 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Imbalanced Noisy Data by Preventing Bias in Sample Selection
Feb 17, 2024



Learning with noisy labels has gained increasing attention because the inevitable imperfect labels in real-world scenarios can substantially hurt the deep model performance. Recent studies tend to regard low-loss samples as clean ones and discard high-loss ones to alleviate the negative impact of noisy labels. However, real-world datasets contain not only noisy labels but also class imbalance. The imbalance issue is prone to causing failure in the loss-based sample selection since the under-learning of tail classes also leans to produce high losses. To this end, we propose a simple yet effective method to address noisy labels in imbalanced datasets. Specifically, we propose Class-Balance-based sample Selection (CBS) to prevent the tail class samples from being neglected during training. We propose Confidence-based Sample Augmentation (CSA) for the chosen clean samples to enhance their reliability in the training process. To exploit selected noisy samples, we resort to prediction history to rectify labels of noisy samples. Moreover, we introduce the Average Confidence Margin (ACM) metric to measure the quality of corrected labels by leveraging the model's evolving training dynamics, thereby ensuring that low-quality corrected noisy samples are appropriately masked out. Lastly, consistency regularization is imposed on filtered label-corrected noisy samples to boost model performance. Comprehensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method, especially in imbalanced scenarios. Comprehensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method, especially in imbalanced scenarios.
Is ChatGPT A Good Keyphrase Generator? A Preliminary Study
Mar 23, 2023



The emergence of ChatGPT has recently garnered significant attention from the computational linguistics community. To demonstrate its capabilities as a keyphrase generator, we conduct a preliminary evaluation of ChatGPT for the keyphrase generation task. We evaluate its performance in various aspects, including keyphrase generation prompts, keyphrase generation diversity, multi-domain keyphrase generation, and long document understanding. Our evaluation is based on six benchmark datasets, and we adopt the prompt suggested by OpenAI while extending it to six candidate prompts. We find that ChatGPT performs exceptionally well on all six candidate prompts, with minor performance differences observed across the datasets. Based on our findings, we conclude that ChatGPT has great potential for keyphrase generation. Moreover, we discover that ChatGPT still faces challenges when it comes to generating absent keyphrases. Meanwhile, in the final section, we also present some limitations and future expansions of this report.
DULDA: Dual-domain Unsupervised Learned Descent Algorithm for PET image reconstruction
Mar 10, 2023



Deep learning based PET image reconstruction methods have achieved promising results recently. However, most of these methods follow a supervised learning paradigm, which rely heavily on the availability of high-quality training labels. In particular, the long scanning time required and high radiation exposure associated with PET scans make obtaining this labels impractical. In this paper, we propose a dual-domain unsupervised PET image reconstruction method based on learned decent algorithm, which reconstructs high-quality PET images from sinograms without the need for image labels. Specifically, we unroll the proximal gradient method with a learnable l2,1 norm for PET image reconstruction problem. The training is unsupervised, using measurement domain loss based on deep image prior as well as image domain loss based on rotation equivariance property. The experimental results domonstrate the superior performance of proposed method compared with maximum likelihood expectation maximazation (MLEM), total-variation regularized EM (EM-TV) and deep image prior based method (DIP).
