 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Sparse-Reward Object-Interaction Tasks in First-person Simulated 3D Environments
Oct 28, 2020
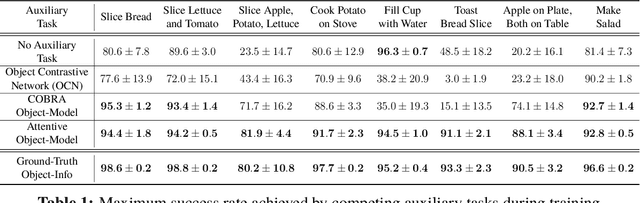
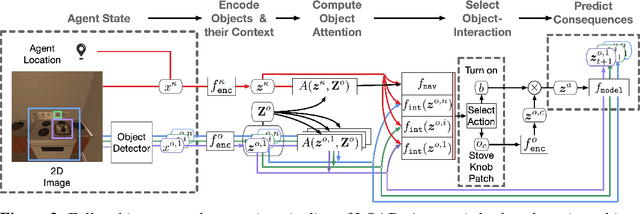
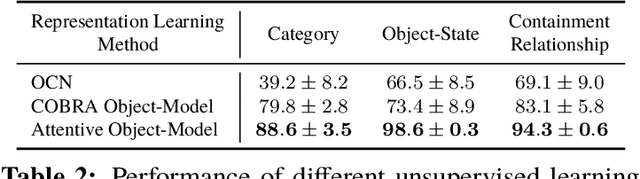
First-person object-interaction tasks in high-fidelity, 3D, simulated environments such as the AI2Thor virtual home-environment pose significant sample-efficiency challenges for reinforcement learning (RL) agents learning from sparse task rewards. To alleviate these challenges, prior work has provided extensive supervision via a combination of reward-shaping, ground-truth object-information, and expert demonstrations. In this work, we show that one can learn object-interaction tasks from scratch without supervision by learning an attentive object-model as an auxiliary task during task learning with an object-centric relational RL agent. Our key insight is that learning an object-model that incorporates object-attention into forward prediction provides a dense learning signal for unsupervised representation learning of both objects and their relationships. This, in turn, enables faster policy learning for an object-centric relational RL agent. We demonstrate our agent by introducing a set of challenging object-interaction tasks in the AI2Thor environment where learning with our attentive object-model is key to strong performance. Specifically, we compare our agent and relational RL agents with alternative auxiliary tasks to a relational RL agent equipped