 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Geometric Graph Neural Networks: Data Structures, Models and Applications
Mar 01, 2024Geometric graph is a special kind of graph with geometric features, which is vital to model many scientific problems. Unlike generic graphs, geometric graphs often exhibit physical symmetries of translations, rotations, and reflections, making them ineffectively processed by current Graph Neural Networks (GNNs). To tackle this issue, researchers proposed a variety of Geometric Graph Neural Networks equipped with invariant/equivariant properties to better characterize the geometry and topology of geometric graphs. Given the current progress in this field, it is imperative to conduct a comprehensive survey of data structures, models, and applications related to geometric GNNs. In this paper, based on the necessary but concise mathematical preliminaries, we provide a unified view of existing models from the geometric message passing perspective. Additionally, we summarize the applications as well as the related datasets to facilitate later research for methodology development and experimental evaluation. We also discuss the challenges and future potential directions of Geometric GNNs at the end of this survey.
Sliceformer: Make Multi-head Attention as Simple as Sorting in Discriminative Tasks
Oct 26, 2023



As one of the most popular neural network modules, Transformer plays a central role in many fundamental deep learning models, e.g., the ViT in computer vision and the BERT and GPT in natural language processing. The effectiveness of the Transformer is often attributed to its multi-head attention (MHA) mechanism. In this study, we discuss the limitations of MHA, including the high computational complexity due to its ``query-key-value'' architecture and the numerical issue caused by its softmax operation. Considering the above problems and the recent development tendency of the attention layer, we propose an effective and efficient surrogate of the Transformer, called Sliceformer. Our Sliceformer replaces the classic MHA mechanism with an extremely simple ``slicing-sorting'' operation, i.e., projecting inputs linearly to a latent space and sorting them along different feature dimensions (or equivalently, called channels). For each feature dimension, the sorting operation implicitly generates an implicit attention map with sparse, full-rank, and doubly-stochastic structures. We consider different implementations of the slicing-sorting operation and analyze their impacts on the Sliceformer. We test the Sliceformer in the Long-Range Arena benchmark, image classification, text classification, and molecular property prediction, demonstrating its advantage in computational complexity and universal effectiveness in discriminative tasks. Our Sliceformer achieves comparable or better performance with lower memory cost and faster speed than the Transformer and its variants. Moreover, the experimental results reveal that applying our Sliceformer can empirically suppress the risk of mode collapse when representing data. The code is available at \url{https://github.com/SDS-Lab/sliceformer}.
A Quasi-Wasserstein Loss for Learning Graph Neural Networks
Oct 19, 2023When learning graph neural networks (GNNs) in node-level prediction tasks, most existing loss functions are applied for each node independently, even if node embeddings and their labels are non-i.i.d. because of their graph structures. To eliminate such inconsistency, in this study we propose a novel Quasi-Wasserstein (QW) loss with the help of the optimal transport defined on graphs, leading to new learning and prediction paradigms of GNNs. In particular, we design a "Quasi-Wasserstein" distance between the observed multi-dimensional node labels and their estimations, optimizing the label transport defined on graph edges. The estimations are parameterized by a GNN in which the optimal label transport may determine the graph edge weights optionally. By reformulating the strict constraint of the label transport to a Bregman divergence-based regularizer, we obtain the proposed Quasi-Wasserstein loss associated with two efficient solvers learning the GNN together with optimal label transport. When predicting node labels, our model combines the output of the GNN with the residual component provided by the optimal label transport, leading to a new transductive prediction paradigm. Experiments show that the proposed QW loss applies to various GNNs and helps to improve their performance in node-level classification and regression tasks.
DHOT-GM: Robust Graph Matching Using A Differentiable Hierarchical Optimal Transport Framework
Oct 18, 2023



Graph matching is one of the most significant graph analytic tasks in practice, which aims to find the node correspondence across different graphs. Most existing approaches rely on adjacency matrices or node embeddings when matching graphs, whose performances are often sub-optimal because of not fully leveraging the multi-modal information hidden in graphs, such as node attributes, subgraph structures, etc. In this study, we propose a novel and effective graph matching method based on a differentiable hierarchical optimal transport (HOT) framework, called DHOT-GM. Essentially, our method represents each graph as a set of relational matrices corresponding to the information of different modalities. Given two graphs, we enumerate all relational matrix pairs and obtain their matching results, and accordingly, infer the node correspondence by the weighted averaging of the matching results. This method can be implemented as computing the HOT distance between the two graphs -- each matching result is an optimal transport plan associated with the Gromov-Wasserstein (GW) distance between two relational matrices, and the weights of all matching results are the elements of an upper-level optimal transport plan defined on the matrix sets. We propose a bi-level optimization algorithm to compute the HOT distance in a differentiable way, making the significance of the relational matrices adjustable. Experiments on various graph matching tasks demonstrate the superiority and robustness of our method compared to state-of-the-art approaches.
Decentralized Entropic Optimal Transport for Privacy-preserving Distributed Distribution Comparison
Jan 28, 2023



