 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow Your Work: Scratchpads for Intermediate Computation with Language Models
Nov 30, 2021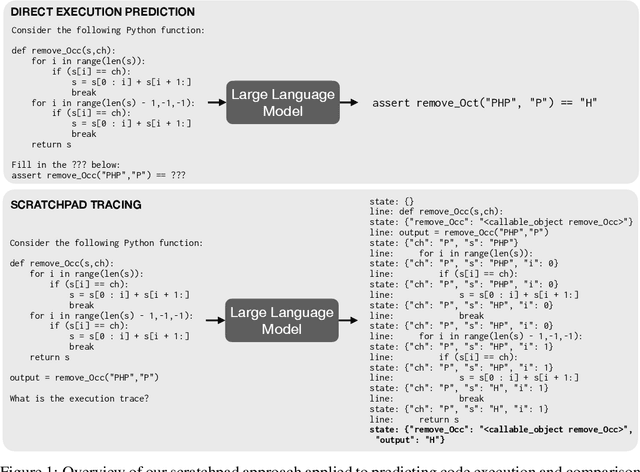

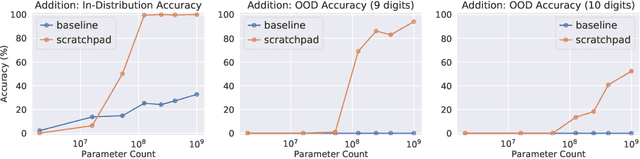

Large pre-trained language models perform remarkably well on tasks that can be done "in one pass", such as generating realistic text or synthesizing computer programs. However, they struggle with tasks that require unbounded multi-step computation, such as adding integers or executing programs. Surprisingly, we find that these same models are able to perform complex multi-step computations -- even in the few-shot regime -- when asked to perform the operation "step by step", showing the results of intermediate computations. In particular, we train transformers to perform multi-step computations by asking them to emit intermediate computation steps into a "scratchpad". On a series of increasingly complex tasks ranging from long addition to the execution of arbitrary programs, we show that scratchpads dramatically improve the ability of language models to perform multi-step computations.
Program Synthesis with Large Language Models
Aug 16, 2021



This paper explores the limits of the current generation of large language models for program synthesis in general purpose programming languages. We evaluate a collection of such models (with between 244M and 137B parameters) on two new benchmarks, MBPP and MathQA-Python, in both the few-shot and fine-tuning regimes. Our benchmarks are designed to measure the ability of these models to synthesize short Python programs from natural language descriptions. The Mostly Basic Programming Problems (MBPP) dataset contains 974 programming tasks, designed to be solvable by entry-level programmers. The MathQA-Python dataset, a Python version of the MathQA benchmark, contains 23914 problems that evaluate the ability of the models to synthesize code from more complex text. On both datasets, we find that synthesis performance scales log-linearly with model size. Our largest models, even without finetuning on a code dataset, can synthesize solutions to 59.6 percent of the problems from MBPP using few-shot learning with a well-designed prompt. Fine-tuning on a held-out portion of the dataset improves performance by about 10 percentage points across most model sizes. On the MathQA-Python dataset, the largest fine-tuned model achieves 83.8 percent accuracy. Going further, we study the model's ability to engage in dialog about code, incorporating human feedback to improve its solutions. We find that natural language feedback from a human halves the error rate compared to the model's initial prediction. Additionally, we conduct an error analysis to shed light on where these models fall short and what types of programs are most difficult to generate. Finally, we explore the semantic grounding of these models by fine-tuning them to predict the results of program execution. We find that even our best models are generally unable to predict the output of a program given a specific input.
