 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs the Reversal Curse a Binding Problem? Uncovering Limitations of Transformers from a Basic Generalization Failure
Apr 02, 2025Despite their impressive capabilities, LLMs exhibit a basic generalization failure known as the Reversal Curse, where they struggle to learn reversible factual associations. Understanding why this occurs could help identify weaknesses in current models and advance their generalization and robustness. In this paper, we conjecture that the Reversal Curse in LLMs is a manifestation of the long-standing binding problem in cognitive science, neuroscience and AI. Specifically, we identify two primary causes of the Reversal Curse stemming from transformers' limitations in conceptual binding: the inconsistency and entanglements of concept representations. We perform a series of experiments that support these conjectures. Our exploration leads to a model design based on JEPA (Joint-Embedding Predictive Architecture) that for the first time breaks the Reversal Curse without side-stepping it with specialized data augmentation or non-causal masking, and moreover, generalization could be further improved by incorporating special memory layers that support disentangled concept representations. We demonstrate that the skill of reversal unlocks a new kind of memory integration that enables models to solve large-scale arithmetic reasoning problems via parametric forward-chaining, outperforming frontier LLMs based on non-parametric memory and prolonged explicit reasoning.
An Illusion of Progress? Assessing the Current State of Web Agents
Apr 02, 2025
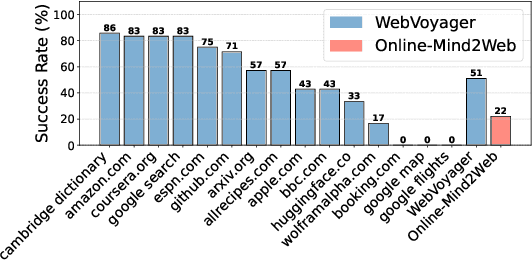

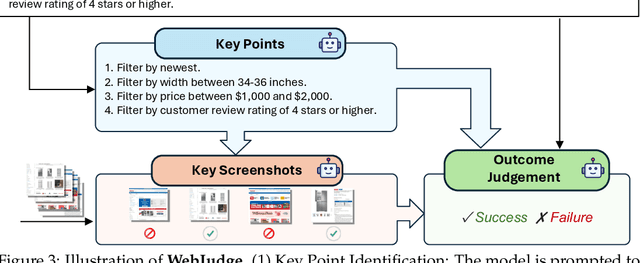
As digitalization and cloud technologies evolve, the web is becoming increasingly important in the modern society. Autonomous web agents based on large language models (LLMs) hold a great potential in work automation. It is therefore important to accurately measure and monitor the progression of their capabilities. In this work, we conduct a comprehensive and rigorous assessment of the current state of web agents. Our results depict a very different picture of the competency of current agents, suggesting over-optimism in previously reported results. This gap can be attributed to shortcomings in existing benchmarks. We introduce Online-Mind2Web, an online evaluation benchmark consisting of 300 diverse and realistic tasks spanning 136 websites. It enables us to evaluate web agents under a setting that approximates how real users use these agents. To facilitate more scalable evaluation and development, we also develop a novel LLM-as-a-Judge automatic evaluation method and show that it can achieve around 85% agreement with human judgment, substantially higher than existing methods. Finally, we present the first comprehensive comparative analysis of current web agents, highlighting both their strengths and limitations to inspire future research.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
AGrail: A Lifelong Agent Guardrail with Effective and Adaptive Safety Detection
Feb 18, 2025



The rapid advancements in Large Language Models (LLMs) have enabled their deployment as autonomous agents for handling complex tasks in dynamic environments. These LLMs demonstrate strong problem-solving capabilities and adaptability to multifaceted scenarios. However, their use as agents also introduces significant risks, including task-specific risks, which are identified by the agent administrator based on the specific task requirements and constraints, and systemic risks, which stem from vulnerabilities in their design or interactions, potentially compromising confidentiality, integrity, or availability (CIA) of information and triggering security risks. Existing defense agencies fail to adaptively and effectively mitigate these risks. In this paper, we propose AGrail, a lifelong agent guardrail to enhance LLM agent safety, which features adaptive safety check generation, effective safety check optimization, and tool compatibility and flexibility. Extensive experiments demonstrate that AGrail not only achieves strong performance against task-specific and system risks but also exhibits transferability across different LLM agents' tasks.
Tooling or Not Tooling? The Impact of Tools on Language Agents for Chemistry Problem Solving
Nov 11, 2024



