 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Transferability of Representations via Augmentation-Aware Self-Supervision
Nov 18, 2021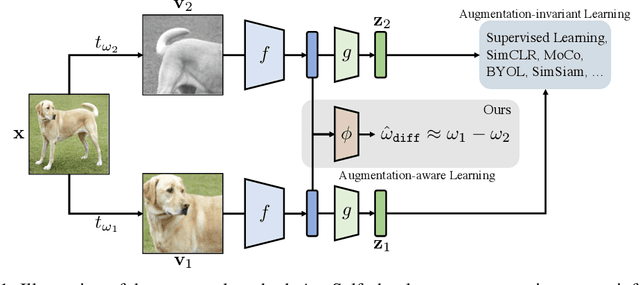
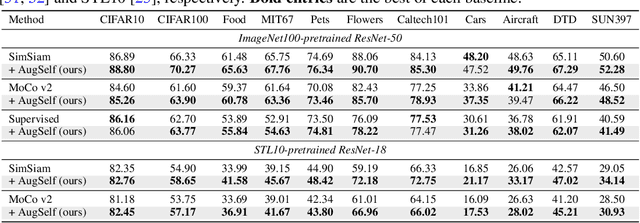
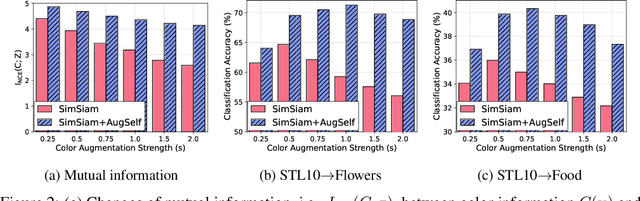
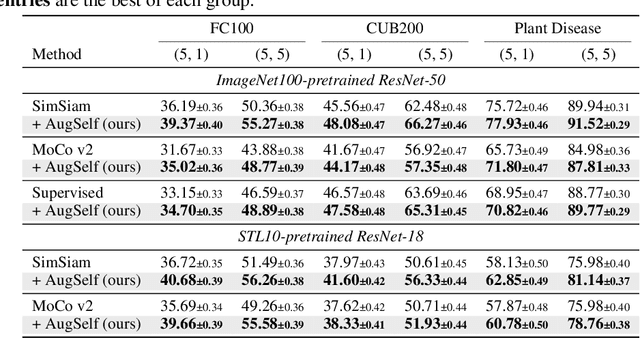
Recent unsupervised representation learning methods have shown to be effective in a range of vision tasks by learning representations invariant to data augmentations such as random cropping and color jittering. However, such invariance could be harmful to downstream tasks if they rely on the characteristics of the data augmentations, e.g., location- or color-sensitive. This is not an issue just for unsupervised learning; we found that this occurs even in supervised learning because it also learns to predict the same label for all augmented samples of an instance. To avoid such failures and obtain more generalizable representations, we suggest to optimize an auxiliary self-supervised loss, coined AugSelf, that learns the difference of augmentation parameters (e.g., cropping positions, color adjustment intensities) between two randomly augmented samples. Our intuition is that AugSelf encourages to preserve augmentation-aware information in learned representations, which could be beneficial for their transferability. Furthermore, AugSelf can easily be incorporated into recent state-of-the-art representation learning methods with a negligible additional training cost. Extensive experiments demonstrate that our simple idea consistently improves the transferability of representations learned by supervised and unsupervised methods in various transfer learning scenarios. The code is available at https://github.com/hankook/AugSelf.