with ground-truth object-information, and show that learning with our object-model best closes the performance gap in terms of both learning speed and maximum success rate. Additionally, we find that incorporating object-attention into an object-model's forward predictions is key to learning representations which capture object-category and object-state.
Bridging Imagination and Reality for Model-Based Deep Reinforcement Learning
Oct 23, 2020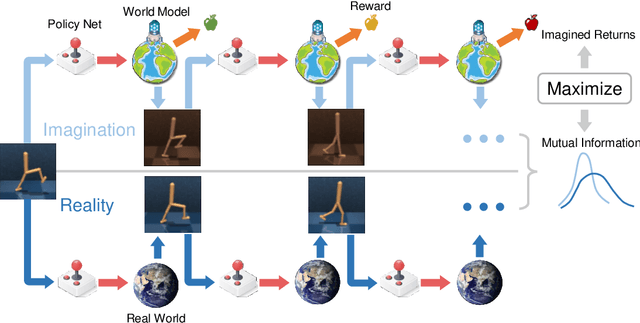
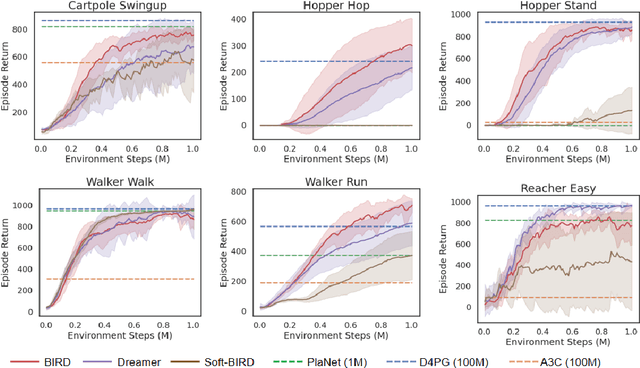
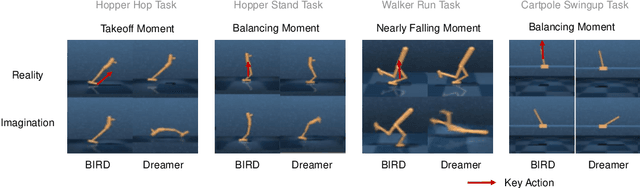
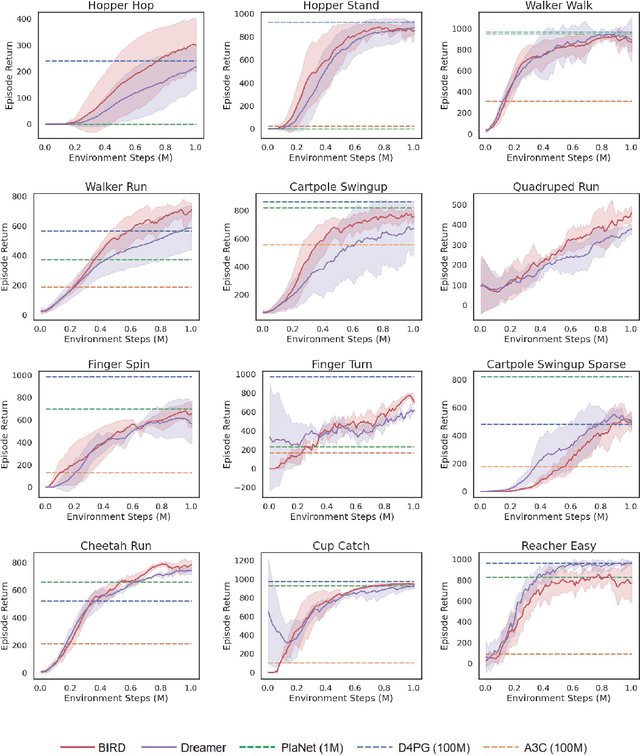
Sample efficiency has been one of the major challenges for deep reinforcement learning. Recently, model-based reinforcement learning has been proposed to address this challenge by performing planning on imaginary trajectories with a learned world model. However, world model learning may suffer from overfitting to training trajectories, and thus model-based value estimation and policy search will be pone to be sucked in an inferior local policy. In this paper, we propose a novel model-based reinforcement learning algorithm, called BrIdging Reality and Dream (BIRD). It maximizes the mutual information between imaginary and real trajectories so that the policy improvement learned from imaginary trajectories can be easily generalized to real trajectories. We demonstrate that our approach improves sample efficiency of model-based planning, and achieves state-of-the-art performance on challenging visual control benchmarks.
