 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere to Look: Can Foundation Models Reach a Target Viewpoint Through Active Exploration?
May 31, 2026Humans can reproduce the viewpoint specified by a target image through active head and body motion, yet spatial intelligence in foundation models has largely been studied as passive understanding of pre-collected observations. We introduce Target Viewpoint Reproduction (TVR) -- an active task where an agent adjusts its viewpoint in a 3D environment until its observation matches a given target image -- and TVRBench, an indoor-simulation benchmark spanning scene scale and target-view visual richness. TVR is far from solved: on the evaluation split, the strongest open-source and closed-source models reach only 7.8% and 12.0% success. Fine-grained analysis identifies two consistent bottlenecks: off-the-shelf models struggle with multi-turn visual history, and performance drops sharply when viewpoint reproduction requires body translation rather than in-place rotation, exposing a gap in mapping spatial discrepancies to embodied movement. To study reducing this gap, we build a unified TVR post-training framework covering expert-trajectory SFT, rationale-supervised CoT-SFT, offline Single-turn GRPO, and on-policy Multi-turn GRPO from live simulator rollouts. Visual-action SFT supplies the main gain, raising a 9B open-source model to 50.8% success; Multi-turn GRPO provides targeted multi-room refinement and reaches 51.4% overall, while CoT supervision and Single-turn GRPO degrade closed-loop performance. These results establish TVRBench as a testbed for measuring and training foundation models that actively perceive and act in 3D environments. Our code, data, and models are available at https://github.com/aim-uofa/TVRBench.
MiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling
Feb 12, 2026The evolution of large language models (LLMs) towards applications with ultra-long contexts faces challenges posed by the high computational and memory costs of the Transformer architecture. While existing sparse and linear attention mechanisms attempt to mitigate these issues, they typically involve a trade-off between memory efficiency and model performance. This paper introduces MiniCPM-SALA, a 9B-parameter hybrid architecture that integrates the high-fidelity long-context modeling of sparse attention (InfLLM-V2) with the global efficiency of linear attention (Lightning Attention). By employing a layer selection algorithm to integrate these mechanisms in a 1:3 ratio and utilizing a hybrid positional encoding (HyPE), the model maintains efficiency and performance for long-context tasks. Furthermore, we introduce a cost-effective continual training framework that transforms pre-trained Transformer-based models into hybrid models, which reduces training costs by approximately 75% compared to training from scratch. Extensive experiments show that MiniCPM-SALA maintains general capabilities comparable to full-attention models while offering improved efficiency. On a single NVIDIA A6000D GPU, the model achieves up to 3.5x the inference speed of the full-attention model at the sequence length of 256K tokens and supports context lengths of up to 1M tokens, a scale where traditional full-attention 8B models fail because of memory constraints.