Contrastive Representation Learning for Rapid Intraoperative Diagnosis of Skull Base Tumors Imaged Using Stimulated Raman Histology
Aug 08, 2021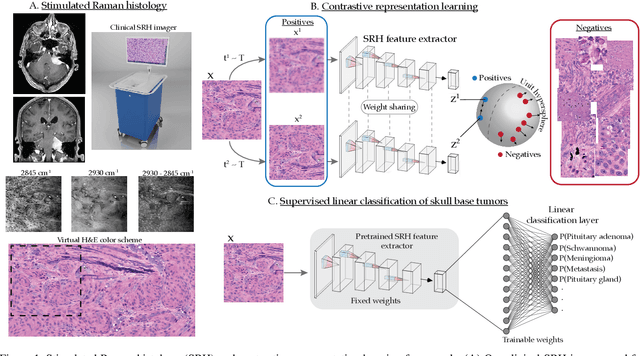

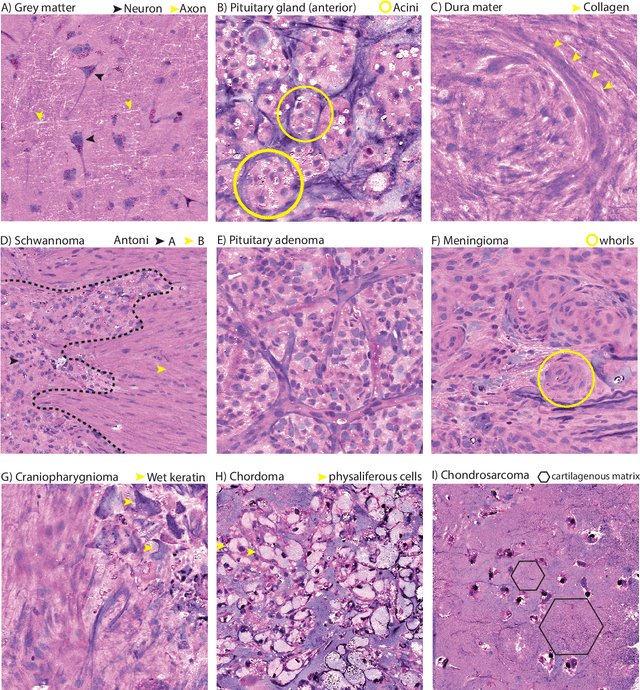
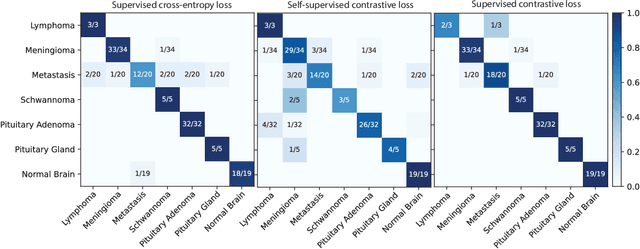
Background: Accurate diagnosis of skull base tumors is essential for providing personalized surgical treatment strategies. Intraoperative diagnosis can be challenging due to tumor diversity and lack of intraoperative pathology resources. Objective: To develop an independent and parallel intraoperative pathology workflow that can provide rapid and accurate skull base tumor diagnoses using label-free optical imaging and artificial intelligence (AI). Method: We used a fiber laser-based, label-free, non-consumptive, high-resolution microscopy method ($<$ 60 sec per 1 $\times$ 1 mm$^\text{2}$), called stimulated Raman histology (SRH), to image a consecutive, multicenter cohort of skull base tumor patients. SRH images were then used to train a convolutional neural network (CNN) model using three representation learning strategies: cross-entropy, self-supervised contrastive learning, and supervised contrastive learning. Our trained CNN models were tested on a held-out, multicenter SRH dataset. Results: SRH was able to image the diagnostic features of both benign and malignant skull base tumors. Of the three representation learning strategies, supervised contrastive learning most effectively learned the distinctive and diagnostic SRH image features for each of the skull base tumor types. In our multicenter testing set, cross-entropy achieved an overall diagnostic accuracy of 91.5%, self-supervised contrastive learning 83.9%, and supervised contrastive learning 96.6%. Our trained model was able to identify tumor-normal margins and detect regions of microscopic tumor infiltration in whole-slide SRH images. Conclusion: SRH with AI models trained using contrastive representation learning can provide rapid and accurate intraoperative diagnosis of skull base tumors.