i-Mix: A Strategy for Regularizing Contrastive Representation Learning
Oct 17, 2020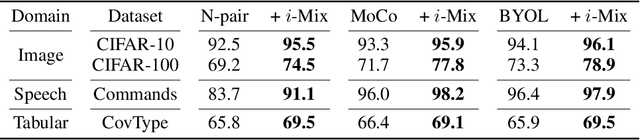
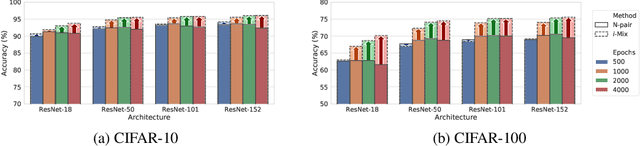
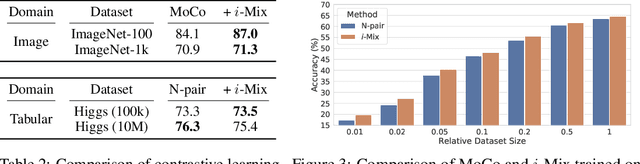

Contrastive representation learning has shown to be an effective way of learning representations from unlabeled data. However, much progress has been made in vision domains relying on data augmentations carefully designed using domain knowledge. In this work, we propose i-Mix, a simple yet effective regularization strategy for improving contrastive representation learning in both vision and non-vision domains. We cast contrastive learning as training a non-parametric classifier by assigning a unique virtual class to each data in a batch. Then, data instances are mixed in both the input and virtual label spaces, providing more augmented data during training. In experiments, we demonstrate that i-Mix consistently improves the quality of self-supervised representations across domains, resulting in significant performance gains on downstream tasks. Furthermore, we confirm its regularization effect via extensive ablation studies across model and dataset sizes.
Text as Neural Operator: Image Manipulation by Text Instruction
Aug 12, 2020
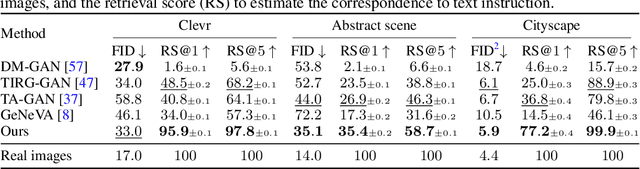
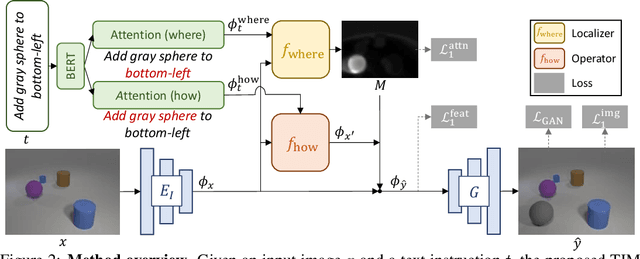
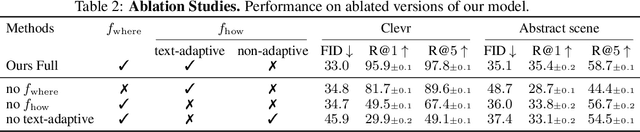
In this paper, we study a new task that allows users to edit an input image using language instructions. In this image generation task, the inputs are a reference image and a text instruction that describes desired modifications to the input image. We propose a GAN-based method to tackle this problem. The key idea is to treat language as neural operators to locally modify the image feature. To this end, our model decomposes the generation process into finding where (spatial region) and how (text operators) to apply modifications. We show that the proposed model performs favorably against recent baselines on three datasets.
