 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressNet: Generative Compression at Extremely Low Bitrates
Jun 14, 2020
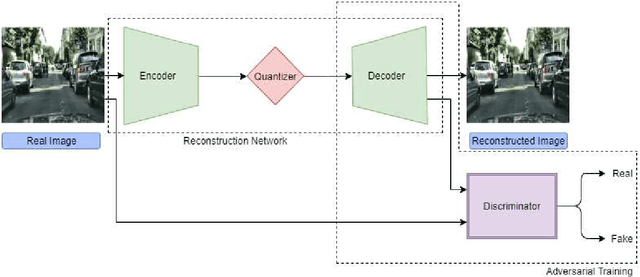
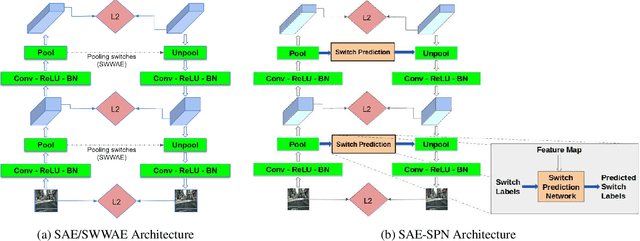

Compressing images at extremely low bitrates (< 0.1 bpp) has always been a challenging task since the quality of reconstruction significantly reduces due to the strong imposed constraint on the number of bits allocated for the compressed data. With the increasing need to transfer large amounts of images with limited bandwidth, compressing images to very low sizes is a crucial task. However, the existing methods are not effective at extremely low bitrates. To address this need, we propose a novel network called CompressNet which augments a Stacked Autoencoder with a Switch Prediction Network (SAE-SPN). This helps in the reconstruction of visually pleasing images at these low bitrates (< 0.1 bpp). We benchmark the performance of our proposed method on the Cityscapes dataset, evaluating over different metrics at extremely low bitrates to show that our method outperforms the other state-of-the-art. In particular, at a bitrate of 0.07, CompressNet achieves 22% lower Perceptual Loss and 55% lower Frechet Inception Distance (FID) compared to the deep learning SOTA methods.
Video based Contextual Question Answering
Apr 19, 2018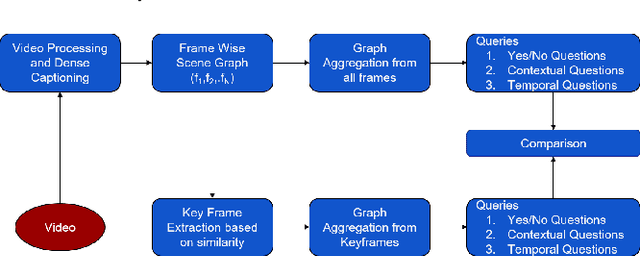
The primary aim of this project is to build a contextual Question-Answering model for videos. The current methodologies provide a robust model for image based Question-Answering, but we are aim to generalize this approach to be videos. We propose a graphical representation of video which is able to handle several types of queries across the whole video. For example, if a frame has an image of a man and a cat sitting, it should be able to handle queries like, where is the cat sitting with respect to the man? or ,what is the man holding in his hand?. It should be able to answer queries relating to temporal relationships also.