Shortest-Path Constrained Reinforcement Learning for Sparse Reward Tasks
Jul 13, 2021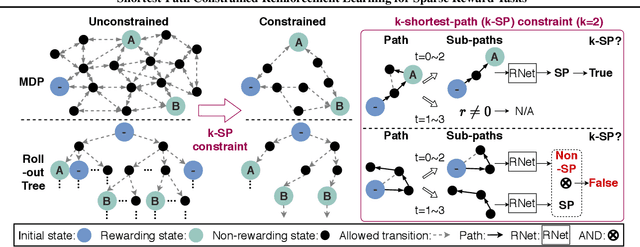
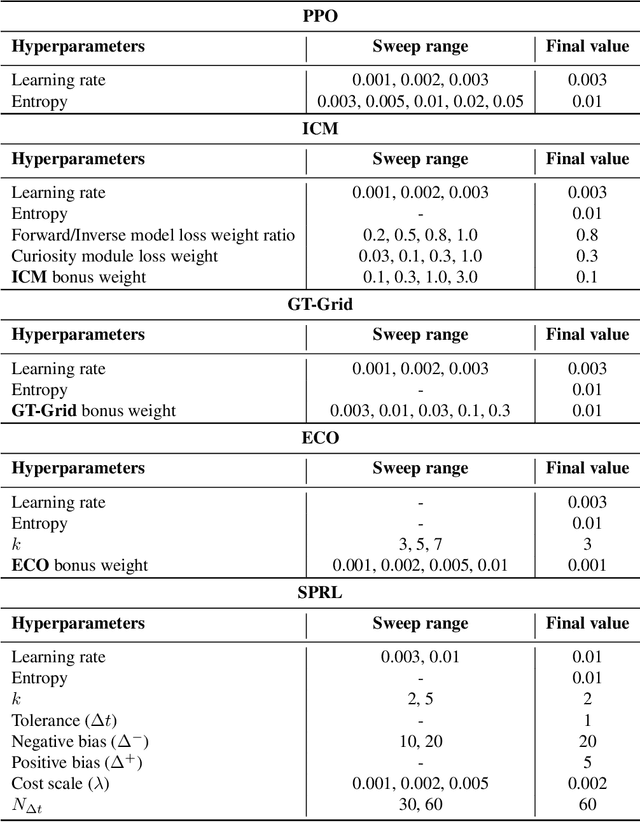

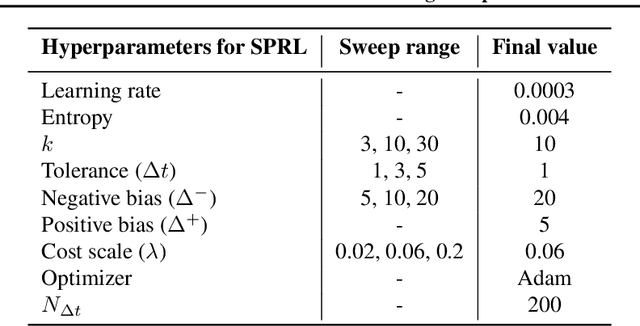
We propose the k-Shortest-Path (k-SP) constraint: a novel constraint on the agent's trajectory that improves the sample efficiency in sparse-reward MDPs. We show that any optimal policy necessarily satisfies the k-SP constraint. Notably, the k-SP constraint prevents the policy from exploring state-action pairs along the non-k-SP trajectories (e.g., going back and forth). However, in practice, excluding state-action pairs may hinder the convergence of RL algorithms. To overcome this, we propose a novel cost function that penalizes the policy violating SP constraint, instead of completely excluding it. Our numerical experiment in a tabular RL setting demonstrates that the SP constraint can significantly reduce the trajectory space of policy. As a result, our constraint enables more sample efficient learning by suppressing redundant exploration and exploitation. Our experiments on MiniGrid, DeepMind Lab, Atari, and Fetch show that the proposed method significantly improves proximal policy optimization (PPO) and outperforms existing novelty-seeking exploration methods including count-based exploration even in continuous control tasks, indicating that it improves the sample efficiency by preventing the agent from taking redundant actions.
