 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Language Models Understand the Cognitive Tasks Given to Them? Investigations with the N-Back Paradigm
Dec 24, 2024



Cognitive tasks originally developed for humans are now increasingly used to study language models. While applying these tasks is often straightforward, interpreting their results can be challenging. In particular, when a model underperforms, it's often unclear whether this results from a limitation in the cognitive ability being tested or a failure to understand the task itself. A recent study argued that GPT 3.5's declining performance on 2-back and 3-back tasks reflects a working memory capacity limit similar to humans. By analyzing a range of open-source language models of varying performance levels on these tasks, we show that the poor performance instead reflects a limitation in task comprehension and task set maintenance. In addition, we push the best performing model to higher n values and experiment with alternative prompting strategies, before analyzing model attentions. Our larger aim is to contribute to the ongoing conversation around refining methodologies for the cognitive evaluation of language models.
Combining Behaviors with the Successor Features Keyboard
Oct 24, 2023The Option Keyboard (OK) was recently proposed as a method for transferring behavioral knowledge across tasks. OK transfers knowledge by adaptively combining subsets of known behaviors using Successor Features (SFs) and Generalized Policy Improvement (GPI). However, it relies on hand-designed state-features and task encodings which are cumbersome to design for every new environment. In this work, we propose the "Successor Features Keyboard" (SFK), which enables transfer with discovered state-features and task encodings. To enable discovery, we propose the "Categorical Successor Feature Approximator" (CSFA), a novel learning algorithm for estimating SFs while jointly discovering state-features and task encodings. With SFK and CSFA, we achieve the first demonstration of transfer with SFs in a challenging 3D environment where all the necessary representations are discovered. We first compare CSFA against other methods for approximating SFs and show that only CSFA discovers representations compatible with SF&GPI at this scale. We then compare SFK against transfer learning baselines and show that it transfers most quickly to long-horizon tasks.
In-Context Analogical Reasoning with Pre-Trained Language Models
Jun 05, 2023



Analogical reasoning is a fundamental capacity of human cognition that allows us to reason abstractly about novel situations by relating them to past experiences. While it is thought to be essential for robust reasoning in AI systems, conventional approaches require significant training and/or hard-coding of domain knowledge to be applied to benchmark tasks. Inspired by cognitive science research that has found connections between human language and analogy-making, we explore the use of intuitive language-based abstractions to support analogy in AI systems. Specifically, we apply large pre-trained language models (PLMs) to visual Raven's Progressive Matrices (RPM), a common relational reasoning test. By simply encoding the perceptual features of the problem into language form, we find that PLMs exhibit a striking capacity for zero-shot relational reasoning, exceeding human performance and nearing supervised vision-based methods. We explore different encodings that vary the level of abstraction over task features, finding that higher-level abstractions further strengthen PLMs' analogical reasoning. Our detailed analysis reveals insights on the role of model complexity, in-context learning, and prior knowledge in solving RPM tasks.
Composing Task Knowledge with Modular Successor Feature Approximators
Jan 28, 2023



Recently, the Successor Features and Generalized Policy Improvement (SF&GPI) framework has been proposed as a method for learning, composing, and transferring predictive knowledge and behavior. SF&GPI works by having an agent learn predictive representations (SFs) that can be combined for transfer to new tasks with GPI. However, to be effective this approach requires state features that are useful to predict, and these state-features are typically hand-designed. In this work, we present a novel neural network architecture, "Modular Successor Feature Approximators" (MSFA), where modules both discover what is useful to predict, and learn their own predictive representations. We show that MSFA is able to better generalize compared to baseline architectures for learning SFs and modular architectures
In-Context Policy Iteration
Oct 07, 2022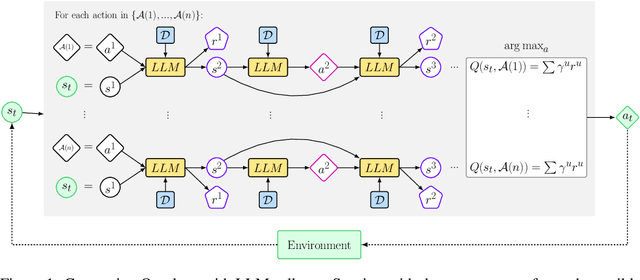