STPDnet: Spatial-temporal convolutional primal dual network for dynamic PET image reconstruction
Mar 08, 2023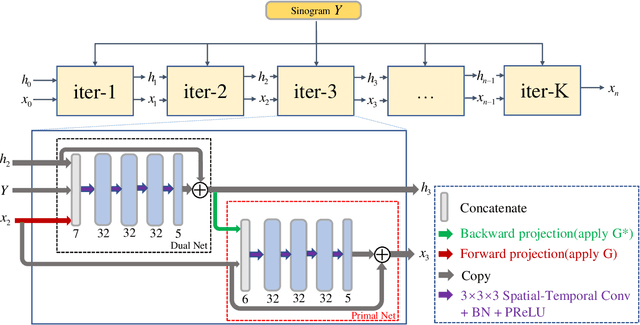
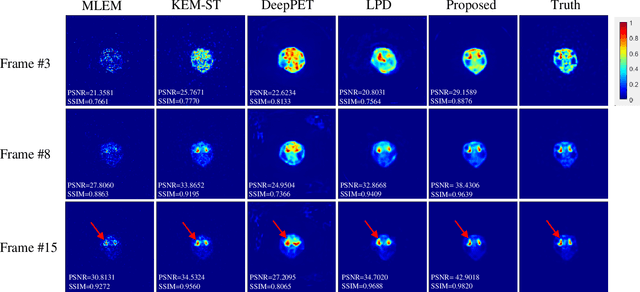
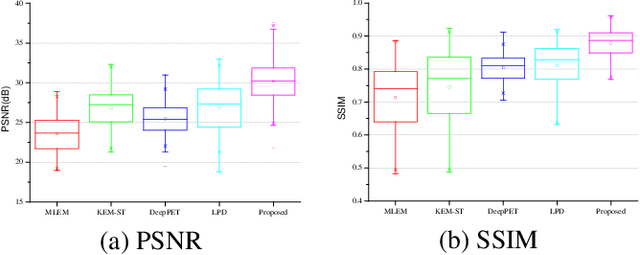
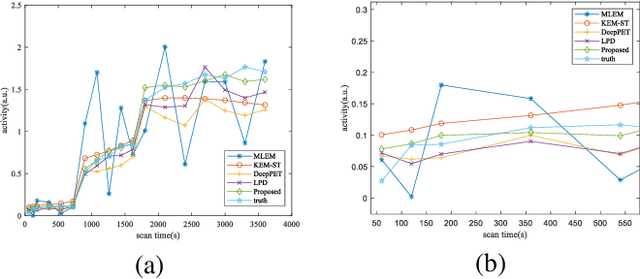
Dynamic positron emission tomography (dPET) image reconstruction is extremely challenging due to the limited counts received in individual frame. In this paper, we propose a spatial-temporal convolutional primal dual network (STPDnet) for dynamic PET image reconstruction. Both spatial and temporal correlations are encoded by 3D convolution operators. The physical projection of PET is embedded in the iterative learning process of the network, which provides the physical constraints and enhances interpretability. The experiments of real rat scan data have shown that the proposed method can achieve substantial noise reduction in both temporal and spatial domains and outperform the maximum likelihood expectation maximization (MLEM), spatial-temporal kernel method (KEM-ST), DeepPET and Learned Primal Dual (LPD).
LMPDNet: TOF-PET list-mode image reconstruction using model-based deep learning method
Feb 21, 2023



The integration of Time-of-Flight (TOF) information in the reconstruction process of Positron Emission Tomography (PET) yields improved image properties. However, implementing the cutting-edge model-based deep learning methods for TOF-PET reconstruction is challenging due to the substantial memory requirements. In this study, we present a novel model-based deep learning approach, LMPDNet, for TOF-PET reconstruction from list-mode data. We address the issue of real-time parallel computation of the projection matrix for list-mode data, and propose an iterative model-based module that utilizes a dedicated network model for list-mode data. Our experimental results indicate that the proposed LMPDNet outperforms traditional iteration-based TOF-PET list-mode reconstruction algorithms. Additionally, we compare the spatial and temporal consumption of list-mode data and sinogram data in model-based deep learning methods, demonstrating the superiority of list-mode data in model-based TOF-PET reconstruction.