Predictive Information Accelerates Learning in RL
Jul 24, 2020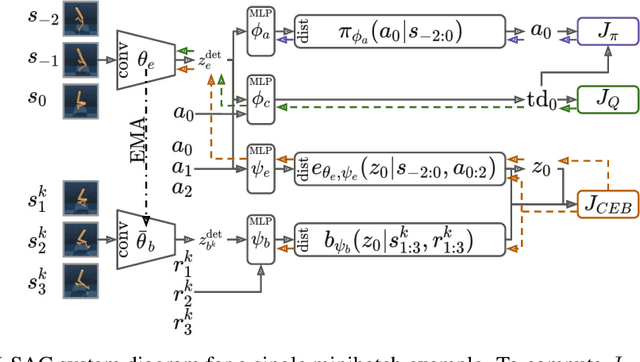
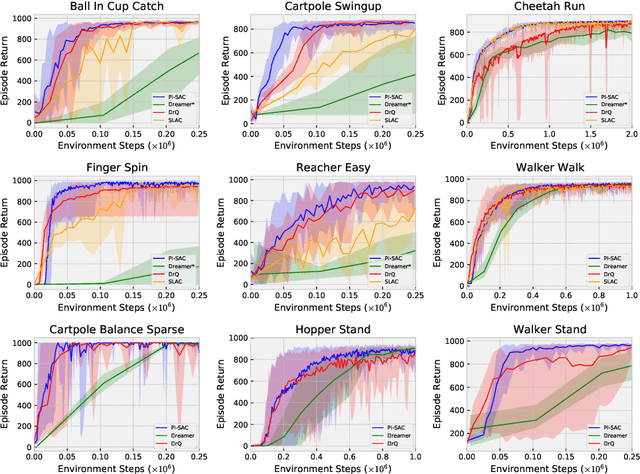
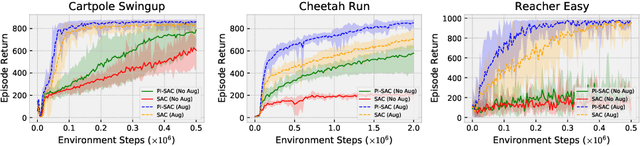
The Predictive Information is the mutual information between the past and the future, I(X_past; X_future). We hypothesize that capturing the predictive information is useful in RL, since the ability to model what will happen next is necessary for success on many tasks. To test our hypothesis, we train Soft Actor-Critic (SAC) agents from pixels with an auxiliary task that learns a compressed representation of the predictive information of the RL environment dynamics using a contrastive version of the Conditional Entropy Bottleneck (CEB) objective. We refer to these as Predictive Information SAC (PI-SAC) agents. We show that PI-SAC agents can substantially improve sample efficiency over challenging baselines on tasks from the DM Control suite of continuous control environments. We evaluate PI-SAC agents by comparing against uncompressed PI-SAC agents, other compressed and uncompressed agents, and SAC agents directly trained from pixels.
Understanding and Diagnosing Vulnerability under Adversarial Attacks
Jul 17, 2020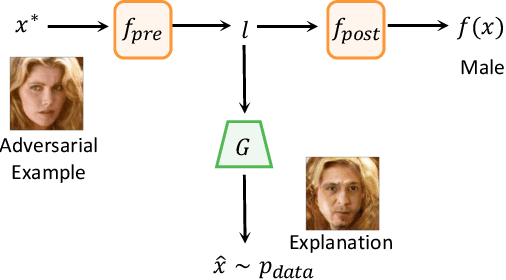
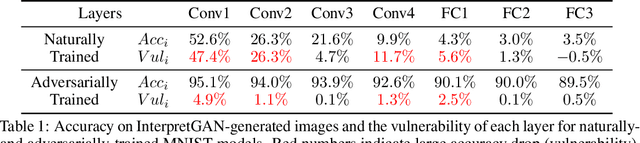
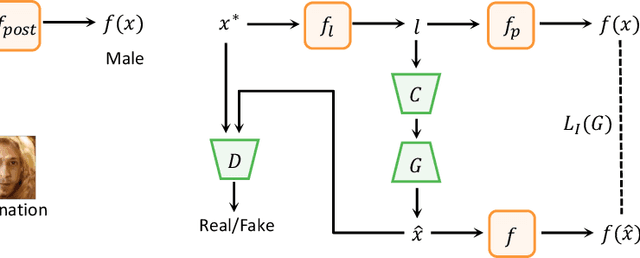
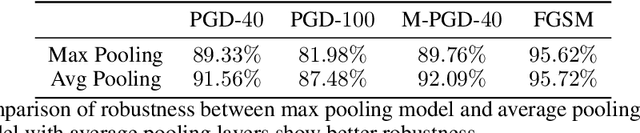
Deep Neural Networks (DNNs) are known to be vulnerable to adversarial attacks. Currently, there is no clear insight into how slight perturbations cause such a large difference in classification results and how we can design a more robust model architecture. In this work, we propose a novel interpretability method, InterpretGAN, to generate explanations for features used for classification in latent variables. Interpreting the classification process of adversarial examples exposes how adversarial perturbations influence features layer by layer as well as which features are modified by perturbations. Moreover, we design the first diagnostic method to quantify the vulnerability contributed by each layer, which can be used to identify vulnerable parts of model architectures. The diagnostic results show that the layers introducing more information loss tend to be more vulnerable than other layers. Based on the findings, our evaluation results on MNIST and CIFAR10 datasets suggest that average pooling layers, with lower information loss, are more robust than max pooling layers for the network architectures studied in this paper.
