 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective Context for Meta-Reinforcement Learning: an Approach based on Contrastive Learning
Oct 07, 2020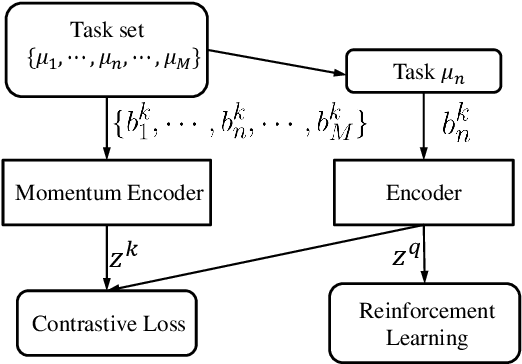

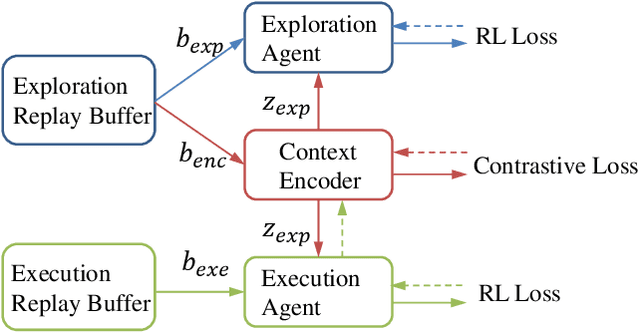
Context, the embedding of previous collected trajectories, is a powerful construct for Meta-Reinforcement Learning (Meta-RL) algorithms. By conditioning on an effective context, Meta-RL policies can easily generalize to new tasks within a few adaptation steps. We argue that improving the quality of context involves answering two questions: 1. How to train a compact and sufficient encoder that can embed the task-specific information contained in prior trajectories? 2. How to collect informative trajectories of which the corresponding context reflects the specification of tasks? To this end, we propose a novel Meta-RL framework called CCM (Contrastive learning augmented Context-based Meta-RL). We first focus on the contrastive nature behind different tasks and leverage it to train a compact and sufficient context encoder. Further, we train a separate exploration policy and theoretically derive a new information-gain-based objective which aims to collect informative trajectories in a few steps. Empirically, we evaluate our approaches on common benchmarks as well as several complex sparse-reward environments. The experimental results show that CCM outperforms state-of-the-art algorithms by addressing previously mentioned problems respectively.
KoGuN: Accelerating Deep Reinforcement Learning via Integrating Human Suboptimal Knowledge
Feb 18, 2020



Reinforcement learning agents usually learn from scratch, which requires a large number of interactions with the environment. This is quite different from the learning process of human. When faced with a new task, human naturally have the common sense and use the prior knowledge to derive an initial policy and guide the learning process afterwards. Although the prior knowledge may be not fully applicable to the new task, the learning process is significantly sped up since the initial policy ensures a quick-start of learning and intermediate guidance allows to avoid unnecessary exploration. Taking this inspiration, we propose knowledge guided policy network (KoGuN), a novel framework that combines human prior suboptimal knowledge with reinforcement learning. Our framework consists of a fuzzy rule controller to represent human knowledge and a refine module to fine-tune suboptimal prior knowledge. The proposed framework is end-to-end and can be combined with existing policy-based reinforcement learning algorithm. We conduct experiments on both discrete and continuous control tasks. The empirical results show that our approach, which combines human suboptimal knowledge and RL, achieves significant improvement on learning efficiency of flat RL algorithms, even with very low-performance human prior knowledge.