FECANet: Boosting Few-Shot Semantic Segmentation with Feature-Enhanced Context-Aware Network
Jan 19, 2023



Few-shot semantic segmentation is the task of learning to locate each pixel of the novel class in the query image with only a few annotated support images. The current correlation-based methods construct pair-wise feature correlations to establish the many-to-many matching because the typical prototype-based approaches cannot learn fine-grained correspondence relations. However, the existing methods still suffer from the noise contained in naive correlations and the lack of context semantic information in correlations. To alleviate these problems mentioned above, we propose a Feature-Enhanced Context-Aware Network (FECANet). Specifically, a feature enhancement module is proposed to suppress the matching noise caused by inter-class local similarity and enhance the intra-class relevance in the naive correlation. In addition, we propose a novel correlation reconstruction module that encodes extra correspondence relations between foreground and background and multi-scale context semantic features, significantly boosting the encoder to capture a reliable matching pattern. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets demonstrate that our proposed FECANet leads to remarkable improvement compared to previous state-of-the-arts, demonstrating its effectiveness.
HessianFR: An Efficient Hessian-based Follow-the-Ridge Algorithm for Minimax Optimization
May 23, 2022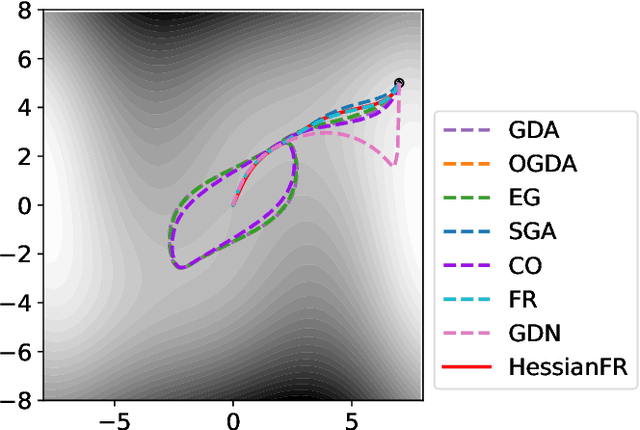
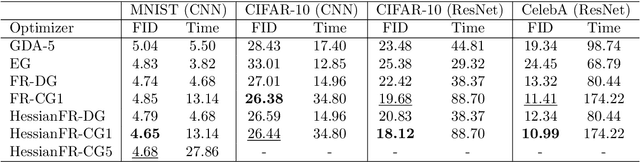
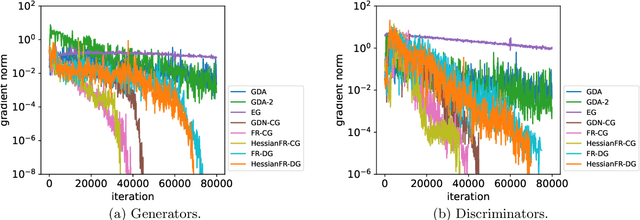
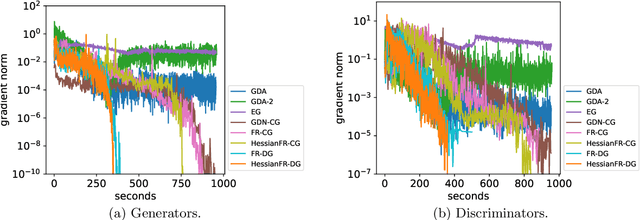
Wide applications of differentiable two-player sequential games (e.g., image generation by GANs) have raised much interest and attention of researchers to study efficient and fast algorithms. Most of the existing algorithms are developed based on nice properties of simultaneous games, i.e., convex-concave payoff functions, but are not applicable in solving sequential games with different settings. Some conventional gradient descent ascent algorithms theoretically and numerically fail to find the local Nash equilibrium of the simultaneous game or the local minimax (i.e., local Stackelberg equilibrium) of the sequential game. In this paper, we propose the HessianFR, an efficient Hessian-based Follow-the-Ridge algorithm with theoretical guarantees. Furthermore, the convergence of the stochastic algorithm and the approximation of Hessian inverse are exploited to improve algorithm efficiency. A series of experiments of training generative adversarial networks (GANs) have been conducted on both synthetic and real-world large-scale image datasets (e.g. MNIST, CIFAR-10 and CelebA). The experimental results demonstrate that the proposed HessianFR outperforms baselines in terms of convergence and image generation quality.
