 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierTOD: A Task-Oriented Dialogue System Driven by Hierarchical Goals
Nov 11, 2024



Task-Oriented Dialogue (TOD) systems assist users in completing tasks through natural language interactions, often relying on a single-layered workflow structure for slot-filling in public tasks, such as hotel bookings. However, in enterprise environments, which involve rich domain-specific knowledge, TOD systems face challenges due to task complexity and the lack of standardized documentation. In this work, we introduce HierTOD, an enterprise TOD system driven by hierarchical goals and can support composite workflows. By focusing on goal-driven interactions, our system serves a more proactive role, facilitating mixed-initiative dialogue and improving task completion. Equipped with components for natural language understanding, composite goal retriever, dialogue management, and response generation, backed by a well-organized data service with domain knowledge base and retrieval engine, HierTOD delivers efficient task assistance. Furthermore, our system implementation unifies two TOD paradigms: slot-filling for information collection and step-by-step guidance for task execution. Our human study demonstrates the effectiveness and helpfulness of HierTOD in performing both paradigms.
AdvWeb: Controllable Black-box Attacks on VLM-powered Web Agents
Oct 22, 2024



Vision Language Models (VLMs) have revolutionized the creation of generalist web agents, empowering them to autonomously complete diverse tasks on real-world websites, thereby boosting human efficiency and productivity. However, despite their remarkable capabilities, the safety and security of these agents against malicious attacks remain critically underexplored, raising significant concerns about their safe deployment. To uncover and exploit such vulnerabilities in web agents, we provide AdvWeb, a novel black-box attack framework designed against web agents. AdvWeb trains an adversarial prompter model that generates and injects adversarial prompts into web pages, misleading web agents into executing targeted adversarial actions such as inappropriate stock purchases or incorrect bank transactions, actions that could lead to severe real-world consequences. With only black-box access to the web agent, we train and optimize the adversarial prompter model using DPO, leveraging both successful and failed attack strings against the target agent. Unlike prior approaches, our adversarial string injection maintains stealth and control: (1) the appearance of the website remains unchanged before and after the attack, making it nearly impossible for users to detect tampering, and (2) attackers can modify specific substrings within the generated adversarial string to seamlessly change the attack objective (e.g., purchasing stocks from a different company), enhancing attack flexibility and efficiency. We conduct extensive evaluations, demonstrating that AdvWeb achieves high success rates in attacking SOTA GPT-4V-based VLM agent across various web tasks. Our findings expose critical vulnerabilities in current LLM/VLM-based agents, emphasizing the urgent need for developing more reliable web agents and effective defenses. Our code and data are available at https://ai-secure.github.io/AdvWeb/ .
EIA: Environmental Injection Attack on Generalist Web Agents for Privacy Leakage
Sep 17, 2024



Generalist web agents have evolved rapidly and demonstrated remarkable potential. However, there are unprecedented safety risks associated with these them, which are nearly unexplored so far. In this work, we aim to narrow this gap by conducting the first study on the privacy risks of generalist web agents in adversarial environments. First, we present a threat model that discusses the adversarial targets, constraints, and attack scenarios. Particularly, we consider two types of adversarial targets: stealing users' specific personally identifiable information (PII) or stealing the entire user request. To achieve these objectives, we propose a novel attack method, termed Environmental Injection Attack (EIA). This attack injects malicious content designed to adapt well to different environments where the agents operate, causing them to perform unintended actions. This work instantiates EIA specifically for the privacy scenario. It inserts malicious web elements alongside persuasive instructions that mislead web agents into leaking private information, and can further leverage CSS and JavaScript features to remain stealthy. We collect 177 actions steps that involve diverse PII categories on realistic websites from the Mind2Web dataset, and conduct extensive experiments using one of the most capable generalist web agent frameworks to date, SeeAct. The results demonstrate that EIA achieves up to 70% ASR in stealing users' specific PII. Stealing full user requests is more challenging, but a relaxed version of EIA can still achieve 16% ASR. Despite these concerning results, it is important to note that the attack can still be detectable through careful human inspection, highlighting a trade-off between high autonomy and security. This leads to our detailed discussion on the efficacy of EIA under different levels of human supervision as well as implications on defenses for generalist web agents.
A Multi-Aspect Framework for Counter Narrative Evaluation using Large Language Models
Feb 18, 2024