Privacy-preserving distributed distribution comparison measures the distance between the distributions whose data are scattered across different agents in a distributed system and cannot be shared among the agents. In this study, we propose a novel decentralized entropic optimal transport (EOT) method, which provides a privacy-preserving and communication-efficient solution to this problem with theoretical guarantees. In particular, we design a mini-batch randomized block-coordinate descent (MRBCD) scheme to optimize the decentralized EOT distance in its dual form. The dual variables are scattered across different agents and updated locally and iteratively with limited communications among partial agents. The kernel matrix involved in the gradients of the dual variables is estimated by a distributed kernel approximation method, and each agent only needs to approximate and store a sub-kernel matrix by one-shot communication and without sharing raw data. We analyze our method's communication complexity and provide a theoretical bound for the approximation error caused by the convergence error, the approximated kernel, and the mismatch between the storage and communication protocols. Experiments on synthetic data and real-world distributed domain adaptation tasks demonstrate the effectiveness of our method.
Text2Poster: Laying out Stylized Texts on Retrieved Images
Jan 06, 2023



Poster generation is a significant task for a wide range of applications, which is often time-consuming and requires lots of manual editing and artistic experience. In this paper, we propose a novel data-driven framework, called \textit{Text2Poster}, to automatically generate visually-effective posters from textual information. Imitating the process of manual poster editing, our framework leverages a large-scale pretrained visual-textual model to retrieve background images from given texts, lays out the texts on the images iteratively by cascaded auto-encoders, and finally, stylizes the texts by a matching-based method. We learn the modules of the framework by weakly- and self-supervised learning strategies, mitigating the demand for labeled data. Both objective and subjective experiments demonstrate that our Text2Poster outperforms state-of-the-art methods, including academic research and commercial software, on the quality of generated posters.
Regularized Optimal Transport Layers for Generalized Global Pooling Operations
Dec 13, 2022



