 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Negotiator's Backup Plan: Optimal Concessions with a Reservation Value
Apr 30, 2024Automated negotiation is a well-known mechanism for autonomous agents to reach agreements. To realize beneficial agreements quickly, it is key to employ a good bidding strategy. When a negotiating agent has a good back-up plan, i.e., a high reservation value, failing to reach an agreement is not necessarily disadvantageous. Thus, the agent can adopt a risk-seeking strategy, aiming for outcomes with a higher utilities. Accordingly, this paper develops an optimal bidding strategy called MIA-RVelous for bilateral negotiations with private reservation values. The proposed greedy algorithm finds the optimal bid sequence given the agent's beliefs about the opponent in $O(n^2D)$ time, with $D$ the maximum number of rounds and $n$ the number of outcomes. The results obtained here can pave the way to realizing effective concurrent negotiations, given that concurrent negotiations can serve as a (probabilistic) backup plan.
Automated Peer-to-peer Negotiation for Energy Contract Settlements in Residential Cooperatives
Nov 26, 2019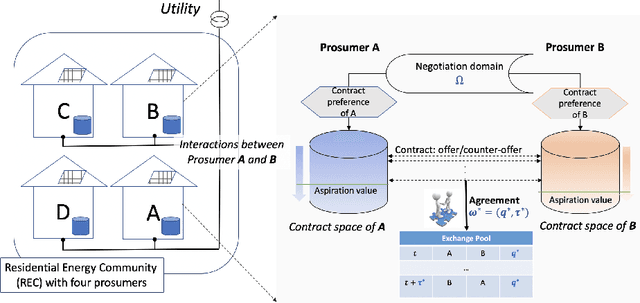

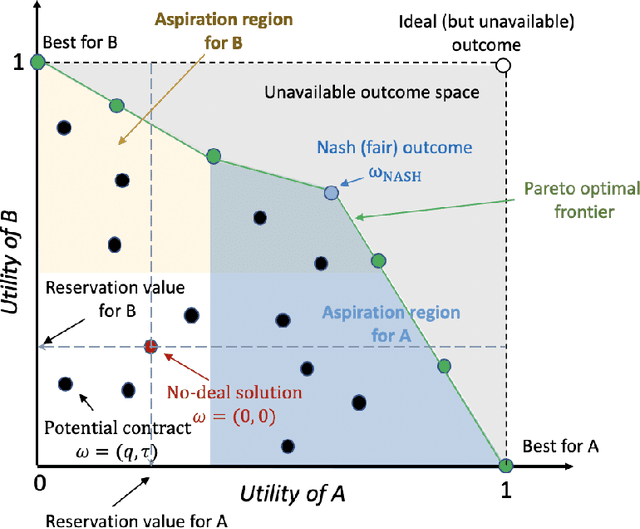

This paper presents an automated peer-to-peer negotiation strategy for settling energy contracts among prosumers in a Residential Energy Cooperative considering heterogeneity prosumer preferences. The heterogeneity arises from prosumers' evaluation of energy contracts through multiple societal and environmental criteria and the prosumers' private preferences over those criteria. The prosumers engage in bilateral negotiations with peers to mutually agree on periodical energy contracts/loans consisting of the energy volume to be exchanged at that period and the return time of the exchanged energy. The negotiating prosumers navigate through a common negotiation domain consisting of potential energy contracts and evaluate those contracts from their valuations on the entailed criteria against a utility function that is robust against generation and demand uncertainty. From the repeated interactions, a prosumer gradually learns about the compatibility of its peers in reaching energy contracts that are closer to Nash solutions. Empirical evaluation on real demand, generation and storage profiles -- in multiple system scales -- illustrates that the proposed negotiation based strategy can increase the system efficiency (measured by utilitarian social welfare) and fairness (measured by Nash social welfare) over a baseline strategy and an individual flexibility control strategy representing the status quo strategy. We thus elicit system benefits from peer-to-peer flexibility exchange already without any central coordination and market operator, providing a simple yet flexible and effective paradigm that complements existing markets.
