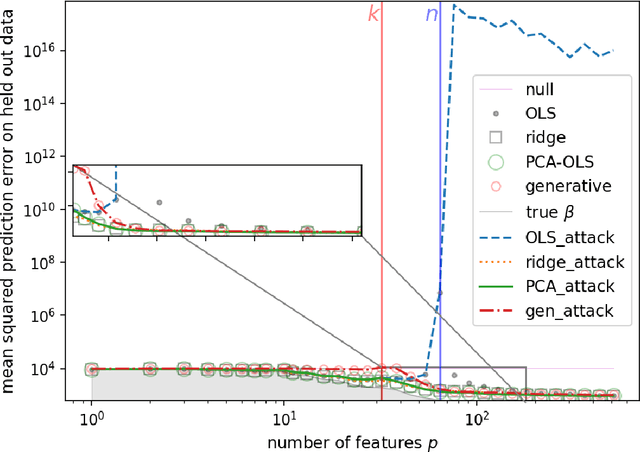
Overparameterization in deep learning is powerful: Very large models fit the training data perfectly and yet generalize well. This realization brought back the study of linear models for regression, including ordinary least squares (OLS), which, like deep learning, shows a "double descent" behavior. This involves two features: (1) The risk (out-of-sample prediction error) can grow arbitrarily when the number of samples $n$ approaches the number of parameters $p$, and (2) the risk decreases with $p$ at $p>n$, sometimes achieving a lower value than the lowest risk at $p<n$. The divergence of the risk for OLS at $p\approx n$ is related to the condition number of the empirical covariance in the feature set. For this reason, it can be avoided with regularization. In this work we show that it can also be avoided with a PCA-based dimensionality reduction. We provide a finite upper bound for the risk of the PCA-based estimator. This result is in contrast to recent work that shows that a different form of dimensionality reduction -- one based on the population covariance instead of the empirical covariance -- does not avoid the divergence. We connect these results to an analysis of adversarial attacks, which become more effective as they raise the condition number of the empirical covariance of the features. We show that OLS is arbitrarily susceptible to data-poisoning attacks in the overparameterized regime -- unlike the underparameterized regime -- and that regularization and dimensionality reduction improve the robustness.