Global pooling is one of the most significant operations in many machine learning models and tasks, which works for information fusion and structured data (like sets and graphs) representation. However, without solid mathematical fundamentals, its practical implementations often depend on empirical mechanisms and thus lead to sub-optimal, even unsatisfactory performance. In this work, we develop a novel and generalized global pooling framework through the lens of optimal transport. The proposed framework is interpretable from the perspective of expectation-maximization. Essentially, it aims at learning an optimal transport across sample indices and feature dimensions, making the corresponding pooling operation maximize the conditional expectation of input data. We demonstrate that most existing pooling methods are equivalent to solving a regularized optimal transport (ROT) problem with different specializations, and more sophisticated pooling operations can be implemented by hierarchically solving multiple ROT problems. Making the parameters of the ROT problem learnable, we develop a family of regularized optimal transport pooling (ROTP) layers. We implement the ROTP layers as a new kind of deep implicit layer. Their model architectures correspond to different optimization algorithms. We test our ROTP layers in several representative set-level machine learning scenarios, including multi-instance learning (MIL), graph classification, graph set representation, and image classification. Experimental results show that applying our ROTP layers can reduce the difficulty of the design and selection of global pooling -- our ROTP layers may either imitate some existing global pooling methods or lead to some new pooling layers fitting data better. The code is available at \url{https://github.com/SDS-Lab/ROT-Pooling}.
Predicting Protein-Ligand Binding Affinity via Joint Global-Local Interaction Modeling
Sep 18, 2022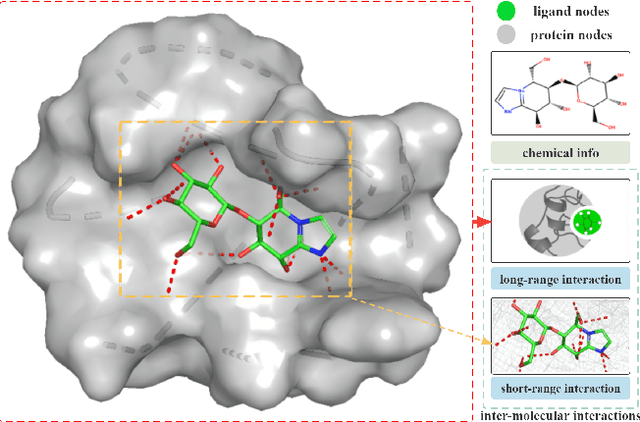
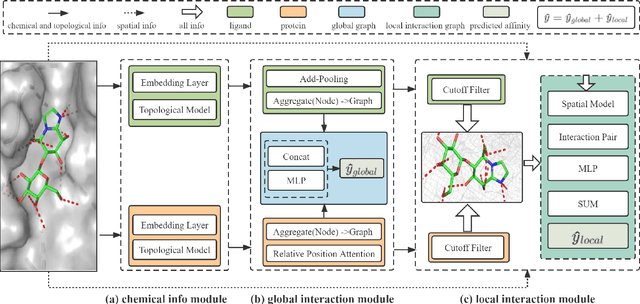
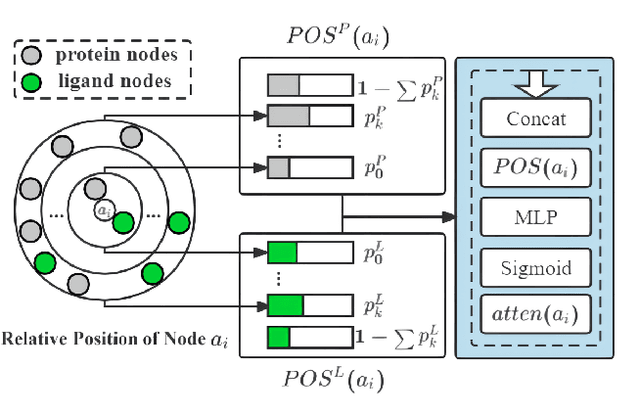
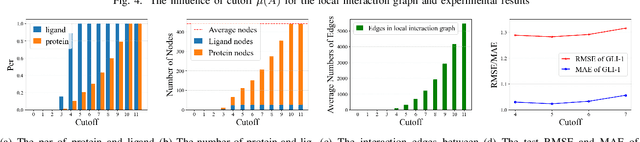
The prediction of protein-ligand binding affinity is of great significance for discovering lead compounds in drug research. Facing this challenging task, most existing prediction methods rely on the topological and/or spatial structure of molecules and the local interactions while ignoring the multi-level inter-molecular interactions between proteins and ligands, which often lead to sub-optimal performance. To solve this issue, we propose a novel global-local interaction (GLI) framework to predict protein-ligand binding affinity. In particular, our GLI framework considers the inter-molecular interactions between proteins and ligands, which involve not only the high-energy short-range interactions between closed atoms but also the low-energy long-range interactions between non-bonded atoms. For each pair of protein and ligand, our GLI embeds the long-range interactions globally and aggregates local short-range interactions, respectively. Such a joint global-local interaction modeling strategy helps to improve prediction accuracy, and the whole framework is compatible with various neural network-based modules. Experiments demonstrate that our GLI framework outperforms state-of-the-art methods with simple neural network architectures and moderate computational costs.
ImDrug: A Benchmark for Deep Imbalanced Learning in AI-aided Drug Discovery
Sep 16, 2022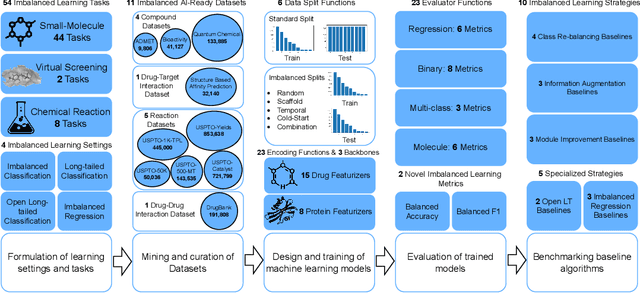

