 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Molecular Ground-State Conformation via Conformation Optimization
Oct 13, 2024



Predicting ground-state conformation from the corresponding molecular graph is crucial for many chemical applications, such as molecular modeling, molecular docking, and molecular property prediction. Recently, many learning-based methods have been proposed to replace time-consuming simulations for this task. However, these methods are often inefficient and sub-optimal as they merely rely on molecular graph information to make predictions from scratch. In this work, considering that molecular low-quality conformations are readily available, we propose a novel framework called ConfOpt to predict molecular ground-state conformation from the perspective of conformation optimization. Specifically, ConfOpt takes the molecular graph and corresponding low-quality 3D conformation as inputs, and then derives the ground-state conformation by iteratively optimizing the low-quality conformation under the guidance of the molecular graph. During training, ConfOpt concurrently optimizes the predicted atomic 3D coordinates and the corresponding interatomic distances, resulting in a strong predictive model. Extensive experiments demonstrate that ConfOpt significantly outperforms existing methods, thus providing a new paradigm for efficiently and accurately predicting molecular ground-state conformation.
Predicting Polymer Properties Based on Multimodal Multitask Pretraining
Jun 07, 2024In the past few decades, polymers, high-molecular-weight compounds formed by bonding numerous identical or similar monomers covalently, have played an essential role in various scientific fields. In this context, accurate prediction of their properties is becoming increasingly crucial. Typically, the properties of a polymer, such as plasticity, conductivity, bio-compatibility, and so on, are highly correlated with its 3D structure. However, current methods for predicting polymer properties heavily rely on information from polymer SMILES sequences (P-SMILES strings) while ignoring crucial 3D structural information, leading to sub-optimal performance. In this work, we propose MMPolymer, a novel multimodal multitask pretraining framework incorporating both polymer 1D sequential information and 3D structural information to enhance downstream polymer property prediction tasks. Besides, to overcome the limited availability of polymer 3D data, we further propose the "Star Substitution" strategy to extract 3D structural information effectively. During pretraining, MMPolymer not only predicts masked tokens and recovers 3D coordinates but also achieves the cross-modal alignment of latent representation. Subsequently, we further fine-tune the pretrained MMPolymer for downstream polymer property prediction tasks in the supervised learning paradigm. Experimental results demonstrate that MMPolymer achieves state-of-the-art performance in various polymer property prediction tasks. Moreover, leveraging the pretrained MMPolymer and using only one modality (either P-SMILES string or 3D conformation) during fine-tuning can also surpass existing polymer property prediction methods, highlighting the exceptional capability of MMPolymer in polymer feature extraction and utilization. Our online platform for polymer property prediction is available at https://app.bohrium.dp.tech/mmpolymer.
A Quasi-Wasserstein Loss for Learning Graph Neural Networks
Oct 19, 2023When learning graph neural networks (GNNs) in node-level prediction tasks, most existing loss functions are applied for each node independently, even if node embeddings and their labels are non-i.i.d. because of their graph structures. To eliminate such inconsistency, in this study we propose a novel Quasi-Wasserstein (QW) loss with the help of the optimal transport defined on graphs, leading to new learning and prediction paradigms of GNNs. In particular, we design a "Quasi-Wasserstein" distance between the observed multi-dimensional node labels and their estimations, optimizing the label transport defined on graph edges. The estimations are parameterized by a GNN in which the optimal label transport may determine the graph edge weights optionally. By reformulating the strict constraint of the label transport to a Bregman divergence-based regularizer, we obtain the proposed Quasi-Wasserstein loss associated with two efficient solvers learning the GNN together with optimal label transport. When predicting node labels, our model combines the output of the GNN with the residual component provided by the optimal label transport, leading to a new transductive prediction paradigm. Experiments show that the proposed QW loss applies to various GNNs and helps to improve their performance in node-level classification and regression tasks.
Regularized Optimal Transport Layers for Generalized Global Pooling Operations
Dec 13, 2022