TransEM:Residual Swin-Transformer based regularized PET image reconstruction
May 09, 2022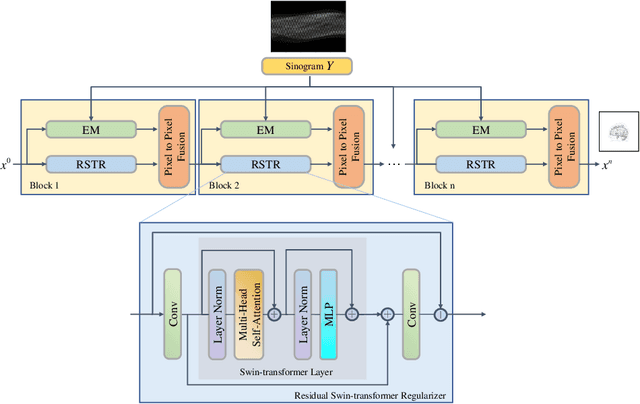

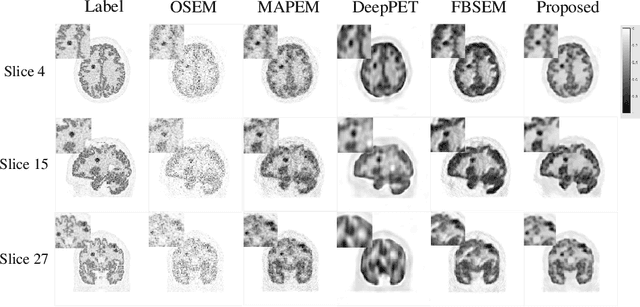
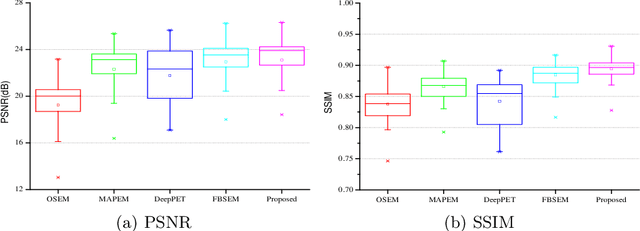
Positron emission tomography(PET) image reconstruction is an ill-posed inverse problem and suffers from high level of noise due to limited counts received. Recently deep neural networks especially convolutional neural networks(CNN) have been successfully applied to PET image reconstruction. However, the local characteristics of the convolution operator potentially limit the image quality obtained by current CNN-based PET image reconstruction methods. In this paper, we propose a residual swin-transformer based regularizer(RSTR) to incorporate regularization into the iterative reconstruction framework. Specifically, a convolution layer is firstly adopted to extract shallow features, then the deep feature extraction is accomplished by the swin-transformer layer. At last, both deep and shallow features are fused with a residual operation and another convolution layer. Validations on the realistic 3D brain simulated low-count data show that our proposed method outperforms the state-of-the-art methods in both qualitative and quantitative measures.