Learnability and Complexity of Quantum Samples
Oct 22, 2020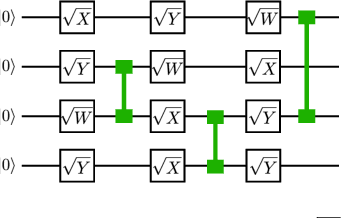
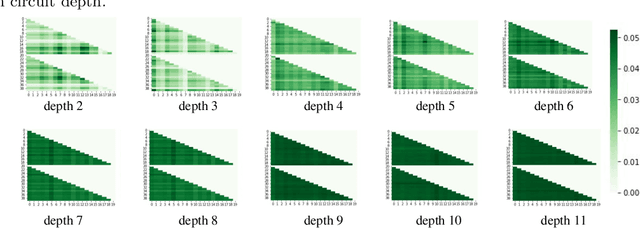
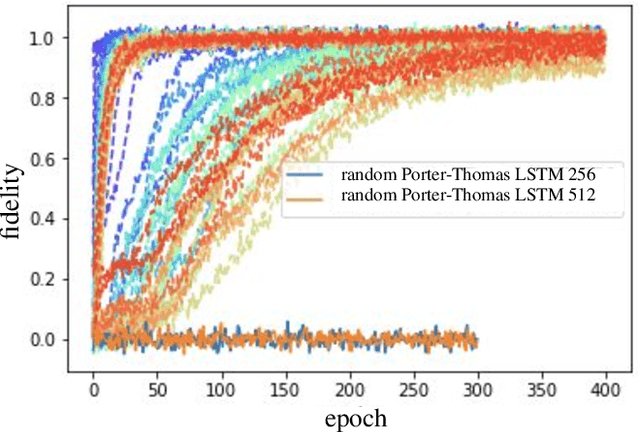
Given a quantum circuit, a quantum computer can sample the output distribution exponentially faster in the number of bits than classical computers. A similar exponential separation has yet to be established in generative models through quantum sample learning: given samples from an n-qubit computation, can we learn the underlying quantum distribution using models with training parameters that scale polynomial in n under a fixed training time? We study four kinds of generative models: Deep Boltzmann machine (DBM), Generative Adversarial Networks (GANs), Long Short-Term Memory (LSTM) and Autoregressive GAN, on learning quantum data set generated by deep random circuits. We demonstrate the leading performance of LSTM in learning quantum samples, and thus the autoregressive structure present in the underlying quantum distribution from random quantum circuits. Both numerical experiments and a theoretical proof in the case of the DBM show exponentially growing complexity of learning-agent parameters required for achieving a fixed accuracy as n increases. Finally, we establish a connection between learnability and the complexity of generative models by benchmarking learnability against different sets of samples drawn from probability distributions of variable degrees of complexities in their quantum and classical representations.
SMYRF: Efficient Attention using Asymmetric Clustering
Oct 11, 2020
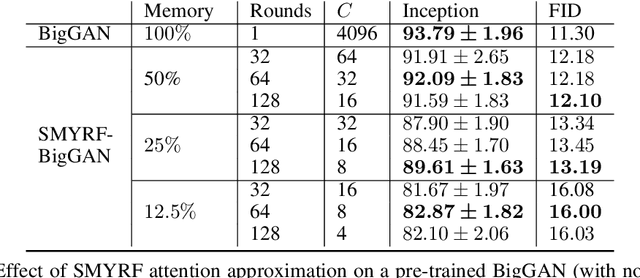


We propose a novel type of balanced clustering algorithm to approximate attention. Attention complexity is reduced from $O(N^2)$ to $O(N \log N)$, where $N$ is the sequence length. Our algorithm, SMYRF, uses Locality Sensitive Hashing (LSH) in a novel way by defining new Asymmetric transformations and an adaptive scheme that produces balanced clusters. The biggest advantage of SMYRF is that it can be used as a drop-in replacement for dense attention layers without any retraining. On the contrary, prior fast attention methods impose constraints (e.g. queries and keys share the same vector representations) and require re-training from scratch. We apply our method to pre-trained state-of-the-art Natural Language Processing and Computer Vision models and we report significant memory and speed benefits. Notably, SMYRF-BERT outperforms (slightly) BERT on GLUE, while using $50\%$ less memory. We also show that SMYRF can be used interchangeably with dense attention before and after training. Finally, we use SMYRF to train GANs with attention in high resolutions. Using a single TPU, we were able to scale attention to 128x128=16k and 256x256=65k tokens on BigGAN on CelebA-HQ.
