 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressNet: Generative Compression at Extremely Low Bitrates
Jun 14, 2020
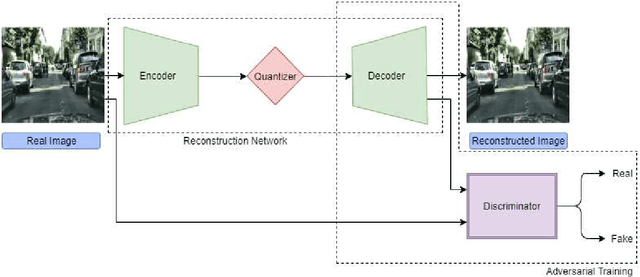
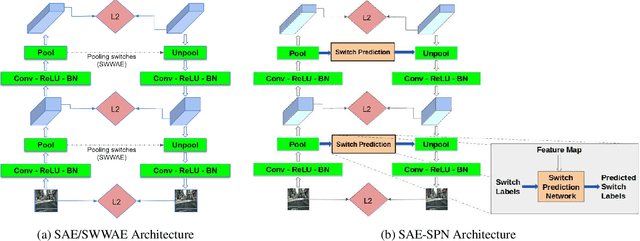

Compressing images at extremely low bitrates (< 0.1 bpp) has always been a challenging task since the quality of reconstruction significantly reduces due to the strong imposed constraint on the number of bits allocated for the compressed data. With the increasing need to transfer large amounts of images with limited bandwidth, compressing images to very low sizes is a crucial task. However, the existing methods are not effective at extremely low bitrates. To address this need, we propose a novel network called CompressNet which augments a Stacked Autoencoder with a Switch Prediction Network (SAE-SPN). This helps in the reconstruction of visually pleasing images at these low bitrates (< 0.1 bpp). We benchmark the performance of our proposed method on the Cityscapes dataset, evaluating over different metrics at extremely low bitrates to show that our method outperforms the other state-of-the-art. In particular, at a bitrate of 0.07, CompressNet achieves 22% lower Perceptual Loss and 55% lower Frechet Inception Distance (FID) compared to the deep learning SOTA methods.
Selfie Detection by Synergy-Constraint Based Convolutional Neural Network
Nov 14, 2016

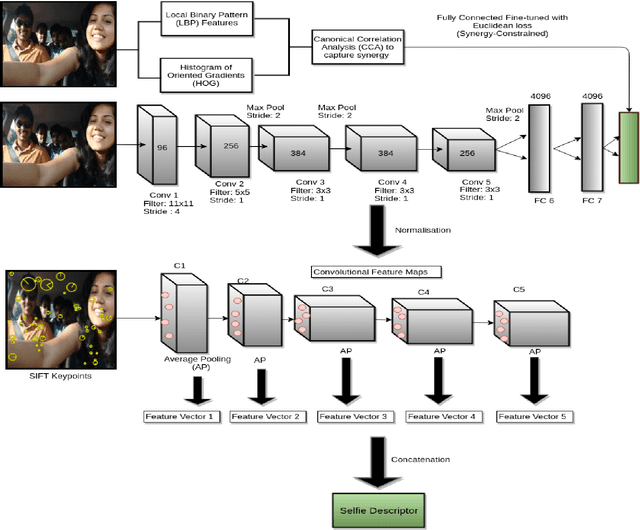

Categorisation of huge amount of data on the multimedia platform is a crucial task. In this work, we propose a novel approach to address the subtle problem of selfie detection for image database segregation on the web, given rapid rise in number of selfies clicked. A Convolutional Neural Network (CNN) is modeled to learn a synergy feature in the common subspace of head and shoulder orientation, derived from Local Binary Pattern (LBP) and Histogram of Oriented Gradients (HOG) features respectively. This synergy was captured by projecting the aforementioned features using Canonical Correlation Analysis (CCA). We show that the resulting network's convolutional activations in the neighbourhood of spatial keypoints captured by SIFT are discriminative for selfie-detection. In general, proposed approach aids in capturing intricacies present in the image data and has the potential for usage in other subtle image analysis scenarios apart from just selfie detection. We investigate and analyse the performance of popular CNN architectures (GoogleNet, AlexNet), used for other image classification tasks, when subjected to the task of detecting the selfies on the multimedia platform. The results of the proposed approach are compared with these popular architectures on a dataset of ninety thousand images comprising of roughly equal number of selfies and non-selfies. Experimental results on this dataset shows the effectiveness of the proposed approach.