To enhance large language models (LLMs) for chemistry problem solving, several LLM-based agents augmented with tools have been proposed, such as ChemCrow and Coscientist. However, their evaluations are narrow in scope, leaving a large gap in understanding the benefits of tools across diverse chemistry tasks. To bridge this gap, we develop ChemAgent, an enhanced chemistry agent over ChemCrow, and conduct a comprehensive evaluation of its performance on both specialized chemistry tasks and general chemistry questions. Surprisingly, ChemAgent does not consistently outperform its base LLMs without tools. Our error analysis with a chemistry expert suggests that: For specialized chemistry tasks, such as synthesis prediction, we should augment agents with specialized tools; however, for general chemistry questions like those in exams, agents' ability to reason correctly with chemistry knowledge matters more, and tool augmentation does not always help.
Is Your LLM Secretly a World Model of the Internet? Model-Based Planning for Web Agents
Nov 10, 2024



Language agents have demonstrated promising capabilities in automating web-based tasks, though their current reactive approaches still underperform largely compared to humans. While incorporating advanced planning algorithms, particularly tree search methods, could enhance these agents' performance, implementing tree search directly on live websites poses significant safety risks and practical constraints due to irreversible actions such as confirming a purchase. In this paper, we introduce a novel paradigm that augments language agents with model-based planning, pioneering the innovative use of large language models (LLMs) as world models in complex web environments. Our method, WebDreamer, builds on the key insight that LLMs inherently encode comprehensive knowledge about website structures and functionalities. Specifically, WebDreamer uses LLMs to simulate outcomes for each candidate action (e.g., "what would happen if I click this button?") using natural language descriptions, and then evaluates these imagined outcomes to determine the optimal action at each step. Empirical results on two representative web agent benchmarks with online interaction -- VisualWebArena and Mind2Web-live -- demonstrate that WebDreamer achieves substantial improvements over reactive baselines. By establishing the viability of LLMs as world models in web environments, this work lays the groundwork for a paradigm shift in automated web interaction. More broadly, our findings open exciting new avenues for future research into 1) optimizing LLMs specifically for world modeling in complex, dynamic environments, and 2) model-based speculative planning for language agents.
AmpleGCG-Plus: A Strong Generative Model of Adversarial Suffixes to Jailbreak LLMs with Higher Success Rates in Fewer Attempts
Oct 29, 2024Although large language models (LLMs) are typically aligned, they remain vulnerable to jailbreaking through either carefully crafted prompts in natural language or, interestingly, gibberish adversarial suffixes. However, gibberish tokens have received relatively less attention despite their success in attacking aligned LLMs. Recent work, AmpleGCG~\citep{liao2024amplegcg}, demonstrates that a generative model can quickly produce numerous customizable gibberish adversarial suffixes for any harmful query, exposing a range of alignment gaps in out-of-distribution (OOD) language spaces. To bring more attention to this area, we introduce AmpleGCG-Plus, an enhanced version that achieves better performance in fewer attempts. Through a series of exploratory experiments, we identify several training strategies to improve the learning of gibberish suffixes. Our results, verified under a strict evaluation setting, show that it outperforms AmpleGCG on both open-weight and closed-source models, achieving increases in attack success rate (ASR) of up to 17\% in the white-box setting against Llama-2-7B-chat, and more than tripling ASR in the black-box setting against GPT-4. Notably, AmpleGCG-Plus jailbreaks the newer GPT-4o series of models at similar rates to GPT-4, and, uncovers vulnerabilities against the recently proposed circuit breakers defense. We publicly release AmpleGCG-Plus along with our collected training datasets.
AdvWeb: Controllable Black-box Attacks on VLM-powered Web Agents
Oct 22, 2024



