 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMvDrag3D: Drag-based Creative 3D Editing via Multi-view Generation-Reconstruction Priors
Oct 21, 2024Drag-based editing has become popular in 2D content creation, driven by the capabilities of image generative models. However, extending this technique to 3D remains a challenge. Existing 3D drag-based editing methods, whether employing explicit spatial transformations or relying on implicit latent optimization within limited-capacity 3D generative models, fall short in handling significant topology changes or generating new textures across diverse object categories. To overcome these limitations, we introduce MVDrag3D, a novel framework for more flexible and creative drag-based 3D editing that leverages multi-view generation and reconstruction priors. At the core of our approach is the usage of a multi-view diffusion model as a strong generative prior to perform consistent drag editing over multiple rendered views, which is followed by a reconstruction model that reconstructs 3D Gaussians of the edited object. While the initial 3D Gaussians may suffer from misalignment between different views, we address this via view-specific deformation networks that adjust the position of Gaussians to be well aligned. In addition, we propose a multi-view score function that distills generative priors from multiple views to further enhance the view consistency and visual quality. Extensive experiments demonstrate that MVDrag3D provides a precise, generative, and flexible solution for 3D drag-based editing, supporting more versatile editing effects across various object categories and 3D representations.
MVIP-NeRF: Multi-view 3D Inpainting on NeRF Scenes via Diffusion Prior
May 05, 2024Despite the emergence of successful NeRF inpainting methods built upon explicit RGB and depth 2D inpainting supervisions, these methods are inherently constrained by the capabilities of their underlying 2D inpainters. This is due to two key reasons: (i) independently inpainting constituent images results in view-inconsistent imagery, and (ii) 2D inpainters struggle to ensure high-quality geometry completion and alignment with inpainted RGB images. To overcome these limitations, we propose a novel approach called MVIP-NeRF that harnesses the potential of diffusion priors for NeRF inpainting, addressing both appearance and geometry aspects. MVIP-NeRF performs joint inpainting across multiple views to reach a consistent solution, which is achieved via an iterative optimization process based on Score Distillation Sampling (SDS). Apart from recovering the rendered RGB images, we also extract normal maps as a geometric representation and define a normal SDS loss that motivates accurate geometry inpainting and alignment with the appearance. Additionally, we formulate a multi-view SDS score function to distill generative priors simultaneously from different view images, ensuring consistent visual completion when dealing with large view variations. Our experimental results show better appearance and geometry recovery than previous NeRF inpainting methods.
PointeNet: A Lightweight Framework for Effective and Efficient Point Cloud Analysis
Dec 20, 2023



Current methodologies in point cloud analysis predominantly explore 3D geometries, often achieved through the introduction of intricate learnable geometric extractors in the encoder or by deepening networks with repeated blocks. However, these approaches inevitably lead to a significant number of learnable parameters, resulting in substantial computational costs and imposing memory burdens on CPU/GPU. Additionally, the existing strategies are primarily tailored for object-level point cloud classification and segmentation tasks, with limited extensions to crucial scene-level applications, such as autonomous driving. In response to these limitations, we introduce PointeNet, an efficient network designed specifically for point cloud analysis. PointeNet distinguishes itself with its lightweight architecture, low training cost, and plug-and-play capability, effectively capturing representative features. The network consists of a Multivariate Geometric Encoding (MGE) module and an optional Distance-aware Semantic Enhancement (DSE) module. The MGE module employs operations of sampling, grouping, and multivariate geometric aggregation to lightweightly capture and adaptively aggregate multivariate geometric features, providing a comprehensive depiction of 3D geometries. The DSE module, designed for real-world autonomous driving scenarios, enhances the semantic perception of point clouds, particularly for distant points. Our method demonstrates flexibility by seamlessly integrating with a classification/segmentation head or embedding into off-the-shelf 3D object detection networks, achieving notable performance improvements at a minimal cost. Extensive experiments on object-level datasets, including ModelNet40, ScanObjectNN, ShapeNetPart, and the scene-level dataset KITTI, demonstrate the superior performance of PointeNet over state-of-the-art methods in point cloud analysis.
Probing the Creativity of Large Language Models: Can models produce divergent semantic association?
Oct 17, 2023



Large language models possess remarkable capacity for processing language, but it remains unclear whether these models can further generate creative content. The present study aims to investigate the creative thinking of large language models through a cognitive perspective. We utilize the divergent association task (DAT), an objective measurement of creativity that asks models to generate unrelated words and calculates the semantic distance between them. We compare the results across different models and decoding strategies. Our findings indicate that: (1) When using the greedy search strategy, GPT-4 outperforms 96% of humans, while GPT-3.5-turbo exceeds the average human level. (2) Stochastic sampling and temperature scaling are effective to obtain higher DAT scores for models except GPT-4, but face a trade-off between creativity and stability. These results imply that advanced large language models have divergent semantic associations, which is a fundamental process underlying creativity.
SVDFormer: Complementing Point Cloud via Self-view Augmentation and Self-structure Dual-generator
Jul 17, 2023