An Ode to an ODE
Jun 23, 2020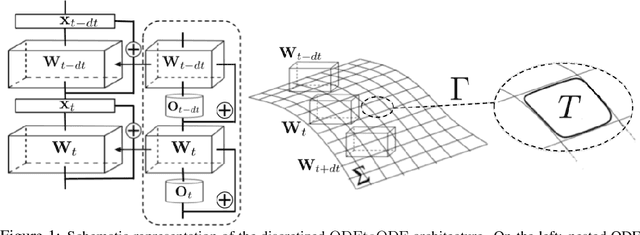
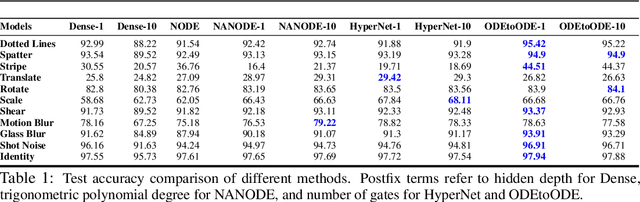
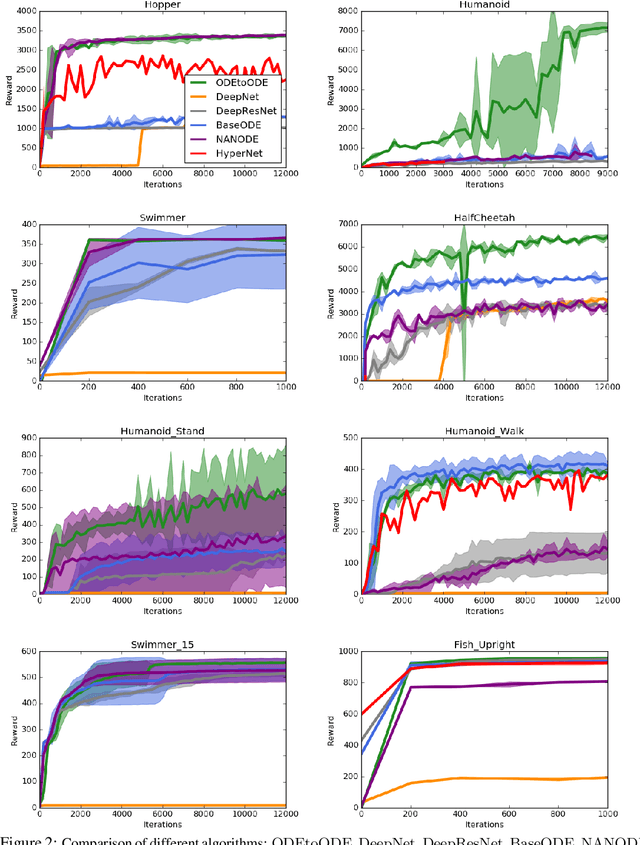
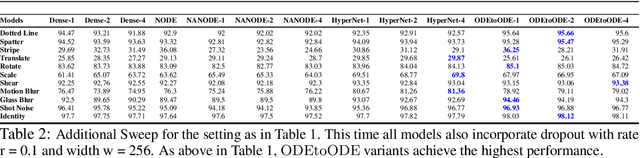
We present a new paradigm for Neural ODE algorithms, called ODEtoODE, where time-dependent parameters of the main flow evolve according to a matrix flow on the orthogonal group O(d). This nested system of two flows, where the parameter-flow is constrained to lie on the compact manifold, provides stability and effectiveness of training and provably solves the gradient vanishing-explosion problem which is intrinsically related to training deep neural network architectures such as Neural ODEs. Consequently, it leads to better downstream models, as we show on the example of training reinforcement learning policies with evolution strategies, and in the supervised learning setting, by comparing with previous SOTA baselines. We provide strong convergence results for our proposed mechanism that are independent of the depth of the network, supporting our empirical studies. Our results show an intriguing connection between the theory of deep neural networks and the field of matrix flows on compact manifolds.