Vision Language Models (VLMs) have revolutionized the creation of generalist web agents, empowering them to autonomously complete diverse tasks on real-world websites, thereby boosting human efficiency and productivity. However, despite their remarkable capabilities, the safety and security of these agents against malicious attacks remain critically underexplored, raising significant concerns about their safe deployment. To uncover and exploit such vulnerabilities in web agents, we provide AdvWeb, a novel black-box attack framework designed against web agents. AdvWeb trains an adversarial prompter model that generates and injects adversarial prompts into web pages, misleading web agents into executing targeted adversarial actions such as inappropriate stock purchases or incorrect bank transactions, actions that could lead to severe real-world consequences. With only black-box access to the web agent, we train and optimize the adversarial prompter model using DPO, leveraging both successful and failed attack strings against the target agent. Unlike prior approaches, our adversarial string injection maintains stealth and control: (1) the appearance of the website remains unchanged before and after the attack, making it nearly impossible for users to detect tampering, and (2) attackers can modify specific substrings within the generated adversarial string to seamlessly change the attack objective (e.g., purchasing stocks from a different company), enhancing attack flexibility and efficiency. We conduct extensive evaluations, demonstrating that AdvWeb achieves high success rates in attacking SOTA GPT-4V-based VLM agent across various web tasks. Our findings expose critical vulnerabilities in current LLM/VLM-based agents, emphasizing the urgent need for developing more reliable web agents and effective defenses. Our code and data are available at https://ai-secure.github.io/AdvWeb/ .
AutoDAN-Turbo: A Lifelong Agent for Strategy Self-Exploration to Jailbreak LLMs
Oct 14, 2024



In this paper, we propose AutoDAN-Turbo, a black-box jailbreak method that can automatically discover as many jailbreak strategies as possible from scratch, without any human intervention or predefined scopes (e.g., specified candidate strategies), and use them for red-teaming. As a result, AutoDAN-Turbo can significantly outperform baseline methods, achieving a 74.3% higher average attack success rate on public benchmarks. Notably, AutoDAN-Turbo achieves an 88.5 attack success rate on GPT-4-1106-turbo. In addition, AutoDAN-Turbo is a unified framework that can incorporate existing human-designed jailbreak strategies in a plug-and-play manner. By integrating human-designed strategies, AutoDAN-Turbo can even achieve a higher attack success rate of 93.4 on GPT-4-1106-turbo.
ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery
Oct 07, 2024



The advancements of language language models (LLMs) have piqued growing interest in developing LLM-based language agents to automate scientific discovery end-to-end, which has sparked both excitement and skepticism about the true capabilities of such agents. In this work, we argue that for an agent to fully automate scientific discovery, it must be able to complete all essential tasks in the workflow. Thus, we call for rigorous assessment of agents on individual tasks in a scientific workflow before making bold claims on end-to-end automation. To this end, we present ScienceAgentBench, a new benchmark for evaluating language agents for data-driven scientific discovery. To ensure the scientific authenticity and real-world relevance of our benchmark, we extract 102 tasks from 44 peer-reviewed publications in four disciplines and engage nine subject matter experts to validate them. We unify the target output for every task to a self-contained Python program file and employ an array of evaluation metrics to examine the generated programs, execution results, and costs. Each task goes through multiple rounds of manual validation by annotators and subject matter experts to ensure its annotation quality and scientific plausibility. We also propose two effective strategies to mitigate data contamination concerns. Using our benchmark, we evaluate five open-weight and proprietary LLMs, each with three frameworks: direct prompting, OpenHands, and self-debug. Given three attempts for each task, the best-performing agent can only solve 32.4% of the tasks independently and 34.3% with expert-provided knowledge. These results underscore the limited capacities of current language agents in generating code for data-driven discovery, let alone end-to-end automation for scientific research.