Efficient meta reinforcement learning via meta goal generation
Nov 10, 2019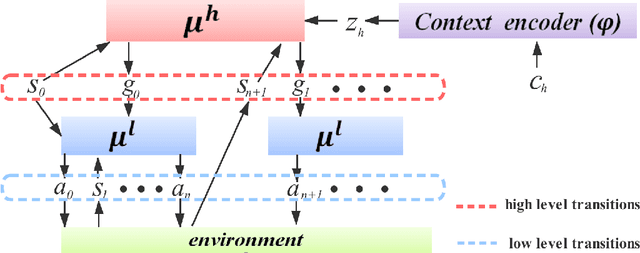
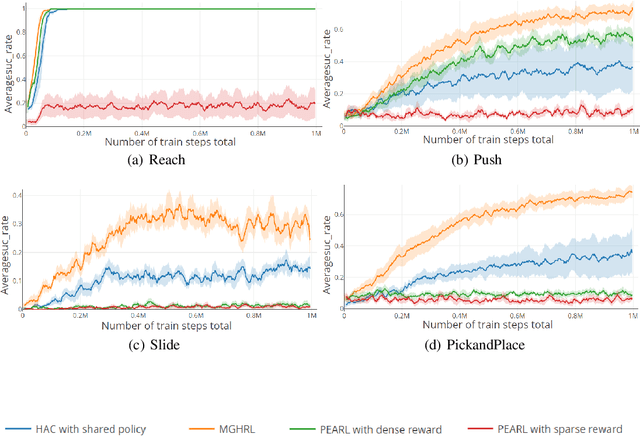
Meta reinforcement learning (meta-RL) is able to accelerate the acquisition of new tasks by learning from past experience. Current meta-RL methods usually learn to adapt to new tasks by directly optimizing the parameters of policies over primitive actions. However, for complex tasks which requires sophisticated control strategies, it would be quite inefficient to to directly learn such a meta-policy. Moreover, this problem can become more severe and even fail in spare reward settings, which is quite common in practice. To this end, we propose a new meta-RL algorithm called meta goal-generation for hierarchical RL (MGHRL) by leveraging hierarchical actor-critic framework. Instead of directly generate policies over primitive actions for new tasks, MGHRL learns to generate high-level meta strategies over subgoals given past experience and leaves the rest of how to achieve subgoals as independent RL subtasks. Our empirical results on several challenging simulated robotics environments show that our method enables more efficient and effective meta-learning from past experience and outperforms state-of-the-art meta-RL and Hierarchical-RL methods in sparse reward settings.
Disentangling Dynamics and Returns: Value Function Decomposition with Future Prediction
May 27, 2019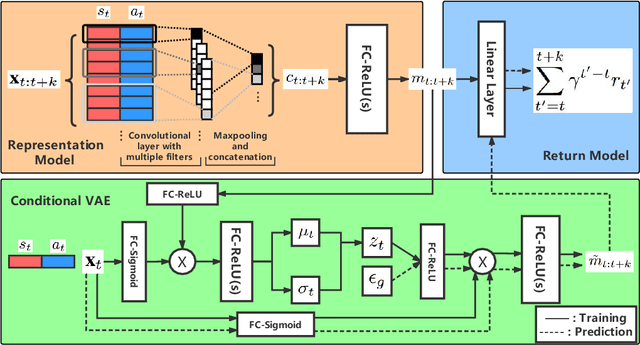
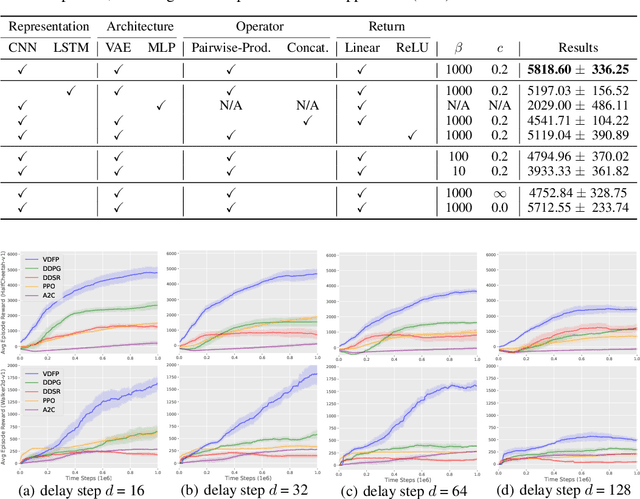
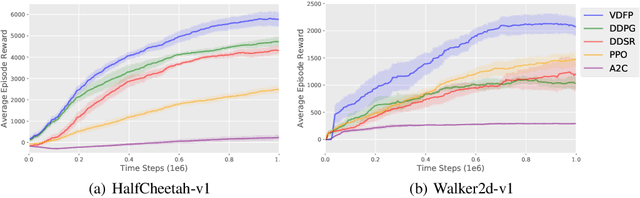

Value functions are crucial for model-free Reinforcement Learning (RL) to obtain a policy implicitly or guide the policy updates. Value estimation heavily depends on the stochasticity of environmental dynamics and the quality of reward signals. In this paper, we propose a two-step understanding of value estimation from the perspective of future prediction, through decomposing the value function into a reward-independent future dynamics part and a policy-independent trajectory return part. We then derive a practical deep RL algorithm from the above decomposition, consisting of a convolutional trajectory representation model, a conditional variational dynamics model to predict the expected representation of future trajectory and a convex trajectory return model that maps a trajectory representation to its return. Our algorithm is evaluated in MuJoCo continuous control tasks and shows superior results under both common settings and delayed reward settings.