BUSTLE: Bottom-up program-Synthesis Through Learning-guided Exploration
Jul 28, 2020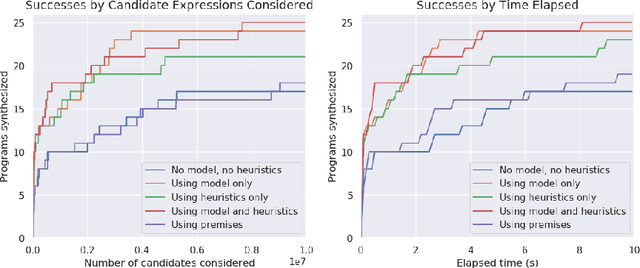
Program synthesis is challenging largely because of the difficulty of search in a large space of programs. Human programmers routinely tackle the task of writing complex programs by writing sub-programs and then analysing their intermediate results to compose them in appropriate ways. Motivated by this intuition, we present a new synthesis approach that leverages learning to guide a bottom-up search over programs. In particular, we train a model to prioritize compositions of intermediate values during search conditioned on a given set of input-output examples. This is a powerful combination because of several emergent properties: First, in bottom-up search, intermediate programs can be executed, providing semantic information to the neural network. Second, given the concrete values from those executions, we can exploit rich features based on recent work on property signatures. Finally, bottom-up search allows the system substantial flexibility in what order to generate the solution, allowing the synthesizer to build up a program from multiple smaller sub-programs. Overall, our empirical evaluation finds that the combination of learning and bottom-up search is remarkably effective, even with simple supervised learning approaches. We demonstrate the effectiveness of our technique on a new data set for synthesis of string transformation programs.
Top-K Training of GANs: Improving Generators by Making Critics Less Critical
Feb 14, 2020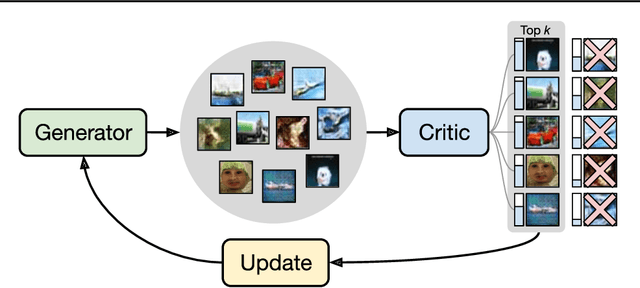

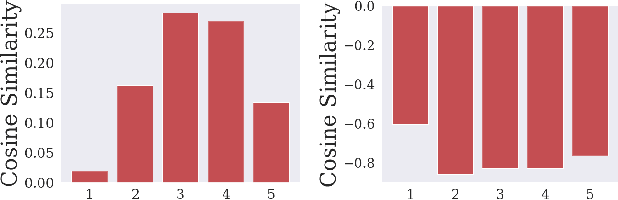
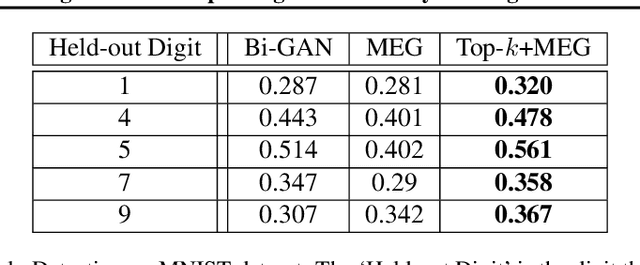
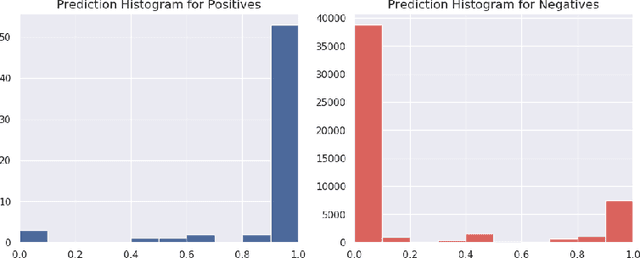
We introduce a simple (one line of code) modification to the Generative Adversarial Network (GAN) training algorithm that materially improves results with no increase in computational cost: When updating the generator parameters, we simply zero out the gradient contributions from the elements of the batch that the critic scores as `least realistic'. Through experiments on many different GAN variants, we show that this `top-k update' procedure is a generally applicable improvement. In order to understand the nature of the improvement, we conduct extensive analysis on a simple mixture-of-Gaussians dataset and discover several interesting phenomena. Among these is that, when gradient updates are computed using the worst-scoring batch elements, samples can actually be pushed further away from the their nearest mode.