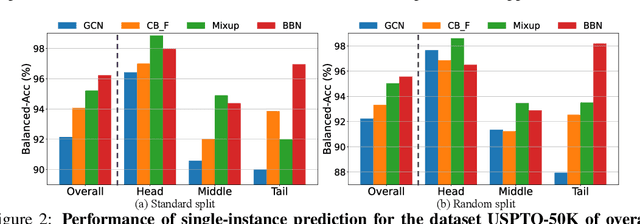
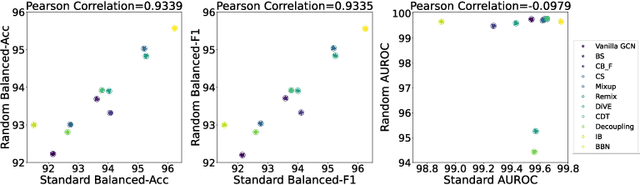
The last decade has witnessed a prosperous development of computational methods and dataset curation for AI-aided drug discovery (AIDD). However, real-world pharmaceutical datasets often exhibit highly imbalanced distribution, which is largely overlooked by the current literature but may severely compromise the fairness and generalization of machine learning applications. Motivated by this observation, we introduce ImDrug, a comprehensive benchmark with an open-source Python library which consists of 4 imbalance settings, 11 AI-ready datasets, 54 learning tasks and 16 baseline algorithms tailored for imbalanced learning. It provides an accessible and customizable testbed for problems and solutions spanning a broad spectrum of the drug discovery pipeline such as molecular modeling, drug-target interaction and retrosynthesis. We conduct extensive empirical studies with novel evaluation metrics, to demonstrate that the existing algorithms fall short of solving medicinal and pharmaceutical challenges in the data imbalance scenario. We believe that ImDrug opens up avenues for future research and development, on real-world challenges at the intersection of AIDD and deep imbalanced learning.
Explainable Legal Case Matching via Inverse Optimal Transport-based Rationale Extraction
Jul 09, 2022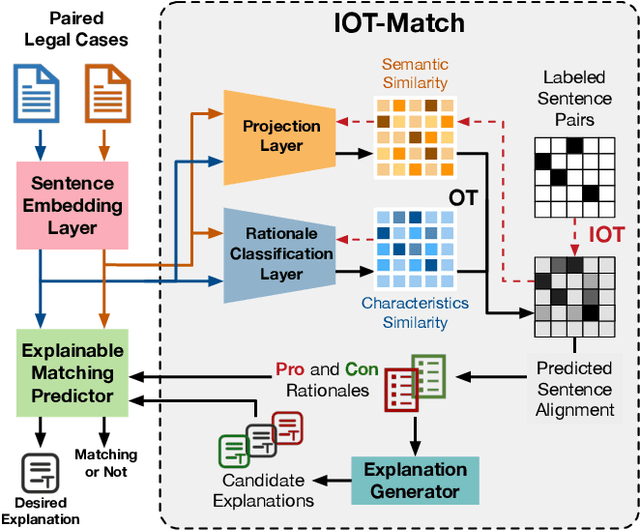
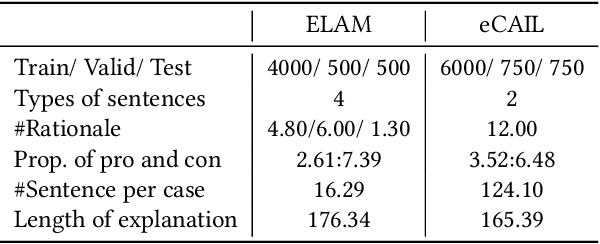

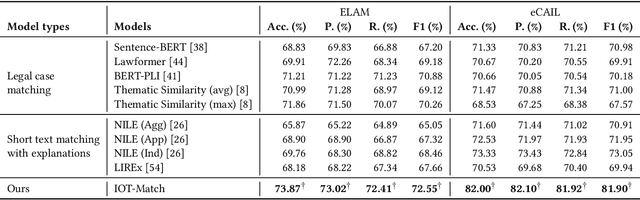
As an essential operation of legal retrieval, legal case matching plays a central role in intelligent legal systems. This task has a high demand on the explainability of matching results because of its critical impacts on downstream applications -- the matched legal cases may provide supportive evidence for the judgments of target cases and thus influence the fairness and justice of legal decisions. Focusing on this challenging task, we propose a novel and explainable method, namely \textit{IOT-Match}, with the help of computational optimal transport, which formulates the legal case matching problem as an inverse optimal transport (IOT) problem. Different from most existing methods, which merely focus on the sentence-level semantic similarity between legal cases, our IOT-Match learns to extract rationales from paired legal cases based on both semantics and legal characteristics of their sentences. The extracted rationales are further applied to generate faithful explanations and conduct matching. Moreover, the proposed IOT-Match is robust to the alignment label insufficiency issue commonly in practical legal case matching tasks, which is suitable for both supervised and semi-supervised learning paradigms. To demonstrate the superiority of our IOT-Match method and construct a benchmark of explainable legal case matching task, we not only extend the well-known Challenge of AI in Law (CAIL) dataset but also build a new Explainable Legal cAse Matching (ELAM) dataset, which contains lots of legal cases with detailed and explainable annotations. Experiments on these two datasets show that our IOT-Match outperforms state-of-the-art methods consistently on matching prediction, rationale extraction, and explanation generation.