Global pooling is one of the most significant operations in many machine learning models and tasks, which works for information fusion and structured data (like sets and graphs) representation. However, without solid mathematical fundamentals, its practical implementations often depend on empirical mechanisms and thus lead to sub-optimal, even unsatisfactory performance. In this work, we develop a novel and generalized global pooling framework through the lens of optimal transport. The proposed framework is interpretable from the perspective of expectation-maximization. Essentially, it aims at learning an optimal transport across sample indices and feature dimensions, making the corresponding pooling operation maximize the conditional expectation of input data. We demonstrate that most existing pooling methods are equivalent to solving a regularized optimal transport (ROT) problem with different specializations, and more sophisticated pooling operations can be implemented by hierarchically solving multiple ROT problems. Making the parameters of the ROT problem learnable, we develop a family of regularized optimal transport pooling (ROTP) layers. We implement the ROTP layers as a new kind of deep implicit layer. Their model architectures correspond to different optimization algorithms. We test our ROTP layers in several representative set-level machine learning scenarios, including multi-instance learning (MIL), graph classification, graph set representation, and image classification. Experimental results show that applying our ROTP layers can reduce the difficulty of the design and selection of global pooling -- our ROTP layers may either imitate some existing global pooling methods or lead to some new pooling layers fitting data better. The code is available at \url{https://github.com/SDS-Lab/ROT-Pooling}.
Revisiting Pooling through the Lens of Optimal Transport
Jan 23, 2022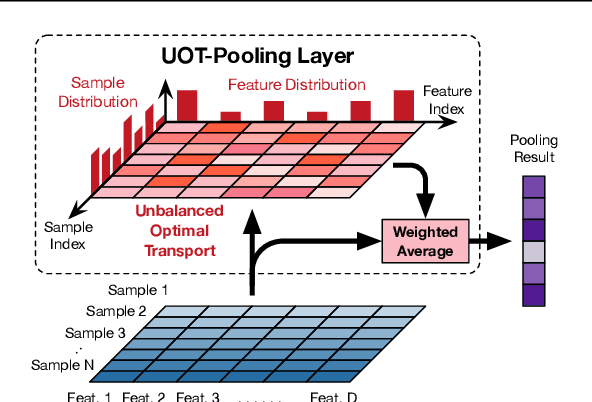
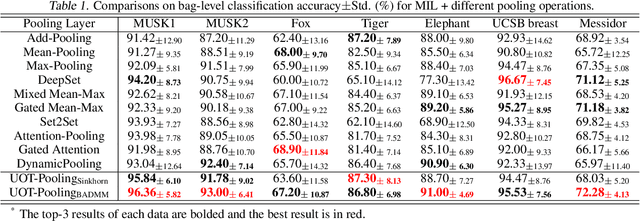

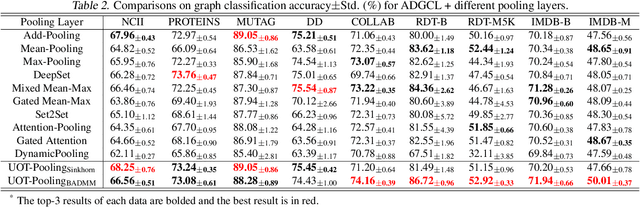
Pooling is one of the most significant operations in many machine learning models and tasks, whose implementation, however, is often empirical in practice. In this paper, we develop a novel and solid algorithmic pooling framework through the lens of optimal transport. In particular, we demonstrate that most existing pooling methods are equivalent to solving some specializations of an unbalanced optimal transport (UOT) problem. Making the parameters of the UOT problem learnable, we unify most existing pooling methods in the same framework, and accordingly, propose a generalized pooling layer called \textit{UOT-Pooling} for neural networks. Moreover, we implement the UOT-Pooling with two different architectures, based on the Sinkhorn scaling algorithm and the Bregman ADMM algorithm, respectively, and study their stability and efficiency quantitatively. We test our UOT-Pooling layers in two application scenarios, including multi-instance learning (MIL) and graph embedding. For state-of-the-art models of these two tasks, we can improve their performance by replacing conventional pooling layers with our UOT-Pooling layers.