In this paper, we propose a novel network, SVDFormer, to tackle two specific challenges in point cloud completion: understanding faithful global shapes from incomplete point clouds and generating high-accuracy local structures. Current methods either perceive shape patterns using only 3D coordinates or import extra images with well-calibrated intrinsic parameters to guide the geometry estimation of the missing parts. However, these approaches do not always fully leverage the cross-modal self-structures available for accurate and high-quality point cloud completion. To this end, we first design a Self-view Fusion Network that leverages multiple-view depth image information to observe incomplete self-shape and generate a compact global shape. To reveal highly detailed structures, we then introduce a refinement module, called Self-structure Dual-generator, in which we incorporate learned shape priors and geometric self-similarities for producing new points. By perceiving the incompleteness of each point, the dual-path design disentangles refinement strategies conditioned on the structural type of each point. SVDFormer absorbs the wisdom of self-structures, avoiding any additional paired information such as color images with precisely calibrated camera intrinsic parameters. Comprehensive experiments indicate that our method achieves state-of-the-art performance on widely-used benchmarks. Code will be available at https://github.com/czvvd/SVDFormer.
LBF:Learnable Bilateral Filter For Point Cloud Denoising
Oct 28, 2022



Bilateral filter (BF) is a fast, lightweight and effective tool for image denoising and well extended to point cloud denoising. However, it often involves continual yet manual parameter adjustment; this inconvenience discounts the efficiency and user experience to obtain satisfied denoising results. We propose LBF, an end-to-end learnable bilateral filtering network for point cloud denoising; to our knowledge, this is the first time. Unlike the conventional BF and its variants that receive the same parameters for a whole point cloud, LBF learns adaptive parameters for each point according its geometric characteristic (e.g., corner, edge, plane), avoiding remnant noise, wrongly-removed geometric details, and distorted shapes. Besides the learnable paradigm of BF, we have two cores to facilitate LBF. First, different from the local BF, LBF possesses a global-scale feature perception ability by exploiting multi-scale patches of each point. Second, LBF formulates a geometry-aware bi-directional projection loss, leading the denoising results to being faithful to their underlying surfaces. Users can apply our LBF without any laborious parameter tuning to achieve the optimal denoising results. Experiments show clear improvements of LBF over its competitors on both synthetic and real-scanned datasets.
GeoGCN: Geometric Dual-domain Graph Convolution Network for Point Cloud Denoising
Oct 28, 2022We propose GeoGCN, a novel geometric dual-domain graph convolution network for point cloud denoising (PCD). Beyond the traditional wisdom of PCD, to fully exploit the geometric information of point clouds, we define two kinds of surface normals, one is called Real Normal (RN), and the other is Virtual Normal (VN). RN preserves the local details of noisy point clouds while VN avoids the global shape shrinkage during denoising. GeoGCN is a new PCD paradigm that, 1) first regresses point positions by spatialbased GCN with the help of VNs, 2) then estimates initial RNs by performing Principal Component Analysis on the regressed points, and 3) finally regresses fine RNs by normalbased GCN. Unlike existing PCD methods, GeoGCN not only exploits two kinds of geometry expertise (i.e., RN and VN) but also benefits from training data. Experiments validate that GeoGCN outperforms SOTAs in terms of both noise-robustness and local-and-global feature preservation.
SPCNet: Stepwise Point Cloud Completion Network
Sep 05, 2022
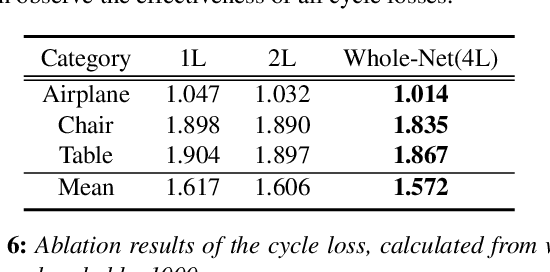
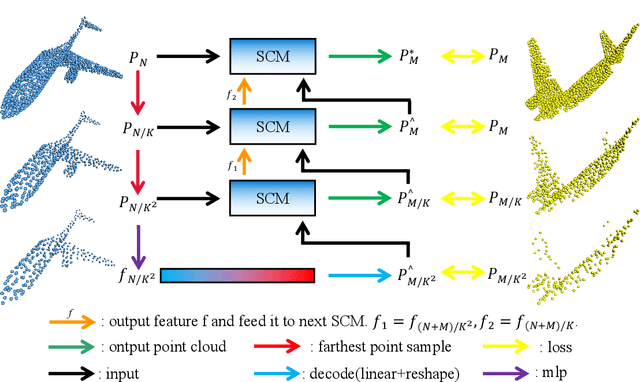
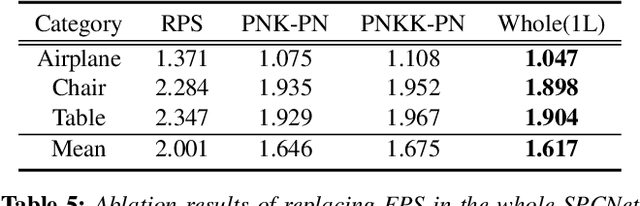
How will you repair a physical object with large missings? You may first recover its global yet coarse shape and stepwise increase its local details. We are motivated to imitate the above physical repair procedure to address the point cloud completion task. We propose a novel stepwise point cloud completion network (SPCNet) for various 3D models with large missings. SPCNet has a hierarchical bottom-to-up network architecture. It fulfills shape completion in an iterative manner, which 1) first infers the global feature of the coarse result; 2) then infers the local feature with the aid of global feature; and 3) finally infers the detailed result with the help of local feature and coarse result. Beyond the wisdom of simulating the physical repair, we newly design a cycle loss %based training strategy to enhance the generalization and robustness of SPCNet. Extensive experiments clearly show the superiority of our SPCNet over the state-of-the-art methods on 3D point clouds with large missings.
Geometric and Learning-based Mesh Denoising: A Comprehensive Survey
Sep 02, 2022