Variational Empowerment as Representation Learning for Goal-Based Reinforcement Learning
Jun 02, 2021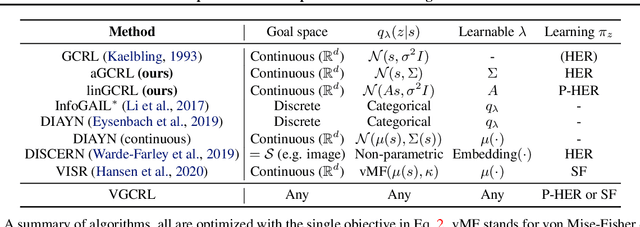
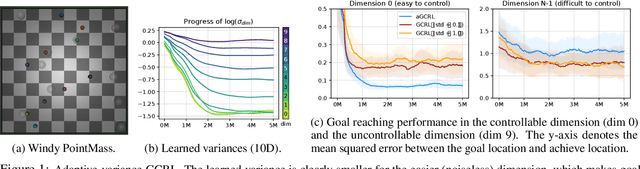
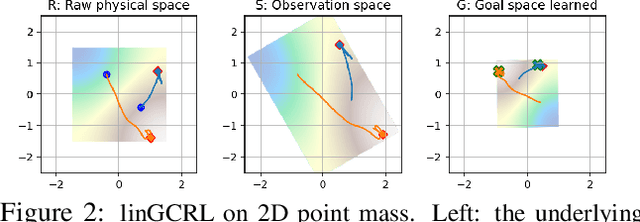

Learning to reach goal states and learning diverse skills through mutual information (MI) maximization have been proposed as principled frameworks for self-supervised reinforcement learning, allowing agents to acquire broadly applicable multitask policies with minimal reward engineering. Starting from a simple observation that the standard goal-conditioned RL (GCRL) is encapsulated by the optimization objective of variational empowerment, we discuss how GCRL and MI-based RL can be generalized into a single family of methods, which we name variational GCRL (VGCRL), interpreting variational MI maximization, or variational empowerment, as representation learning methods that acquire functionally-aware state representations for goal reaching. This novel perspective allows us to: (1) derive simple but unexplored variants of GCRL to study how adding small representation capacity can already expand its capabilities; (2) investigate how discriminator function capacity and smoothness determine the quality of discovered skills, or latent goals, through modifying latent dimensionality and applying spectral normalization; (3) adapt techniques such as hindsight experience replay (HER) from GCRL to MI-based RL; and lastly, (4) propose a novel evaluation metric, named latent goal reaching (LGR), for comparing empowerment algorithms with different choices of latent dimensionality and discriminator parameterization. Through principled mathematical derivations and careful experimental studies, our work lays a novel foundation from which to evaluate, analyze, and develop representation learning techniques in goal-based RL.
Pathdreamer: A World Model for Indoor Navigation
May 18, 2021
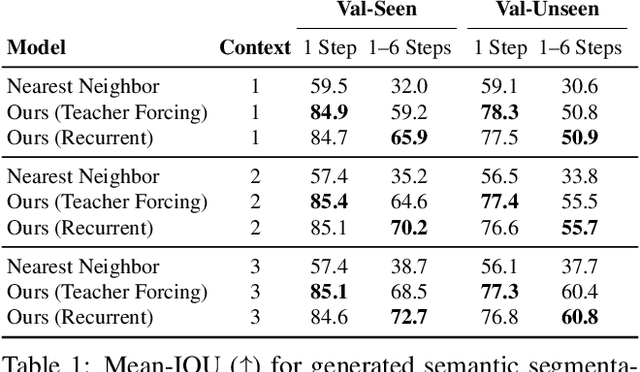
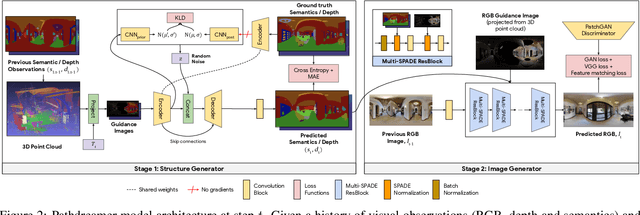
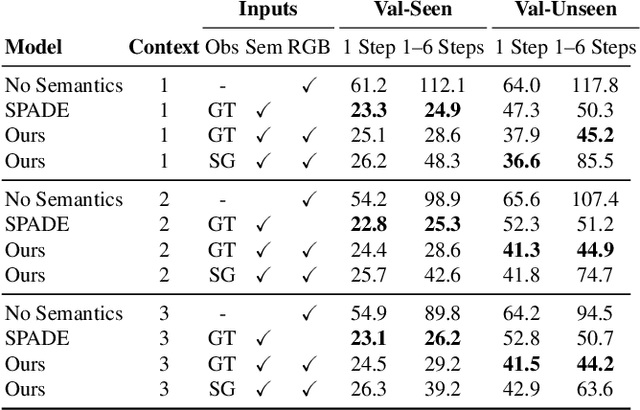
People navigating in unfamiliar buildings take advantage of myriad visual, spatial and semantic cues to efficiently achieve their navigation goals. Towards equipping computational agents with similar capabilities, we introduce Pathdreamer, a visual world model for agents navigating in novel indoor environments. Given one or more previous visual observations, Pathdreamer generates plausible high-resolution 360 visual observations (RGB, semantic segmentation and depth) for viewpoints that have not been visited, in buildings not seen during training. In regions of high uncertainty (e.g. predicting around corners, imagining the contents of an unseen room), Pathdreamer can predict diverse scenes, allowing an agent to sample multiple realistic outcomes for a given trajectory. We demonstrate that Pathdreamer encodes useful and accessible visual, spatial and semantic knowledge about human environments by using it in the downstream task of Vision-and-Language Navigation (VLN). Specifically, we show that planning ahead with Pathdreamer brings about half the benefit of looking ahead at actual observations from unobserved parts of the environment. We hope that Pathdreamer will help unlock model-based approaches to challenging embodied navigation tasks such as navigating to specified objects and VLN.