Learning to Represent Programs with Property Signatures
Feb 13, 2020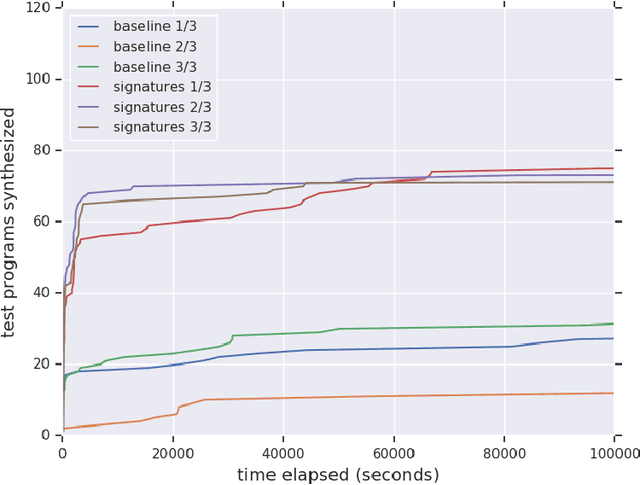
We introduce the notion of property signatures, a representation for programs and program specifications meant for consumption by machine learning algorithms. Given a function with input type $\tau_{in}$ and output type $\tau_{out}$, a property is a function of type: $(\tau_{in}, \tau_{out}) \rightarrow \texttt{Bool}$ that (informally) describes some simple property of the function under consideration. For instance, if $\tau_{in}$ and $\tau_{out}$ are both lists of the same type, one property might ask `is the input list the same length as the output list?'. If we have a list of such properties, we can evaluate them all for our function to get a list of outputs that we will call the property signature. Crucially, we can `guess' the property signature for a function given only a set of input/output pairs meant to specify that function. We discuss several potential applications of property signatures and show experimentally that they can be used to improve over a baseline synthesizer so that it emits twice as many programs in less than one-tenth of the time.
Improved Consistency Regularization for GANs
Feb 11, 2020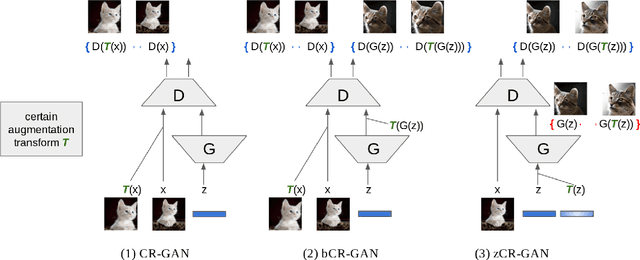
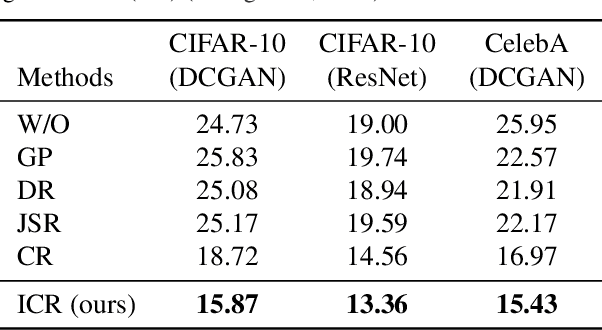


Recent work has increased the performance of Generative Adversarial Networks (GANs) by enforcing a consistency cost on the discriminator. We improve on this technique in several ways. We first show that consistency regularization can introduce artifacts into the GAN samples and explain how to fix this issue. We then propose several modifications to the consistency regularization procedure designed to improve its performance. We carry out extensive experiments quantifying the benefit of our improvements. For unconditional image synthesis on CIFAR-10 and CelebA, our modifications yield the best known FID scores on various GAN architectures. For conditional image synthesis on CIFAR-10, we improve the state-of-the-art FID score from 11.48 to 9.21. Finally, on ImageNet-2012, we apply our technique to the original BigGAN model and improve the FID from 6.66 to 5.38, which is the best score at that model size.