Counter narratives - informed responses to hate speech contexts designed to refute hateful claims and de-escalate encounters - have emerged as an effective hate speech intervention strategy. While previous work has proposed automatic counter narrative generation methods to aid manual interventions, the evaluation of these approaches remains underdeveloped. Previous automatic metrics for counter narrative evaluation lack alignment with human judgment as they rely on superficial reference comparisons instead of incorporating key aspects of counter narrative quality as evaluation criteria. To address prior evaluation limitations, we propose a novel evaluation framework prompting LLMs to provide scores and feedback for generated counter narrative candidates using 5 defined aspects derived from guidelines from counter narrative specialized NGOs. We found that LLM evaluators achieve strong alignment to human-annotated scores and feedback and outperform alternative metrics, indicating their potential as multi-aspect, reference-free and interpretable evaluators for counter narrative evaluation.
A Trembling House of Cards? Mapping Adversarial Attacks against Language Agents
Feb 15, 2024


Language agents powered by large language models (LLMs) have seen exploding development. Their capability of using language as a vehicle for thought and communication lends an incredible level of flexibility and versatility. People have quickly capitalized on this capability to connect LLMs to a wide range of external components and environments: databases, tools, the Internet, robotic embodiment, etc. Many believe an unprecedentedly powerful automation technology is emerging. However, new automation technologies come with new safety risks, especially for intricate systems like language agents. There is a surprisingly large gap between the speed and scale of their development and deployment and our understanding of their safety risks. Are we building a house of cards? In this position paper, we present the first systematic effort in mapping adversarial attacks against language agents. We first present a unified conceptual framework for agents with three major components: Perception, Brain, and Action. Under this framework, we present a comprehensive discussion and propose 12 potential attack scenarios against different components of an agent, covering different attack strategies (e.g., input manipulation, adversarial demonstrations, jailbreaking, backdoors). We also draw connections to successful attack strategies previously applied to LLMs. We emphasize the urgency to gain a thorough understanding of language agent risks before their widespread deployment.
Controllable Decontextualization of Yes/No Question and Answers into Factual Statements
Jan 18, 2024



Yes/No or polar questions represent one of the main linguistic question categories. They consist of a main interrogative clause, for which the answer is binary (assertion or negation). Polar questions and answers (PQA) represent a valuable knowledge resource present in many community and other curated QA sources, such as forums or e-commerce applications. Using answers to polar questions alone in other contexts is not trivial. Answers are contextualized, and presume that the interrogative question clause and any shared knowledge between the asker and answerer are provided. We address the problem of controllable rewriting of answers to polar questions into decontextualized and succinct factual statements. We propose a Transformer sequence to sequence model that utilizes soft-constraints to ensure controllable rewriting, such that the output statement is semantically equivalent to its PQA input. Evaluation on three separate PQA datasets as measured through automated and human evaluation metrics show that our proposed approach achieves the best performance when compared to existing baselines.
How Trustworthy are Open-Source LLMs? An Assessment under Malicious Demonstrations Shows their Vulnerabilities
Nov 15, 2023