A Data-Driven Reinforcement Learning Solution Framework for Optimal and Adaptive Personalization of a Hip Exoskeleton
Nov 11, 2020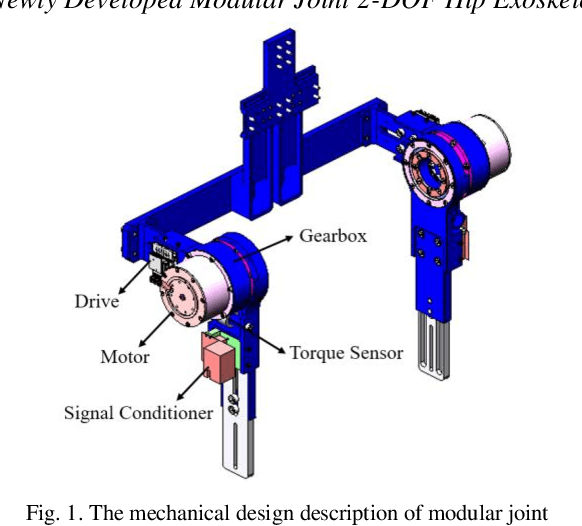
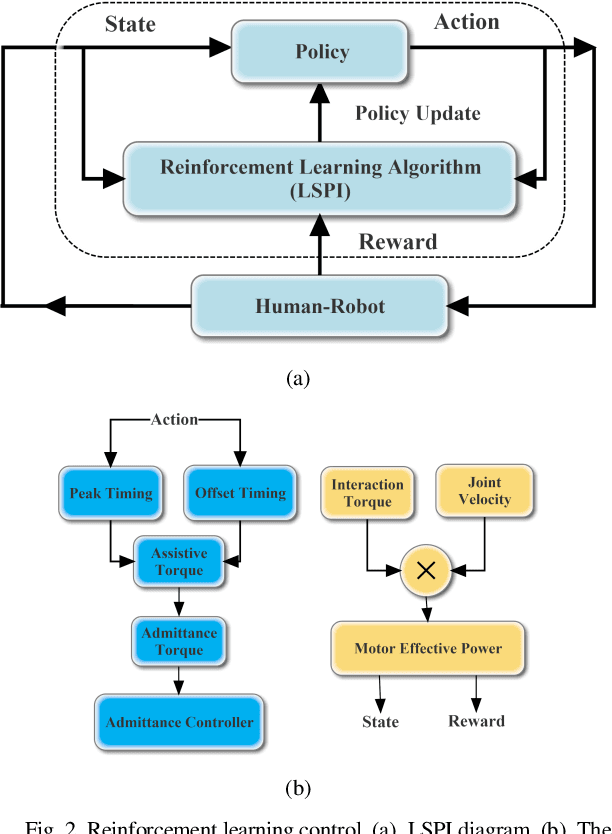
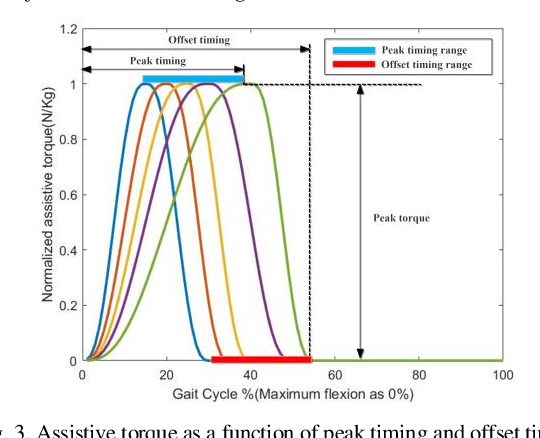
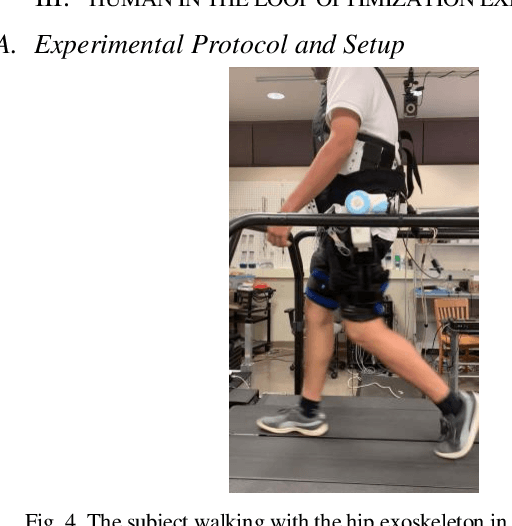
Robotic exoskeletons are exciting technologies for augmenting human mobility. However, designing such a device for seamless integration with the human user and to assist human movement still is a major challenge. This paper aims at developing a novel data-driven solution framework based on reinforcement learning (RL), without first modeling the human-robot dynamics, to provide optimal and adaptive personalized torque assistance for reducing human efforts during walking. Our automatic personalization solution framework includes the assistive torque profile with two control timing parameters (peak and offset timings), the least square policy iteration (LSPI) for learning the parameter tuning policy, and a cost function based on transferred work ratio. The proposed controller was successfully validated on a healthy human subject to assist unilateral hip extension in walking. The results showed that the optimal and adaptive RL controller as a new approach was feasible for tuning assistive torque profile of the hip exoskeleton that coordinated with human actions and reduced activation level of hip extensor muscle in human.