Data Science and Technology Towards AGI Part I: Tiered Data Management
Feb 09, 2026The development of artificial intelligence can be viewed as an evolution of data-driven learning paradigms, with successive shifts in data organization and utilization continuously driving advances in model capability. Current LLM research is dominated by a paradigm that relies heavily on unidirectional scaling of data size, increasingly encountering bottlenecks in data availability, acquisition cost, and training efficiency. In this work, we argue that the development of AGI is entering a new phase of data-model co-evolution, in which models actively guide data management while high-quality data, in turn, amplifies model capabilities. To implement this vision, we propose a tiered data management framework, designed to support the full LLM training lifecycle across heterogeneous learning objectives and cost constraints. Specifically, we introduce an L0-L4 tiered data management framework, ranging from raw uncurated resources to organized and verifiable knowledge. Importantly, LLMs are fully used in data management processes, such as quality scoring and content editing, to refine data across tiers. Each tier is characterized by distinct data properties, management strategies, and training roles, enabling data to be strategically allocated across LLM training stages, including pre-training, mid-training, and alignment. The framework balances data quality, acquisition cost, and marginal training benefit, providing a systematic approach to scalable and sustainable data management. We validate the effectiveness of the proposed framework through empirical studies, in which tiered datasets are constructed from raw corpora and used across multiple training phases. Experimental results demonstrate that tier-aware data utilization significantly improves training efficiency and model performance. To facilitate further research, we release our tiered datasets and processing tools to the community.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
SambaLingo: Teaching Large Language Models New Languages
Apr 08, 2024



Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
Towards Safety-Aware Computing System Design in Autonomous Vehicles
May 22, 2019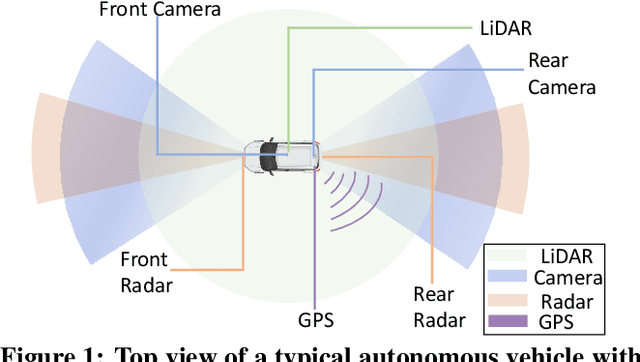

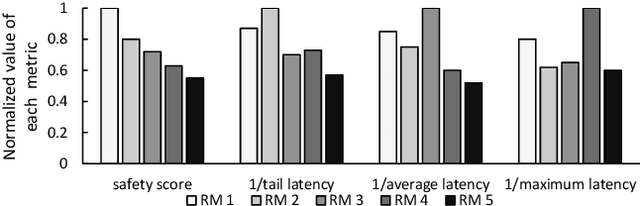
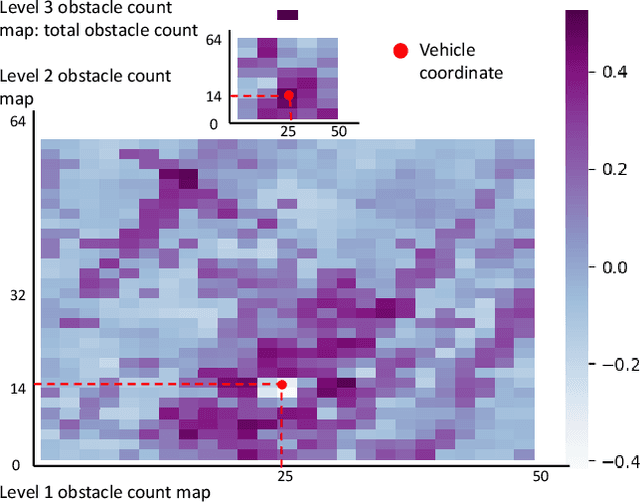
Recently, autonomous driving development ignited competition among car makers and technical corporations. Low-level automation cars are already commercially available. But high automated vehicles where the vehicle drives by itself without human monitoring is still at infancy. Such autonomous vehicles (AVs) rely on the computing system in the car to to interpret the environment and make driving decisions. Therefore, computing system design is essential particularly in enhancing the attainment of driving safety. However, to our knowledge, no clear guideline exists so far regarding safety-aware AV computing system and architecture design. To understand the safety requirement of AV computing system, we performed a field study by running industrial Level-4 autonomous driving fleets in various locations, road conditions, and traffic patterns. The field study indicates that traditional computing system performance metrics, such as tail latency, average latency, maximum latency, and timeout, cannot fully satisfy the safety requirement for AV computing system design. To address this issue, we propose a `safety score' as a primary metric for measuring the level of safety in AV computing system design. Furthermore, we propose a perception latency model, which helps architects estimate the safety score of given architecture and system design without physically testing them in an AV. We demonstrate the use of our safety score and latency model, by developing and evaluating a safety-aware AV computing system computation hardware resource management scheme.