An Optimal Rewiring Strategy for Reinforcement Social Learning in Cooperative Multiagent Systems
May 13, 2018
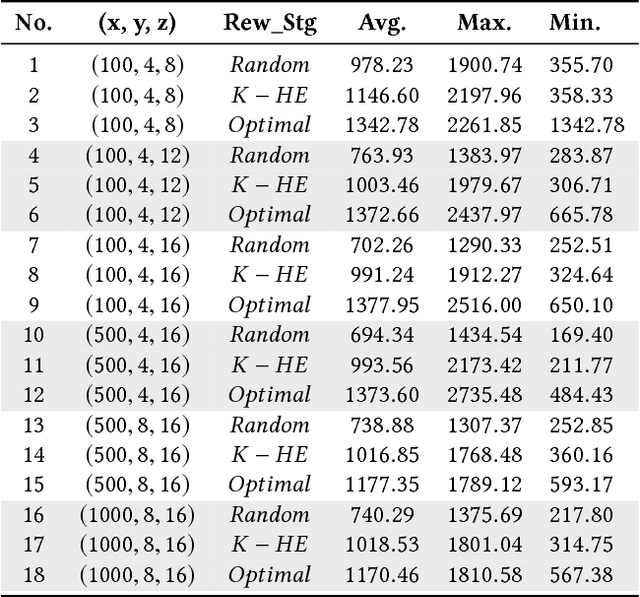
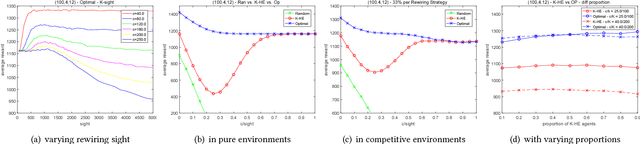
Multiagent coordination in cooperative multiagent systems (MASs) has been widely studied in both fixed-agent repeated interaction setting and the static social learning framework. However, two aspects of dynamics in real-world multiagent scenarios are currently missing in existing works. First, the network topologies can be dynamic where agents may change their connections through rewiring during the course of interactions. Second, the game matrix between each pair of agents may not be static and usually not known as a prior. Both the network dynamic and game uncertainty increase the coordination difficulty among agents. In this paper, we consider a multiagent dynamic social learning environment in which each agent can choose to rewire potential partners and interact with randomly chosen neighbors in each round. We propose an optimal rewiring strategy for agents to select most beneficial peers to interact with for the purpose of maximizing the accumulated payoff in repeated interactions. We empirically demonstrate the effectiveness and robustness of our approach through comparing with benchmark strategies. The performance of three representative learning strategies under our social learning framework with our optimal rewiring is investigated as well.
A Survey of Learning in Multiagent Environments: Dealing with Non-Stationarity
Jul 28, 2017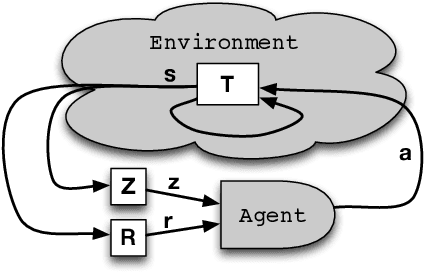
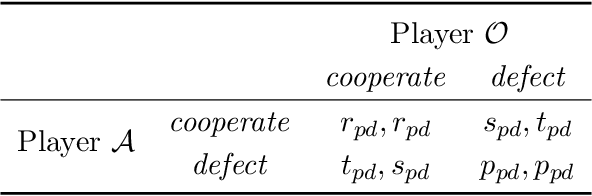
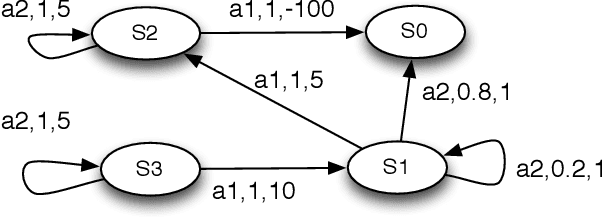
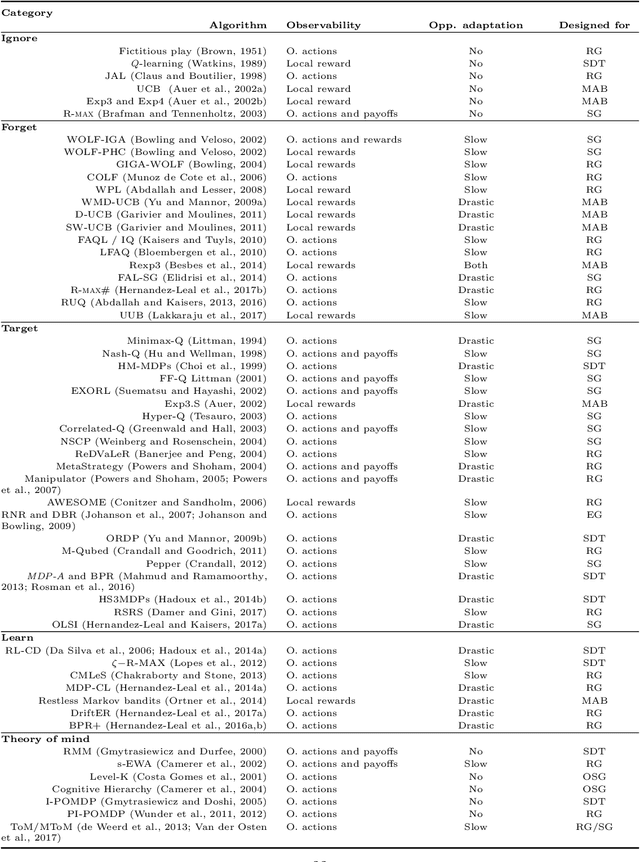
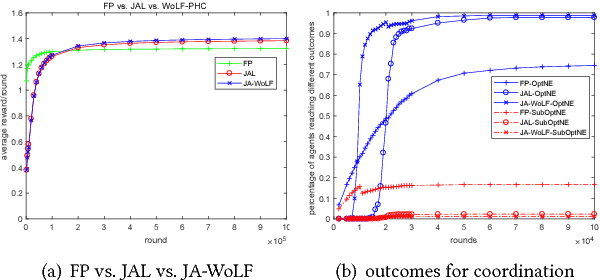
The key challenge in multiagent learning is learning a best response to the behaviour of other agents, which may be non-stationary: if the other agents adapt their strategy as well, the learning target moves. Disparate streams of research have approached non-stationarity from several angles, which make a variety of implicit assumptions