Reinforcement Learning Control of Robotic Knee with Human in the Loop by Flexible Policy Iteration
Jun 16, 2020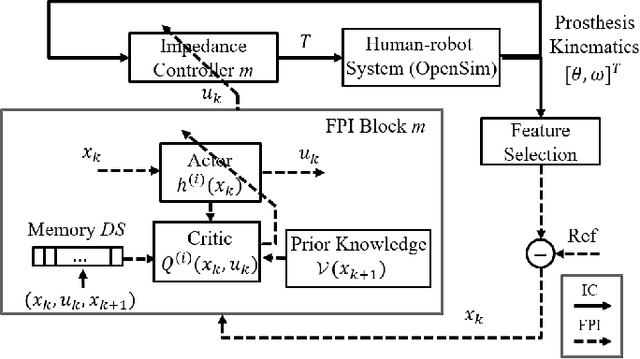
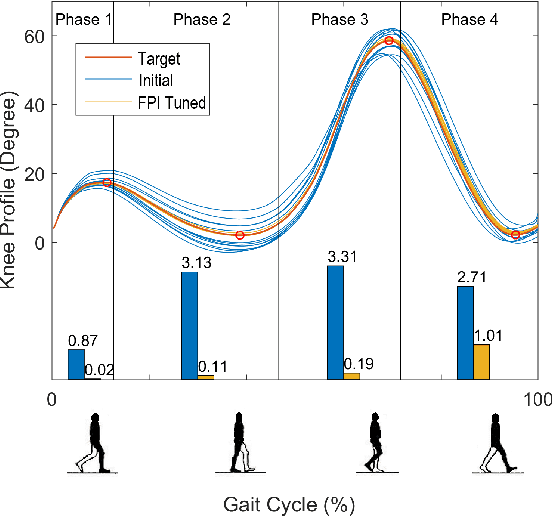
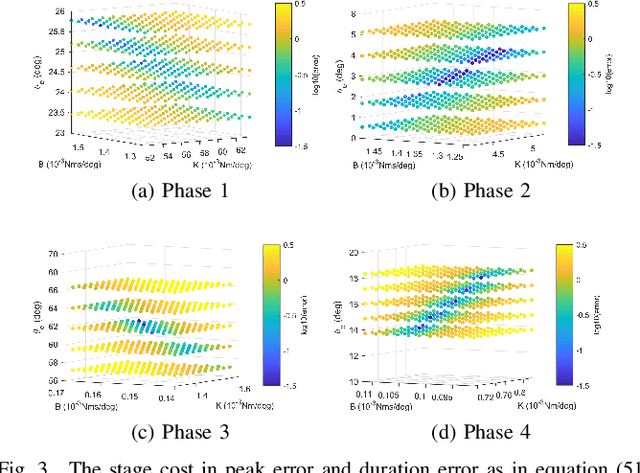
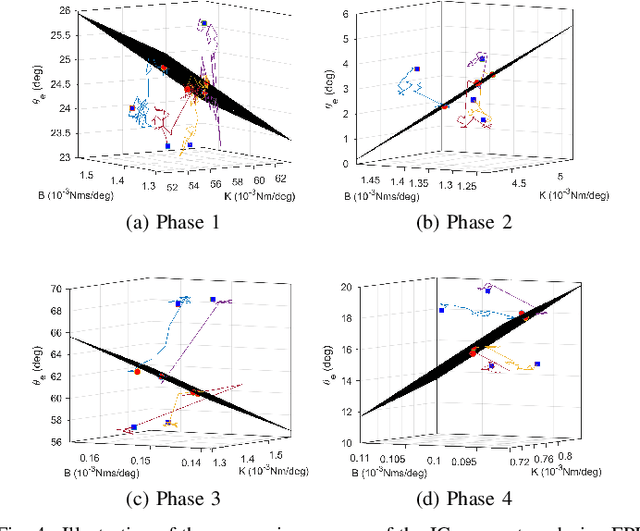
This study is motivated by a new class of challenging control problems described by automatic tuning of robotic knee control parameters with human in the loop. In addition to inter-person and intra-person variances inherent in such human-robot systems, human user safety and stability, as well as data and time efficiency should also be taken into design consideration. Here by data and time efficiency we mean learning and adaptation of device configurations takes place within countable gait cycles or within minutes of time. As solutions to this problem is not readily available, we therefore propose a new policy iteration based adaptive dynamic programming algorithm, namely the flexible policy iteration (FPI). We show that the FPI solves the control parameters via (weighted) least-squares while it incorporates data flexibly and utilizes prior knowledge. We provide analyses on stable control policies, non-increasing and converging value functions to Bellman optimality, and error bounds on the iterative value functions subject to approximation errors. We extensively evaluated the performance of FPI in a well-established locomotion simulator, the OpenSim under realistic conditions. By inspecting FPI with three other comparable algorithms, we demonstrate the FPI as a feasible data and time efficient design approach for adapting the control parameters of the prosthetic knee to co-adapt with the human user who also places control on the prosthesis. As the proposed FPI algorithm does not require stringent constraints or peculiar assumptions, we expect this reinforcement learning controller can potentially be applied to other challenging adaptive optimal control problems.