Deep Multi-Agent Reinforcement Learning with Discrete-Continuous Hybrid Action Spaces
Mar 12, 2019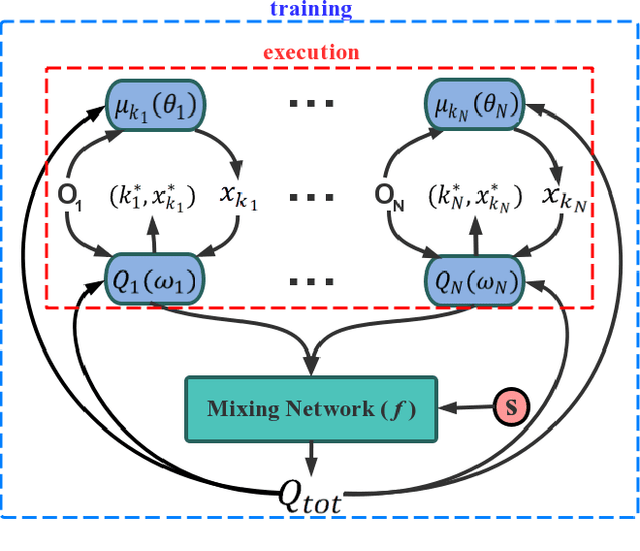
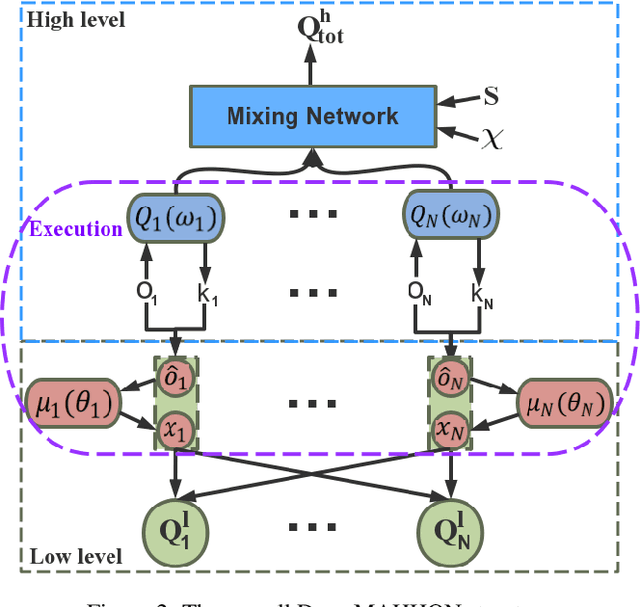
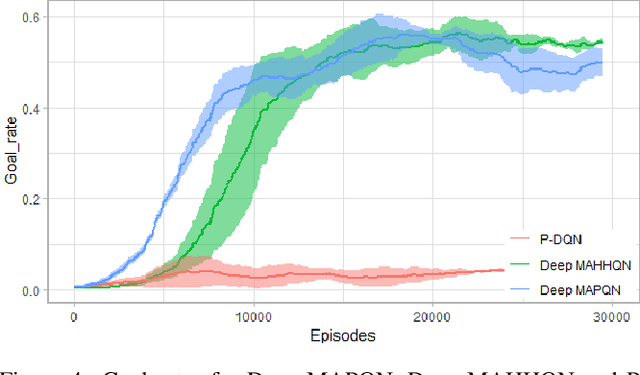
Deep Reinforcement Learning (DRL) has been applied to address a variety of cooperative multi-agent problems with either discrete action spaces or continuous action spaces. However, to the best of our knowledge, no previous work has ever succeeded in applying DRL to multi-agent problems with discrete-continuous hybrid (or parameterized) action spaces which is very common in practice. Our work fills this gap by proposing two novel algorithms: Deep Multi-Agent Parameterized Q-Networks (Deep MAPQN) and Deep Multi-Agent Hierarchical Hybrid Q-Networks (Deep MAHHQN). We follow the centralized training but decentralized execution paradigm: different levels of communication between different agents are used to facilitate the training process, while each agent executes its policy independently based on local observations during execution. Our empirical results on several challenging tasks (simulated RoboCup Soccer and game Ghost Story) show that both Deep MAPQN and Deep MAHHQN are effective and significantly outperform existing independent deep parameterized Q-learning method.