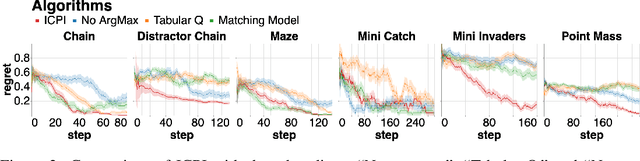
This work presents In-Context Policy Iteration, an algorithm for performing Reinforcement Learning (RL), in-context, using foundation models. While the application of foundation models to RL has received considerable attention, most approaches rely on either (1) the curation of expert demonstrations (either through manual design or task-specific pretraining) or (2) adaptation to the task of interest using gradient methods (either fine-tuning or training of adapter layers). Both of these techniques have drawbacks. Collecting demonstrations is labor-intensive, and algorithms that rely on them do not outperform the experts from which the demonstrations were derived. All gradient techniques are inherently slow, sacrificing the "few-shot" quality that made in-context learning attractive to begin with. In this work, we present an algorithm, ICPI, that learns to perform RL tasks without expert demonstrations or gradients. Instead we present a policy-iteration method in which the prompt content is the entire locus of learning. ICPI iteratively updates the contents of the prompt from which it derives its policy through trial-and-error interaction with an RL environment. In order to eliminate the role of in-weights learning (on which approaches like Decision Transformer rely heavily), we demonstrate our algorithm using Codex, a language model with no prior knowledge of the domains on which we evaluate it.
Accounting for Agreement Phenomena in Sentence Comprehension with Transformer Language Models: Effects of Similarity-based Interference on Surprisal and Attention
Apr 26, 2021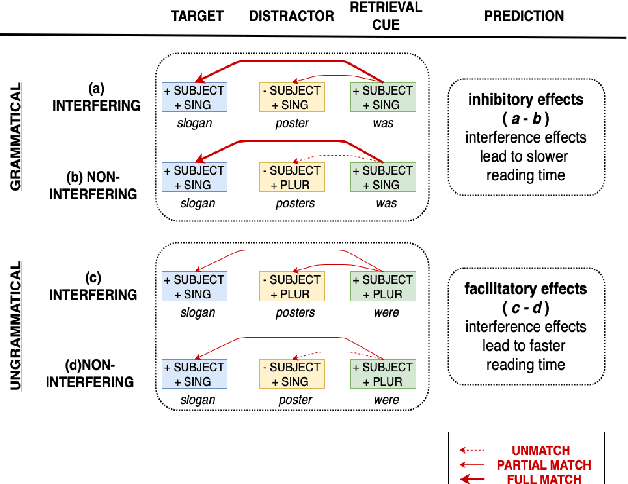
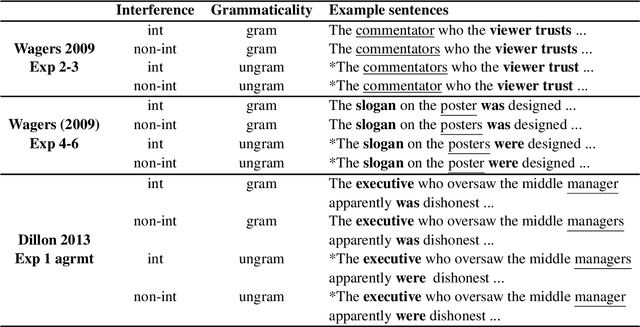
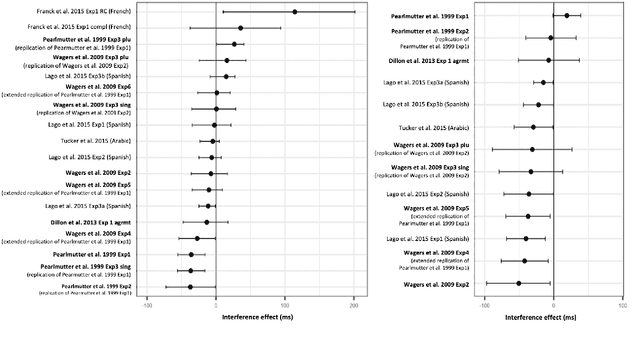
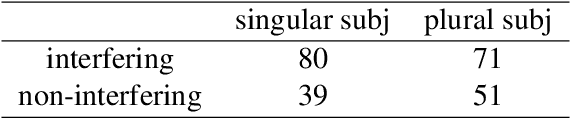
We advance a novel explanation of similarity-based interference effects in subject-verb and reflexive pronoun agreement processing, grounded in surprisal values computed from a pretrained large-scale Transformer model, GPT-2. Specifically, we show that surprisal of the verb or reflexive pronoun predicts facilitatory interference effects in ungrammatical sentences, where a distractor noun that matches in number with the verb or pronoun leads to faster reading times, despite the distractor not participating in the agreement relation. We review the human empirical evidence for such effects, including recent meta-analyses and large-scale studies. We also show that attention patterns (indexed by entropy and other measures) in the Transformer show patterns of diffuse attention in the presence of similar distractors, consistent with cue-based retrieval models of parsing. But in contrast to these models, the attentional cues and memory representations are learned entirely from the simple self-supervised task of predicting the next word.
Reinforcement Learning of Implicit and Explicit Control Flow in Instructions
Feb 25, 2021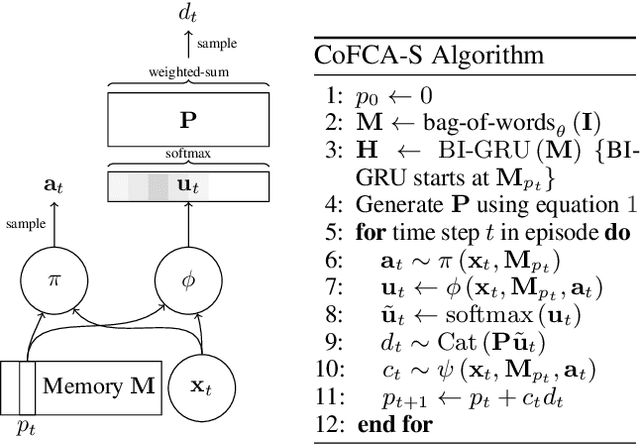