CompressNet: Generative Compression at Extremely Low Bitrates
Jun 14, 2020
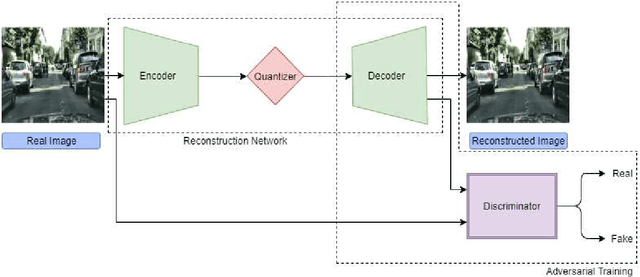
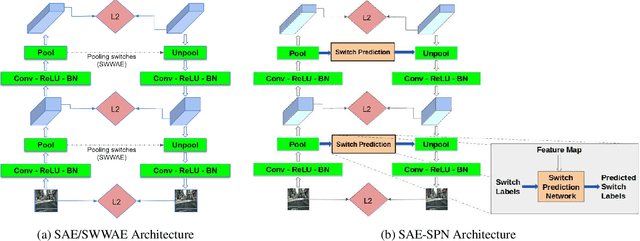

Compressing images at extremely low bitrates (< 0.1 bpp) has always been a challenging task since the quality of reconstruction significantly reduces due to the strong imposed constraint on the number of bits allocated for the compressed data. With the increasing need to transfer large amounts of images with limited bandwidth, compressing images to very low sizes is a crucial task. However, the existing methods are not effective at extremely low bitrates. To address this need, we propose a novel network called CompressNet which augments a Stacked Autoencoder with a Switch Prediction Network (SAE-SPN). This helps in the reconstruction of visually pleasing images at these low bitrates (< 0.1 bpp). We benchmark the performance of our proposed method on the Cityscapes dataset, evaluating over different metrics at extremely low bitrates to show that our method outperforms the other state-of-the-art. In particular, at a bitrate of 0.07, CompressNet achieves 22% lower Perceptual Loss and 55% lower Frechet Inception Distance (FID) compared to the deep learning SOTA methods.
Context-aware Dynamics Model for Generalization in Model-Based Reinforcement Learning
May 14, 2020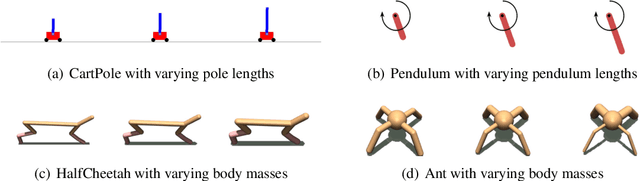

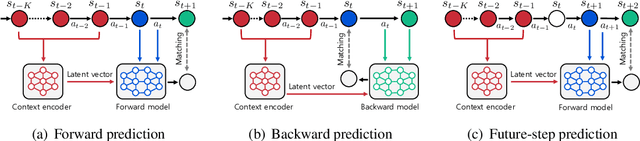
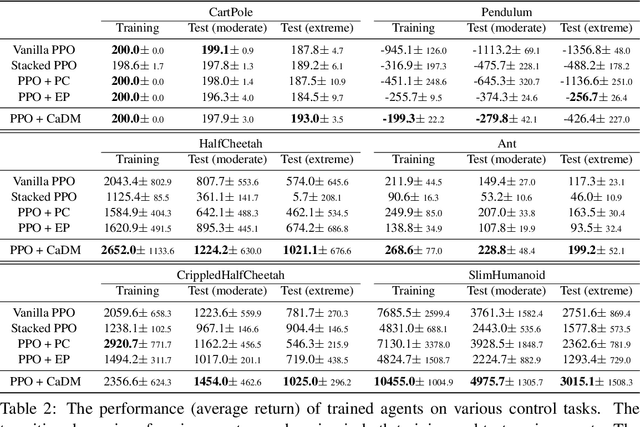