Hierarchical Deep Multiagent Reinforcement Learning
Sep 25, 2018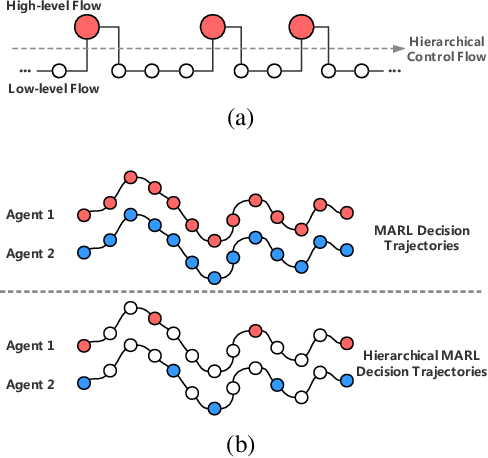
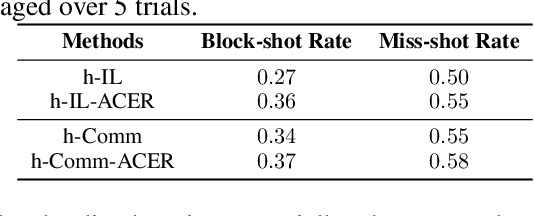
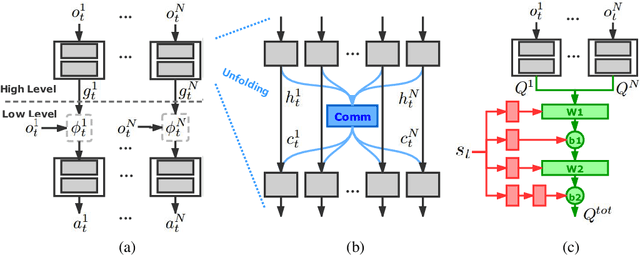
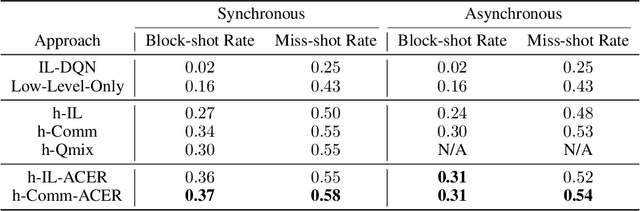
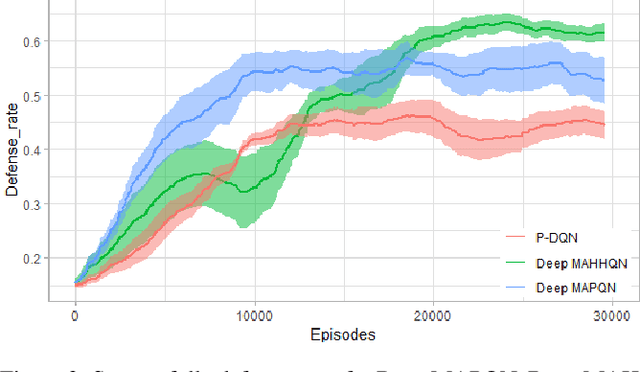
Despite deep reinforcement learning has recently achieved great successes, however in multiagent environments, a number of challenges still remain. Multiagent reinforcement learning (MARL) is commonly considered to suffer from the problem of non-stationary environments and exponentially increasing policy space. It would be even more challenging to learn effective policies in circumstances where the rewards are sparse and delayed over long trajectories. In this paper, we study Hierarchical Deep Multiagent Reinforcement Learning (hierarchical deep MARL) in cooperative multiagent problems with sparse and delayed rewards, where efficient multiagent learning methods are desperately needed. We decompose the original MARL problem into hierarchies and investigate how effective policies can be learned hierarchically in synchronous/asynchronous hierarchical MARL frameworks. Several hierarchical deep MARL architectures, i.e., Ind-hDQN, hCom and hQmix, are introduced for different learning paradigms. Moreover, to alleviate the issues of sparse experiences in high-level learning and non-stationarity in multiagent settings, we propose a new experience replay mechanism, named as Augmented Concurrent Experience Replay (ACER). We empirically demonstrate the effects and efficiency of our approaches in several classic Multiagent Trash Collection tasks, as well as in an extremely challenging team sports game, i.e., Fever Basketball Defense.