Revisiting Hierarchical Approach for Persistent Long-Term Video Prediction
Apr 14, 2021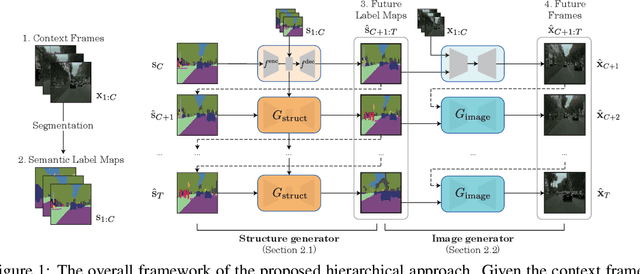
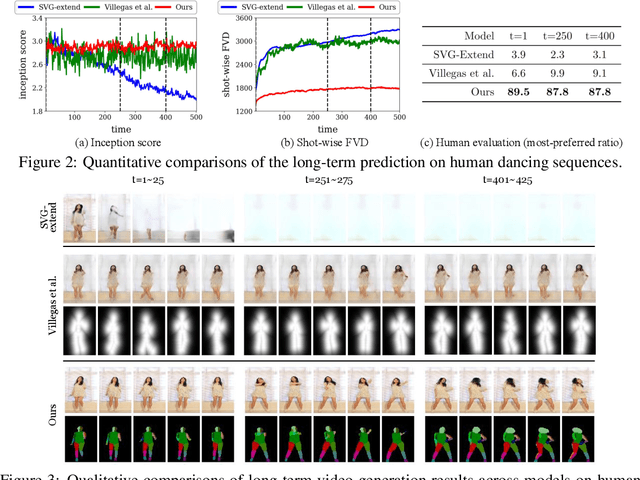
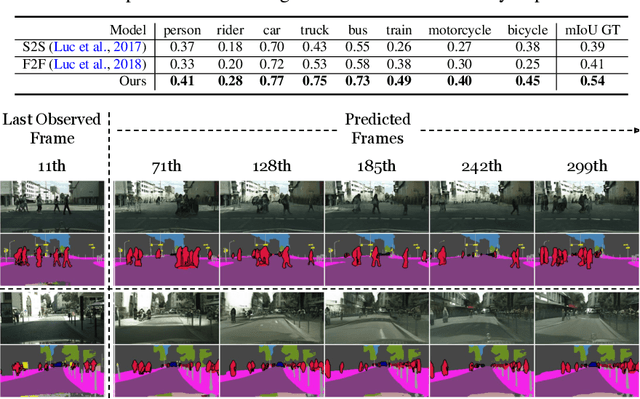
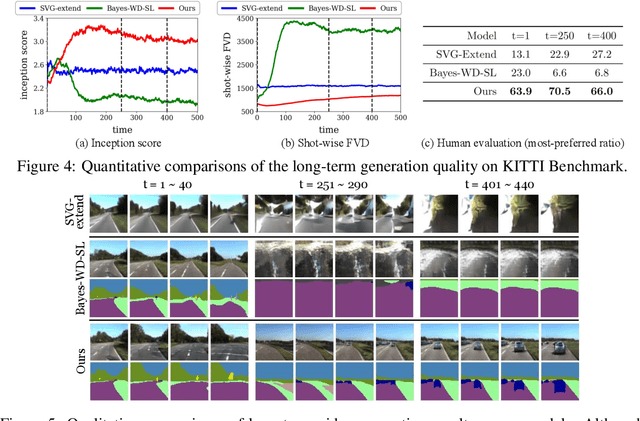
Learning to predict the long-term future of video frames is notoriously challenging due to inherent ambiguities in the distant future and dramatic amplifications of prediction error through time. Despite the recent advances in the literature, existing approaches are limited to moderately short-term prediction (less than a few seconds), while extrapolating it to a longer future quickly leads to destruction in structure and content. In this work, we revisit hierarchical models in video prediction. Our method predicts future frames by first estimating a sequence of semantic structures and subsequently translating the structures to pixels by video-to-video translation. Despite the simplicity, we show that modeling structures and their dynamics in the discrete semantic structure space with a stochastic recurrent estimator leads to surprisingly successful long-term prediction. We evaluate our method on three challenging datasets involving car driving and human dancing, and demonstrate that it can generate complicated scene structures and motions over a very long time horizon (i.e., thousands frames), setting a new standard of video prediction with orders of magnitude longer prediction time than existing approaches. Full videos and codes are available at https://1konny.github.io/HVP/.