Learning to flexibly follow task instructions in dynamic environments poses interesting challenges for reinforcement learning agents. We focus here on the problem of learning control flow that deviates from a strict step-by-step execution of instructions -- that is, control flow that may skip forward over parts of the instructions or return backward to previously completed or skipped steps. Demand for such flexible control arises in two fundamental ways: explicitly when control is specified in the instructions themselves (such as conditional branching and looping) and implicitly when stochastic environment dynamics require re-completion of instructions whose effects have been perturbed, or opportunistic skipping of instructions whose effects are already present. We formulate an attention-based architecture that meets these challenges by learning, from task reward only, to flexibly attend to and condition behavior on an internal encoding of the instructions. We test the architecture's ability to learn both explicit and implicit control in two illustrative domains -- one inspired by Minecraft and the other by StarCraft -- and show that the architecture exhibits zero-shot generalization to novel instructions of length greater than those in a training set, at a performance level unmatched by two baseline recurrent architectures and one ablation architecture.
Reinforcement Learning for Sparse-Reward Object-Interaction Tasks in First-person Simulated 3D Environments
Oct 28, 2020
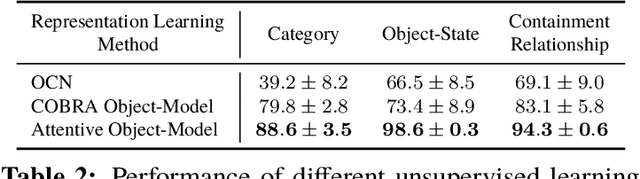
First-person object-interaction tasks in high-fidelity, 3D, simulated environments such as the AI2Thor virtual home-environment pose significant sample-efficiency challenges for reinforcement learning (RL) agents learning from sparse task rewards. To alleviate these challenges, prior work has provided extensive supervision via a combination of reward-shaping, ground-truth object-information, and expert demonstrations. In this work, we show that one can learn object-interaction tasks from scratch without supervision by learning an attentive object-model as an auxiliary task during task learning with an object-centric relational RL agent. Our key insight is that learning an object-model that incorporates object-attention into forward prediction provides a dense learning signal for unsupervised representation learning of both objects and their relationships. This, in turn, enables faster policy learning for an object-centric relational RL agent. We demonstrate our agent by introducing a set of challenging object-interaction tasks in the AI2Thor environment where learning with our attentive object-model is key to strong performance. Specifically, we compare our agent and relational RL agents with alternative auxiliary tasks to a relational RL agent equipped with ground-truth object-information, and show that learning with our object-model best closes the performance gap in terms of both learning speed and maximum success rate. Additionally, we find that incorporating object-attention into an object-model's forward predictions is key to learning representations which capture object-category and object-state.
Variance-Based Rewards for Approximate Bayesian Reinforcement Learning
Mar 15, 2012
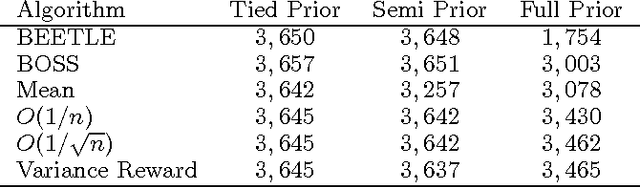
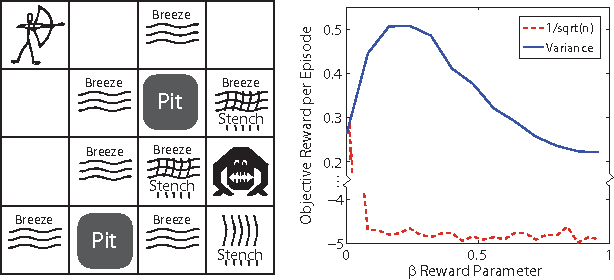

The explore{exploit dilemma is one of the central challenges in Reinforcement Learning (RL). Bayesian RL solves the dilemma by providing the agent with information in the form of a prior distribution over environments; however, full Bayesian planning is intractable. Planning with the mean MDP is a common myopic approximation of Bayesian planning. We derive a novel reward bonus that is a function of the posterior distribution over environments, which, when added to the reward in planning with the mean MDP, results in an agent which explores efficiently and effectively. Although our method is similar to existing methods when given an uninformative or unstructured prior, unlike existing methods, our method can exploit structured priors. We prove that our method results in a polynomial sample complexity and empirically demonstrate its advantages in a structured exploration task.