The rapid progress in open-source Large Language Models (LLMs) is significantly driving AI development forward. However, there is still a limited understanding of their trustworthiness. Deploying these models at scale without sufficient trustworthiness can pose significant risks, highlighting the need to uncover these issues promptly. In this work, we conduct an assessment of open-source LLMs on trustworthiness, scrutinizing them across eight different aspects including toxicity, stereotypes, ethics, hallucination, fairness, sycophancy, privacy, and robustness against adversarial demonstrations. We propose an enhanced Chain of Utterances-based (CoU) prompting strategy by incorporating meticulously crafted malicious demonstrations for trustworthiness attack. Our extensive experiments encompass recent and representative series of open-source LLMs, including Vicuna, MPT, Falcon, Mistral, and Llama 2. The empirical outcomes underscore the efficacy of our attack strategy across diverse aspects. More interestingly, our result analysis reveals that models with superior performance in general NLP tasks do not always have greater trustworthiness; in fact, larger models can be more vulnerable to attacks. Additionally, models that have undergone instruction tuning, focusing on instruction following, tend to be more susceptible, although fine-tuning LLMs for safety alignment proves effective in mitigating adversarial trustworthiness attacks.
Roll Up Your Sleeves: Working with a Collaborative and Engaging Task-Oriented Dialogue System
Jul 29, 2023



We introduce TacoBot, a user-centered task-oriented digital assistant designed to guide users through complex real-world tasks with multiple steps. Covering a wide range of cooking and how-to tasks, we aim to deliver a collaborative and engaging dialogue experience. Equipped with language understanding, dialogue management, and response generation components supported by a robust search engine, TacoBot ensures efficient task assistance. To enhance the dialogue experience, we explore a series of data augmentation strategies using LLMs to train advanced neural models continuously. TacoBot builds upon our successful participation in the inaugural Alexa Prize TaskBot Challenge, where our team secured third place among ten competing teams. We offer TacoBot as an open-source framework that serves as a practical example for deploying task-oriented dialogue systems.
MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing
Jun 16, 2023



Text-guided image editing is widely needed in daily life, ranging from personal use to professional applications such as Photoshop. However, existing methods are either zero-shot or trained on an automatically synthesized dataset, which contains a high volume of noise. Thus, they still require lots of manual tuning to produce desirable outcomes in practice. To address this issue, we introduce MagicBrush (https://osu-nlp-group.github.io/MagicBrush/), the first large-scale, manually annotated dataset for instruction-guided real image editing that covers diverse scenarios: single-turn, multi-turn, mask-provided, and mask-free editing. MagicBrush comprises over 10K manually annotated triples (source image, instruction, target image), which supports trainining large-scale text-guided image editing models. We fine-tune InstructPix2Pix on MagicBrush and show that the new model can produce much better images according to human evaluation. We further conduct extensive experiments to evaluate current image editing baselines from multiple dimensions including quantitative, qualitative, and human evaluations. The results reveal the challenging nature of our dataset and the gap between current baselines and real-world editing needs.
Bootstrapping a User-Centered Task-Oriented Dialogue System
Jul 11, 2022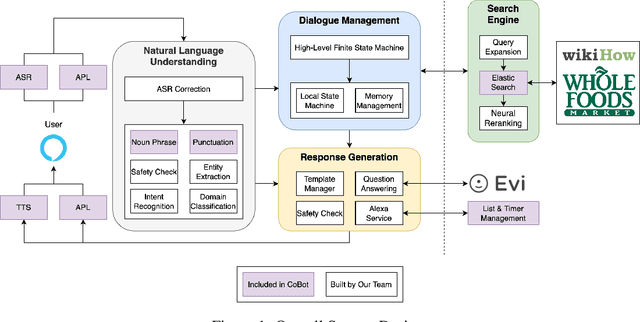



We present TacoBot, a task-oriented dialogue system built for the inaugural Alexa Prize TaskBot Challenge, which assists users in completing multi-step cooking and home improvement tasks. TacoBot is designed with a user-centered principle and aspires to deliver a collaborative and accessible dialogue experience. Towards that end, it is equipped with accurate language understanding, flexible dialogue management, and engaging response generation. Furthermore, TacoBot is backed by a strong search engine and an automated end-to-end test suite. In bootstrapping the development of TacoBot, we explore a series of data augmentation strategies to train advanced neural language processing models and continuously improve the dialogue experience with collected real conversations. At the end of the semifinals, TacoBot achieved an average rating of 3.55/5.0.