Adversarial Environment Generation for Learning to Navigate the Web
Mar 02, 2021
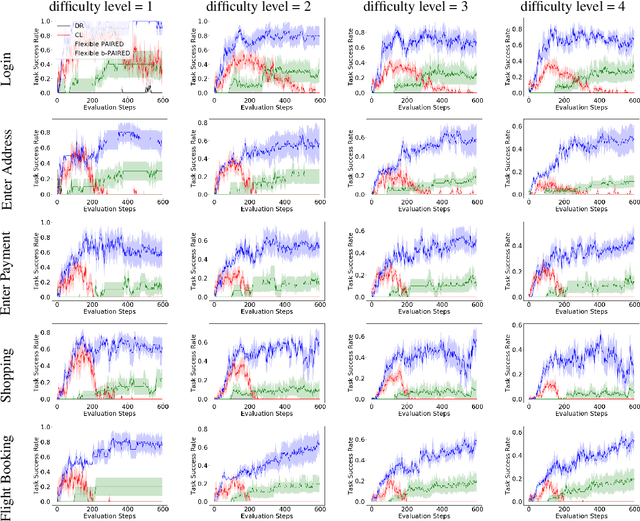
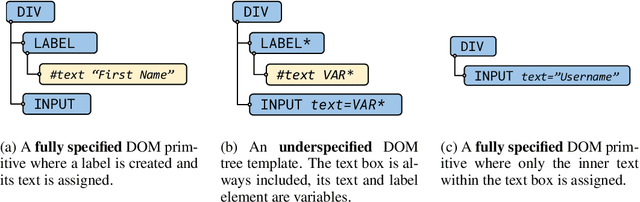
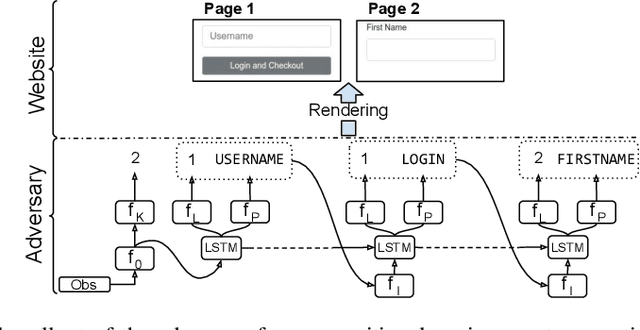
Learning to autonomously navigate the web is a difficult sequential decision making task. The state and action spaces are large and combinatorial in nature, and websites are dynamic environments consisting of several pages. One of the bottlenecks of training web navigation agents is providing a learnable curriculum of training environments that can cover the large variety of real-world websites. Therefore, we propose using Adversarial Environment Generation (AEG) to generate challenging web environments in which to train reinforcement learning (RL) agents. We provide a new benchmarking environment, gMiniWoB, which enables an RL adversary to use compositional primitives to learn to generate arbitrarily complex websites. To train the adversary, we propose a new technique for maximizing regret using the difference in the scores obtained by a pair of navigator agents. Our results show that our approach significantly outperforms prior methods for minimax regret AEG. The regret objective trains the adversary to design a curriculum of environments that are "just-the-right-challenge" for the navigator agents; our results show that over time, the adversary learns to generate increasingly complex web navigation tasks. The navigator agents trained with our technique learn to complete challenging, high-dimensional web navigation tasks, such as form filling, booking a flight etc. We show that the navigator agent trained with our proposed Flexible b-PAIRED technique significantly outperforms competitive automatic curriculum generation baselines -- including a state-of-the-art RL web navigation approach -- on a set of challenging unseen test environments, and achieves more than 80% success rate on some tasks.