Model-based reinforcement learning (RL) enjoys several benefits, such as data-efficiency and planning, by learning a model of the environment's dynamics. However, learning a global model that can generalize across different dynamics is a challenging task. To tackle this problem, we decompose the task of learning a global dynamics model into two stages: (a) learning a context latent vector that captures the local dynamics, then (b) predicting the next state conditioned on it. In order to encode dynamics-specific information into the context latent vector, we introduce a novel loss function that encourages the context latent vector to be useful for predicting both forward and backward dynamics. The proposed method achieves superior generalization ability across various simulated robotics and control tasks, compared to existing RL schemes.
Time Dependence in Non-Autonomous Neural ODEs
May 06, 2020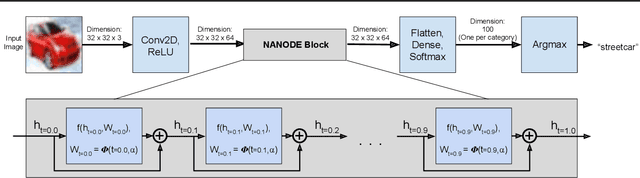
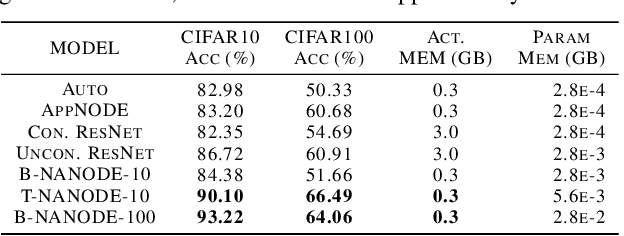
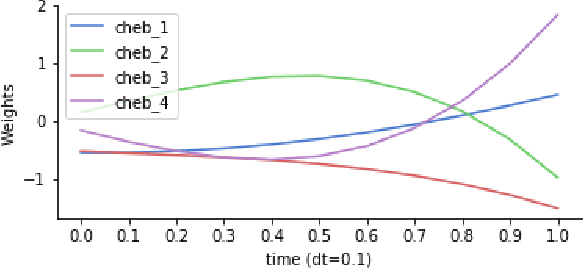
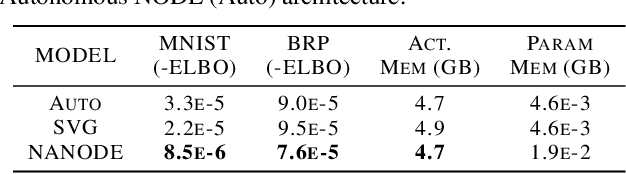
Neural Ordinary Differential Equations (ODEs) are elegant reinterpretations of deep networks where continuous time can replace the discrete notion of depth, ODE solvers perform forward propagation, and the adjoint method enables efficient, constant memory backpropagation. Neural ODEs are universal approximators only when they are non-autonomous, that is, the dynamics depends explicitly on time. We propose a novel family of Neural ODEs with time-varying weights, where time-dependence is non-parametric, and the smoothness of weight trajectories can be explicitly controlled to allow a tradeoff between expressiveness and efficiency. Using this enhanced expressiveness, we outperform previous Neural ODE variants in both speed and representational capacity, ultimately outperforming standard ResNet and CNN models on select image classification and video prediction tasks.