Your Local GAN: Designing Two Dimensional Local Attention Mechanisms for Generative Models
Dec 02, 2019
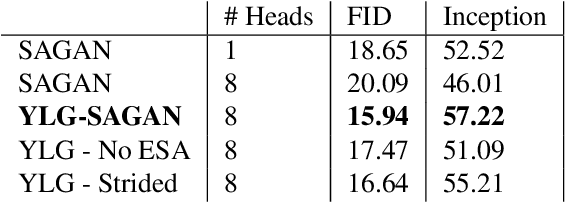

We introduce a new local sparse attention layer that preserves two-dimensional geometry and locality. We show that by just replacing the dense attention layer of SAGAN with our construction, we obtain very significant FID, Inception score and pure visual improvements. FID score is improved from $18.65$ to $15.94$ on ImageNet, keeping all other parameters the same. The sparse attention patterns that we propose for our new layer are designed using a novel information theoretic criterion that uses information flow graphs. We also present a novel way to invert Generative Adversarial Networks with attention. Our method extracts from the attention layer of the discriminator a saliency map, which we use to construct a new loss function for the inversion. This allows us to visualize the newly introduced attention heads and show that they indeed capture interesting aspects of two-dimensional geometry of real images.
Small-GAN: Speeding Up GAN Training Using Core-sets
Oct 29, 2019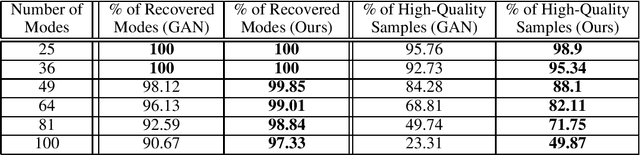
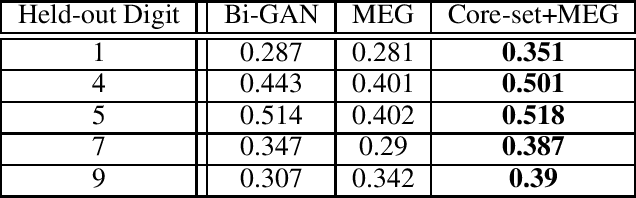


Recent work by Brock et al. (2018) suggests that Generative Adversarial Networks (GANs) benefit disproportionately from large mini-batch sizes. Unfortunately, using large batches is slow and expensive on conventional hardware. Thus, it would be nice if we could generate batches that were effectively large though actually small. In this work, we propose a method to do this, inspired by the use of Coreset-selection in active learning. When training a GAN, we draw a large batch of samples from the prior and then compress that batch using Coreset-selection. To create effectively large batches of 'real' images, we create a cached dataset of Inception activations of each training image, randomly project them down to a smaller dimension, and then use Coreset-selection on those projected activations at training time. We conduct experiments showing that this technique substantially reduces training time and memory usage for modern GAN variants, that it reduces the fraction of dropped modes in a synthetic dataset, and that it allows GANs to reach a new state of the art in anomaly detection.