BUDA-SAGE with self-supervised denoising enables fast, distortion-free, high-resolution T2, T2*, para- and dia-magnetic susceptibility mapping
Sep 09, 2021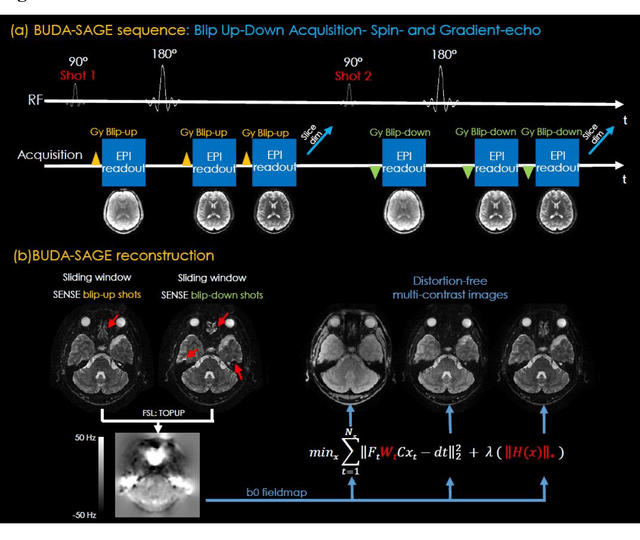
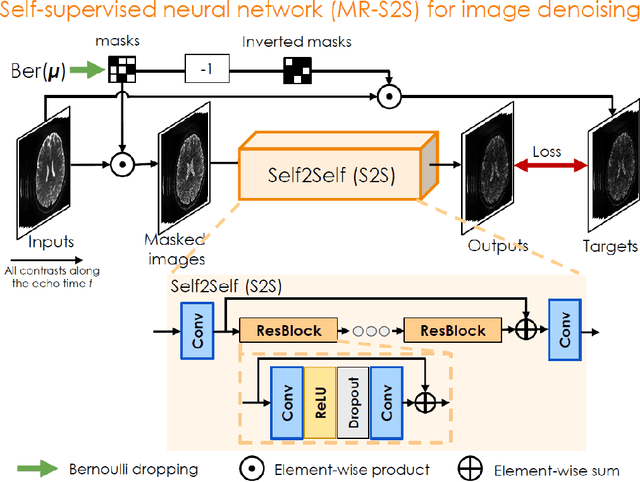

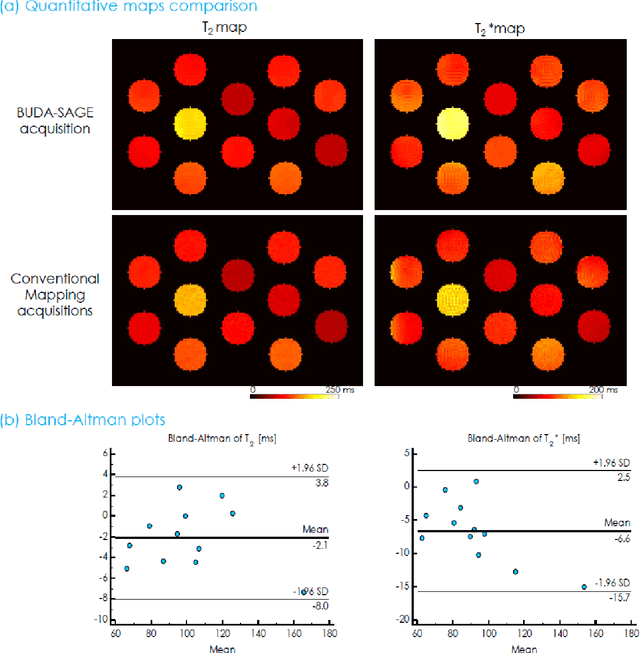
To rapidly obtain high resolution T2, T2* and quantitative susceptibility mapping (QSM) source separation maps with whole-brain coverage and high geometric fidelity. We propose Blip Up-Down Acquisition for Spin And Gradient Echo imaging (BUDA-SAGE), an efficient echo-planar imaging (EPI) sequence for quantitative mapping. The acquisition includes multiple T2*-, T2'- and T2-weighted contrasts. We alternate the phase-encoding polarities across the interleaved shots in this multi-shot navigator-free acquisition. A field map estimated from interim reconstructions was incorporated into the joint multi-shot EPI reconstruction with a structured low rank constraint to eliminate geometric distortion. A self-supervised MR-Self2Self (MR-S2S) neural network (NN) was utilized to perform denoising after BUDA reconstruction to boost SNR. Employing Slider encoding allowed us to reach 1 mm isotropic resolution by performing super-resolution reconstruction on BUDA-SAGE volumes acquired with 2 mm slice thickness. Quantitative T2 and T2* maps were obtained using Bloch dictionary matching on the reconstructed echoes. QSM was estimated using nonlinear dipole inversion (NDI) on the gradient echoes. Starting from the estimated R2 and R2* maps, R2' information was derived and used in source separation QSM reconstruction, which provided additional para- and dia-magnetic susceptibility maps. In vivo results demonstrate the ability of BUDA-SAGE to provide whole-brain, distortion-free, high-resolution multi-contrast images and quantitative T2 and T2* maps, as well as yielding para- and dia-magnetic susceptibility maps. Derived quantitative maps showed comparable values to conventional mapping methods in phantom and in vivo measurements. BUDA-SAGE acquisition with self-supervised denoising and Slider encoding enabled rapid, distortion-free, whole-brain T2, T2* mapping at 1 mm3 isotropic resolution in 90 seconds.