State Entropy Maximization with Random Encoders for Efficient Exploration
Feb 18, 2021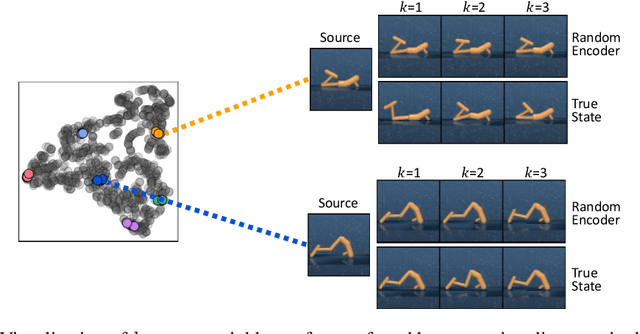
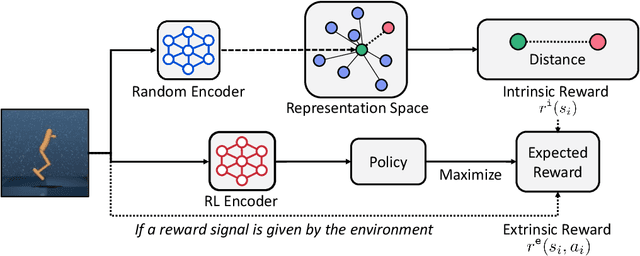

Recent exploration methods have proven to be a recipe for improving sample-efficiency in deep reinforcement learning (RL). However, efficient exploration in high-dimensional observation spaces still remains a challenge. This paper presents Random Encoders for Efficient Exploration (RE3), an exploration method that utilizes state entropy as an intrinsic reward. In order to estimate state entropy in environments with high-dimensional observations, we utilize a k-nearest neighbor entropy estimator in the low-dimensional representation space of a convolutional encoder. In particular, we find that the state entropy can be estimated in a stable and compute-efficient manner by utilizing a randomly initialized encoder, which is fixed throughout training. Our experiments show that RE3 significantly improves the sample-efficiency of both model-free and model-based RL methods on locomotion and navigation tasks from DeepMind Control Suite and MiniGrid benchmarks. We also show that RE3 allows learning diverse behaviors without extrinsic rewards, effectively improving sample-efficiency in downstream tasks. Source code and videos are available at https://sites.google.com/view/re3-rl.
Cross-Modal Contrastive Learning for Text-to-Image Generation
Jan 15, 2021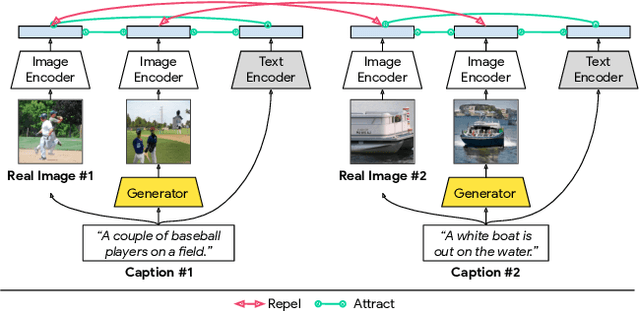
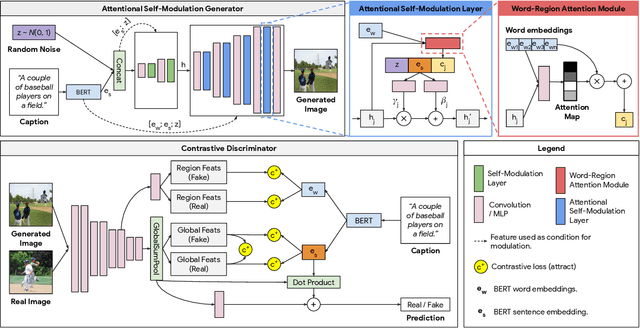
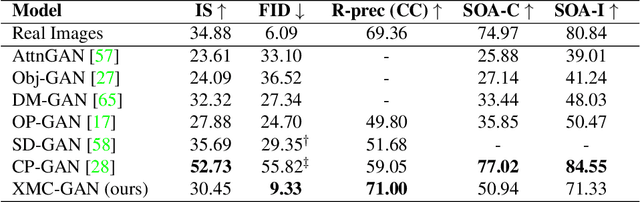
The output of text-to-image synthesis systems should be coherent, clear, photo-realistic scenes with high semantic fidelity to their conditioned text descriptions. Our Cross-Modal Contrastive Generative Adversarial Network (XMC-GAN) addresses this challenge by maximizing the mutual information between image and text. It does this via multiple contrastive losses which capture inter-modality and intra-modality correspondences. XMC-GAN uses an