An Optimal Rewiring Strategy for Reinforcement Social Learning in Cooperative Multiagent Systems
May 13, 2018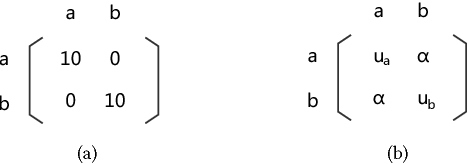
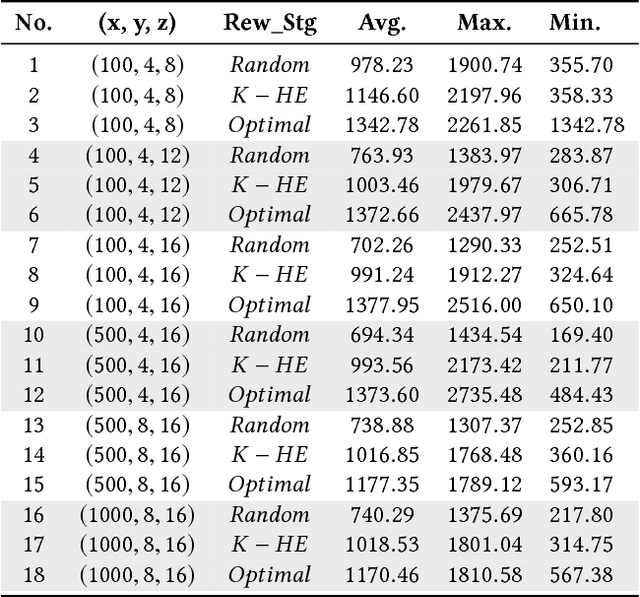
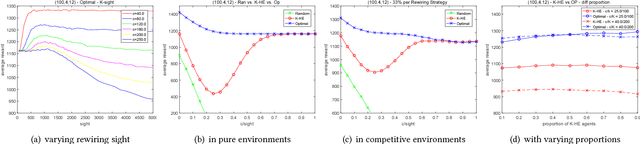
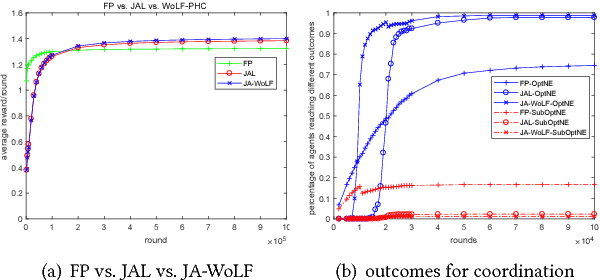
Multiagent coordination in cooperative multiagent systems (MASs) has been widely studied in both fixed-agent repeated interaction setting and the static social learning framework. However, two aspects of dynamics in real-world multiagent scenarios are currently missing in existing works. First, the network topologies can be dynamic where agents may change their connections through rewiring during the course of interactions. Second, the game matrix between each pair of agents may not be static and usually not known as a prior. Both the network dynamic and game uncertainty increase the coordination difficulty among agents. In this paper, we consider a multiagent dynamic social learning environment in which each agent can choose to rewire potential partners and interact with randomly chosen neighbors in each round. We propose an optimal rewiring strategy for agents to select most beneficial peers to interact with for the purpose of maximizing the accumulated payoff in repeated interactions. We empirically demonstrate the effectiveness and robustness of our approach through comparing with benchmark strategies. The performance of three representative learning strategies under our social learning framework with our optimal rewiring is investigated as well.