 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Guided Mixed Masked Pretraining and Spatial Continuity Regularization for Printed Circuit Board Defect Detection
Jun 02, 2026Printed circuit board (PCB) defect detection is an essential part of automated optical inspection (AOI); yet it remains challenging in practice because many defects are tiny, low-contrast, and embedded in dense circuit backgrounds. To address these issues, this paper presents a two-phase PCB defect detection framework that combines structure-guided mixed masked pretraining with spatial continuity regularization. In the pretraining stage, we design a sparse convolutional masked pretraining scheme to exploit unlabeled PCB images, where structure-guided mixed masking is used to construct informative masked inputs. The sparse convolutional reconstruction pipeline suppresses invalid responses from masked regions and enables the detector backbone to infer missing PCB structures from visible conductive patterns, thereby learning PCB structural priors. In the fine-tuning stage, the pretrained backbone is transferred to the downstream defect detection task. For the task, a spatial continuity regularization term is introduced during fine-tuning. This term constrains dispersed positive predictions assigned to the same defect instance and promotes more compact localization on elongated defect regions. Experiments on the DsPCBSD+ dataset show that the proposed method achieves 85.5% mAP0.5 and 52.3% mAP0.5:0.95, outperforming several strong baseline detectors. Ablation studies and qualitative results further confirm the effectiveness of the proposed framework for robust PCB defect detection in industrial AOI scenarios.
A Patch-based Cross-view Regularized Framework for Backdoor Defense in Multimodal Large Language Models
Apr 06, 2026Multimodal large language models have become an important infrastructure for unified processing of visual and linguistic tasks. However, such models are highly susceptible to backdoor implantation during supervised fine-tuning and will steadily output the attacker's predefined harmful responses once a specific trigger pattern is activated. The core challenge of backdoor defense lies in suppressing attack success under low poisoning ratios while preserving the model's normal generation ability. These two objectives are inherently conflicting. Strong suppression often degrades benign performance, whereas weak regularization fails to mitigate backdoor behaviors. To this end, we propose a unified defense framework based on patch augmentation and cross-view regularity, which simultaneously constrains the model's anomalous behaviors in response to triggered patterns from both the feature representation and output distribution levels. Specifically, patch-level data augmentation is combined with cross-view output difference regularization to exploit the fact that backdoor responses are abnormally invariant to non-semantic perturbations and to proactively pull apart the output distributions of the original and perturbed views, thereby significantly suppressing the success rate of backdoor triggering. At the same time, we avoid over-suppression of the model during defense by imposing output entropy constraints, ensuring the quality of normal command generation. Experimental results across three models, two tasks, and six attacks show that our proposed defense method effectively reduces the attack success rate while maintaining a high level of normal text generation capability. Our work enables the secure, controlled deployment of large-scale multimodal models in realistic low-frequency poisoning and covert triggering scenarios.
Explore Internal and External Similarity for Single Image Deraining with Graph Neural Networks
Jun 02, 2024



Patch-level non-local self-similarity is an important property of natural images. However, most existing methods do not consider this property into neural networks for image deraining, thus affecting recovery performance. Motivated by this property, we find that there exists significant patch recurrence property of a rainy image, that is, similar patches tend to recur many times in one image and its multi-scale images and external images. To better model this property for image detaining, we develop a multi-scale graph network with exemplars, called MSGNN, that contains two branches: 1) internal data-based supervised branch is used to model the internal relations of similar patches from the rainy image itself and its multi-scale images and 2) external data-participated unsupervised branch is used to model the external relations of the similar patches in the rainy image and exemplar. Specifically, we construct a graph model by searching the k-nearest neighboring patches from both the rainy images in a multi-scale framework and the exemplar. After obtaining the corresponding k neighboring patches from the multi-scale images and exemplar, we build a graph and aggregate them in an attentional manner so that the graph can provide more information from similar patches for image deraining. We embed the proposed graph in a deep neural network and train it in an end-to-end manner. Extensive experiments demonstrate that the proposed algorithm performs favorably against eight state-of-the-art methods on five public synthetic datasets and one real-world dataset. The source codes will be available at https://github.com/supersupercong/MSGNN.
STPDnet: Spatial-temporal convolutional primal dual network for dynamic PET image reconstruction
Mar 08, 2023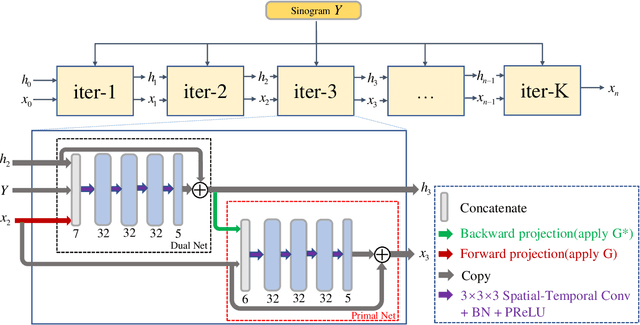
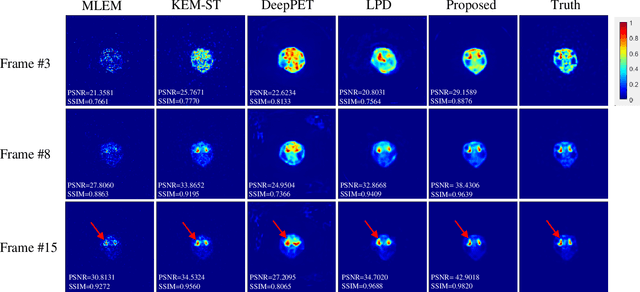
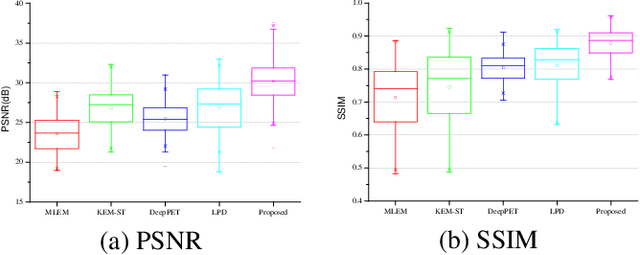
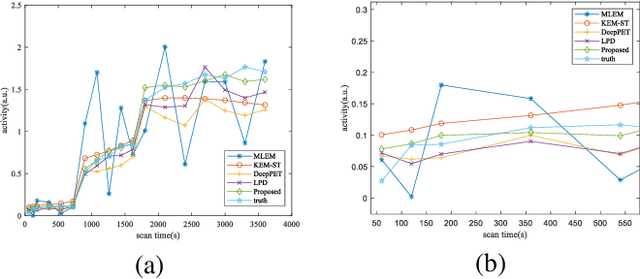
Dynamic positron emission tomography (dPET) image reconstruction is extremely challenging due to the limited counts received in individual frame. In this paper, we propose a spatial-temporal convolutional primal dual network (STPDnet) for dynamic PET image reconstruction. Both spatial and temporal correlations are encoded by 3D convolution operators. The physical projection of PET is embedded in the iterative learning process of the network, which provides the physical constraints and enhances interpretability. The experiments of real rat scan data have shown that the proposed method can achieve substantial noise reduction in both temporal and spatial domains and outperform the maximum likelihood expectation maximization (MLEM), spatial-temporal kernel method (KEM-ST), DeepPET and Learned Primal Dual (LPD).