Exploiting Web Images for Fine-Grained Visual Recognition by Eliminating Noisy Samples and Utilizing Hard Ones
Jan 23, 2021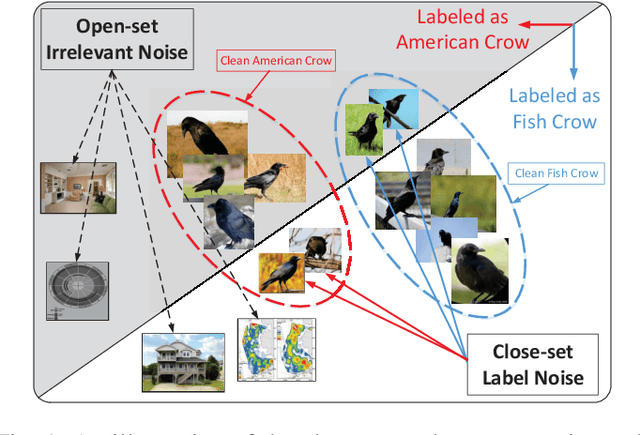
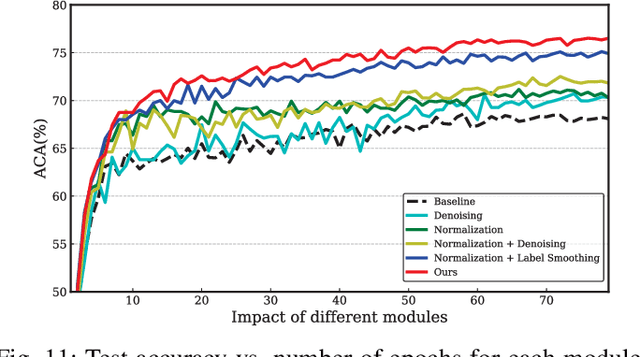

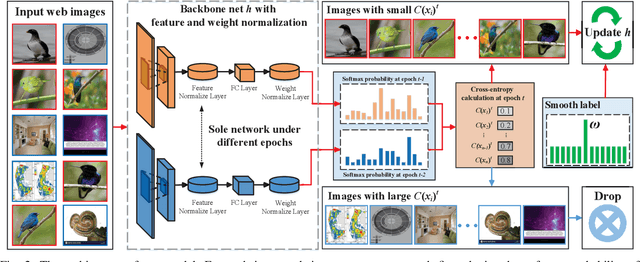
Labeling objects at a subordinate level typically requires expert knowledge, which is not always available when using random annotators. As such, learning directly from web images for fine-grained recognition has attracted broad attention. However, the presence of label noise and hard examples in web images are two obstacles for training robust fine-grained recognition models. Therefore, in this paper, we propose a novel approach for removing irrelevant samples from real-world web images during training, while employing useful hard examples to update the network. Thus, our approach can alleviate the harmful effects of irrelevant noisy web images and hard examples to achieve better performance. Extensive experiments on three commonly used fine-grained datasets demonstrate that our approach is far superior to current state-of-the-art web-supervised methods.