that make it hard to keep an overview of the state of the art and to validate the innovation and significance of new works. This survey presents a coherent overview of work that addresses opponent-induced non-stationarity with tools from game theory, reinforcement learning and multi-armed bandits. Further, we reflect on the principle approaches how algorithms model and cope with this non-stationarity, arriving at a new framework and five categories (in increasing order of sophistication): ignore, forget, respond to target models, learn models, and theory of mind. A wide range of state-of-the-art algorithms is classified into a taxonomy, using these categories and key characteristics of the environment (e.g., observability) and adaptation behaviour of the opponents (e.g., smooth, abrupt). To clarify even further we present illustrative variations of one domain, contrasting the strengths and limitations of each category. Finally, we discuss in which environments the different approaches yield most merit, and point to promising avenues of future research.
Can we reach Pareto optimal outcomes using bottom-up approaches?
Jul 03, 2016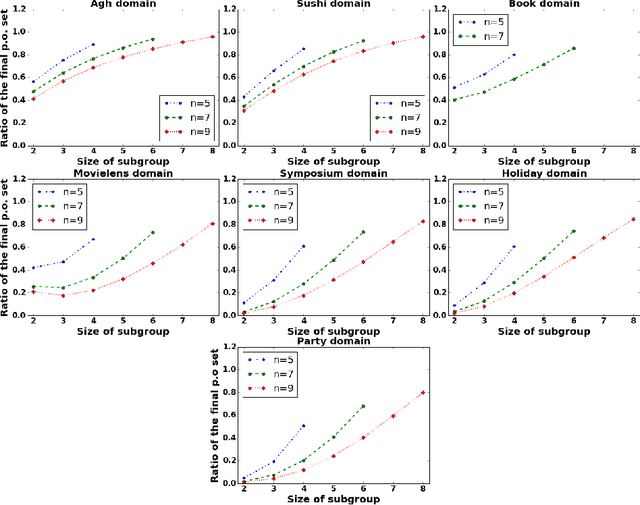
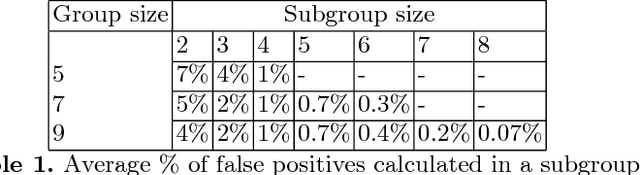
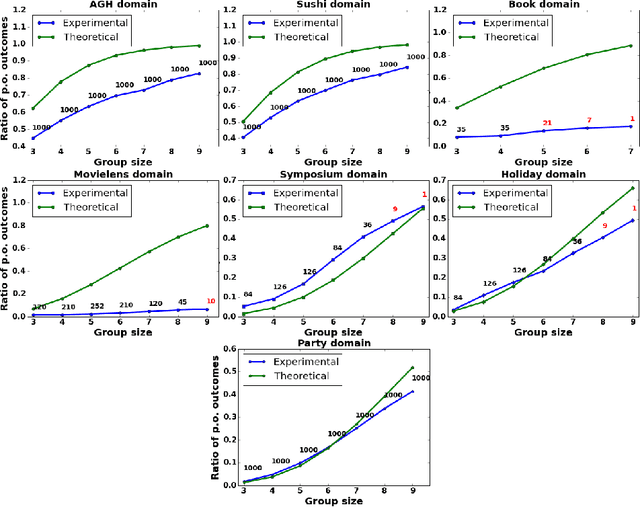
Traditionally, researchers in decision making have focused on attempting to reach Pareto Optimality using horizontal approaches, where optimality is calculated taking into account every participant at the same time. Sometimes, this may prove to be a difficult task (e.g., conflict, mistrust, no information sharing, etc.). In this paper, we explore the possibility of achieving Pareto Optimal outcomes in a group by using a bottom-up approach: discovering Pareto optimal outcomes by interacting in subgroups. We analytically show that Pareto optimal outcomes in a subgroup are also Pareto optimal in a supergroup of those agents in the case of strict, transitive, and complete preferences. Then, we empirically analyze the prospective usability and practicality of bottom-up approaches in a variety of decision making domains.