attentional self-modulation generator, which enforces strong text-image correspondence, and a contrastive discriminator, which acts as a critic as well as a feature encoder for contrastive learning. The quality of XMC-GAN's output is a major step up from previous models, as we show on three challenging datasets. On MS-COCO, not only does XMC-GAN improve state-of-the-art FID from 24.70 to 9.33, but--more importantly--people prefer XMC-GAN by 77.3 for image quality and 74.1 for image-text alignment, compared to three other recent models. XMC-GAN also generalizes to the challenging Localized Narratives dataset (which has longer, more detailed descriptions), improving state-of-the-art FID from 48.70 to 14.12. Lastly, we train and evaluate XMC-GAN on the challenging Open Images data, establishing a strong benchmark FID score of 26.91.
Evolving Reinforcement Learning Algorithms
Jan 08, 2021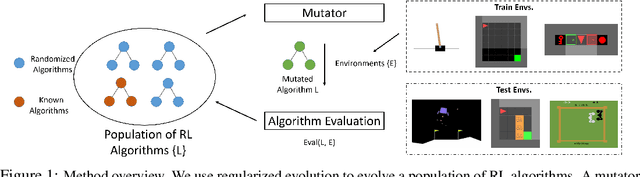
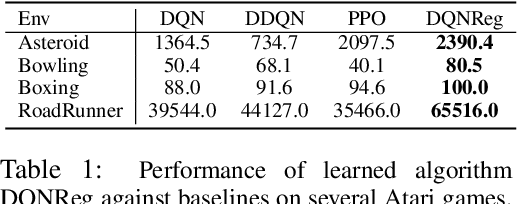
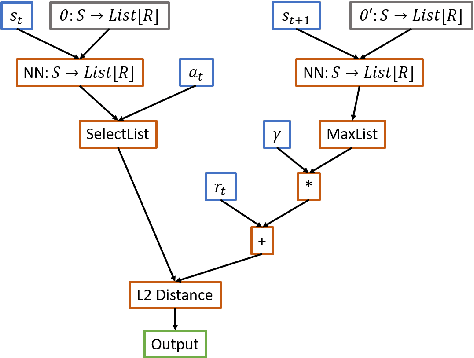
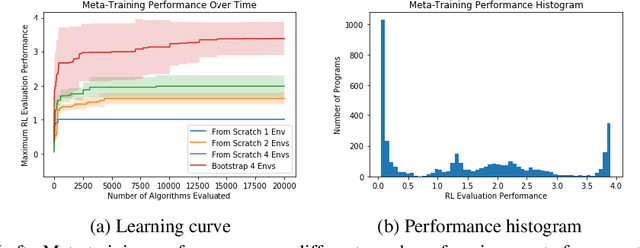
We propose a method for meta-learning reinforcement learning algorithms by searching over the space of computational graphs which compute the loss function for a value-based model-free RL agent to optimize. The learned algorithms are domain-agnostic and can generalize to new environments not seen during training. Our method can both learn from scratch and bootstrap off known existing algorithms, like DQN, enabling interpretable modifications which improve performance. Learning from scratch on simple classical control and gridworld tasks, our method rediscovers the temporal-difference (TD) algorithm. Bootstrapped from DQN, we highlight two learned algorithms which obtain good generalization performance over other classical control tasks, gridworld type tasks, and Atari games. The analysis of the learned algorithm behavior shows resemblance to recently proposed RL algorithms that address overestimation in value-based methods.