Optimistic Risk Perception in the Temporal Difference error Explains the Relation between Risk-taking, Gambling, Sensation-seeking and Low Fear
Feb 03, 2015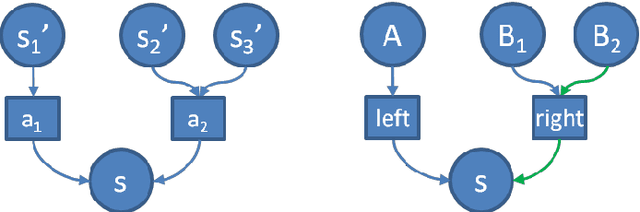
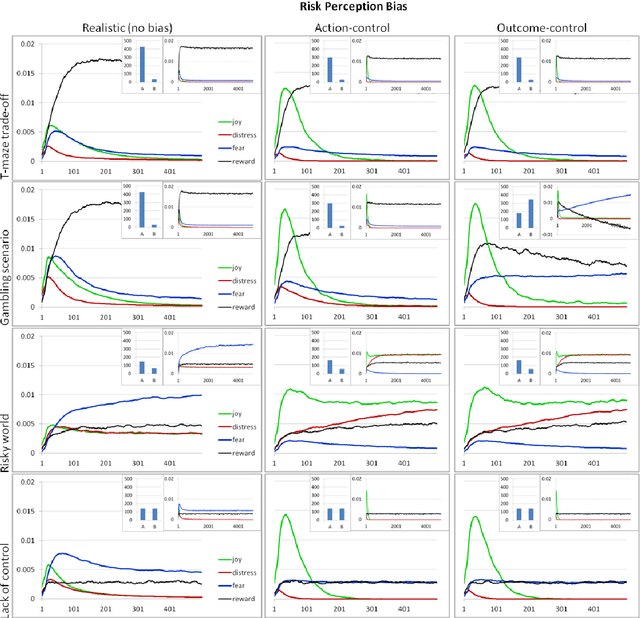
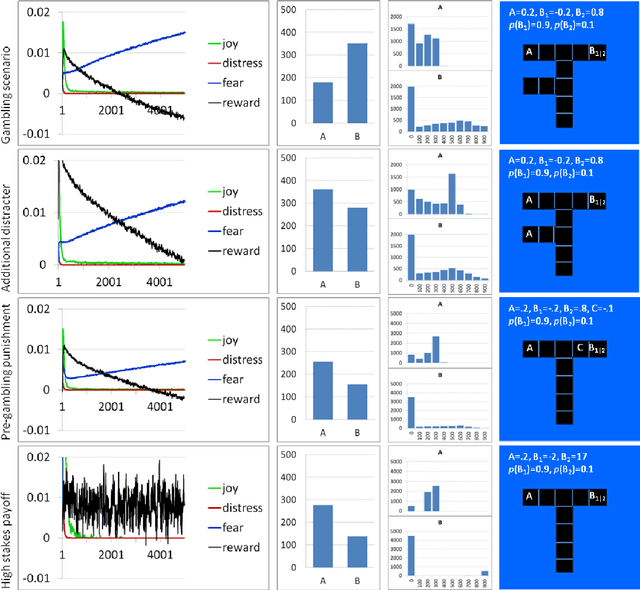
Understanding the affective, cognitive and behavioural processes involved in risk taking is essential for treatment and for setting environmental conditions to limit damage. Using Temporal Difference Reinforcement Learning (TDRL) we computationally investigated the effect of optimism in risk perception in a variety of goal-oriented tasks. Optimism in risk perception was studied by varying the calculation of the Temporal Difference error, i.e., delta, in three ways: realistic (stochastically correct), optimistic (assuming action control), and overly optimistic (assuming outcome control). We show that for the gambling task individuals with 'healthy' perception of control, i.e., action optimism, do not develop gambling behaviour while individuals with 'unhealthy' perception of control, i.e., outcome optimism, do. We show that high intensity of sensations and low levels of fear co-occur due to optimistic risk perception. We found that overly optimistic risk perception (outcome optimism) results in risk taking and in persistent gambling behaviour in addition to high intensity of sensations. We discuss how our results replicate risk-taking related phenomena.