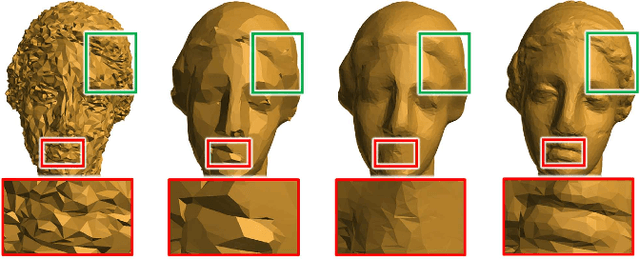
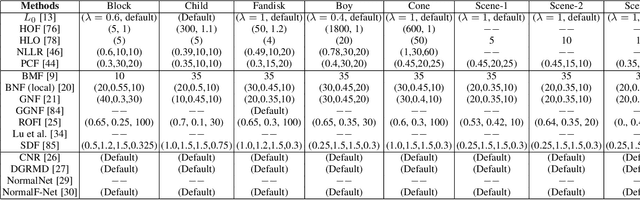
Mesh denoising is a fundamental problem in digital geometry processing. It seeks to remove surface noise, while preserving surface intrinsic signals as accurately as possible. While the traditional wisdom has been built upon specialized priors to smooth surfaces, learning-based approaches are making their debut with great success in generalization and automation. In this work, we provide a comprehensive review of the advances in mesh denoising, containing both traditional geometric approaches and recent learning-based methods. First, to familiarize readers with the denoising tasks, we summarize four common issues in mesh denoising. We then provide two categorizations of the existing denoising methods. Furthermore, three important categories, including optimization-, filter-, and data-driven-based techniques, are introduced and analyzed in detail, respectively. Both qualitative and quantitative comparisons are illustrated, to demonstrate the effectiveness of the state-of-the-art denoising methods. Finally, potential directions of future work are pointed out to solve the common problems of these approaches. A mesh denoising benchmark is also built in this work, and future researchers will easily and conveniently evaluate their methods with the state-of-the-art approaches.
UTOPIC: Uncertainty-aware Overlap Prediction Network for Partial Point Cloud Registration
Aug 12, 2022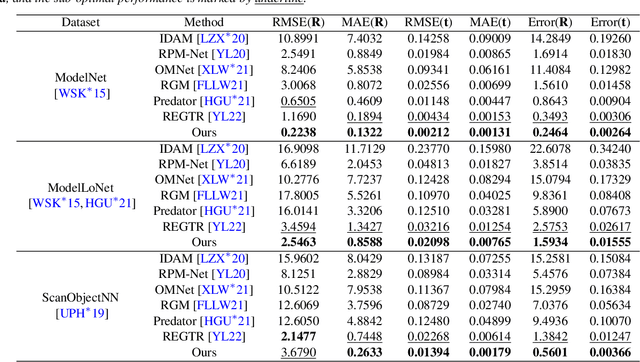
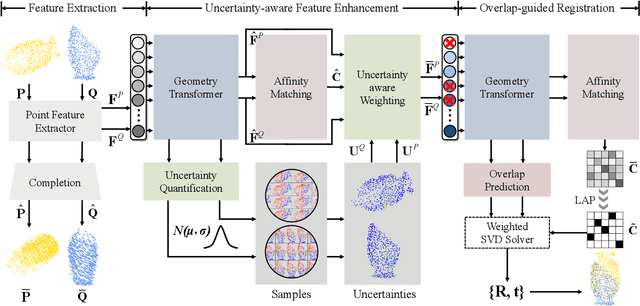
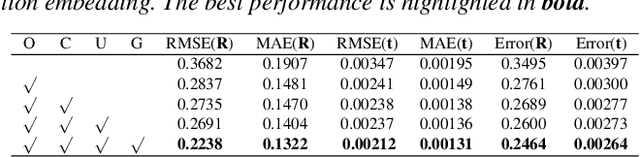
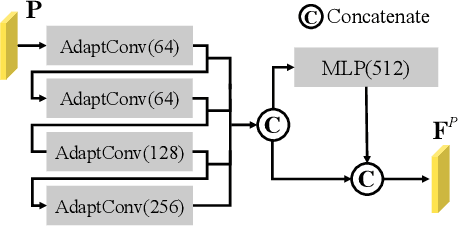
High-confidence overlap prediction and accurate correspondences are critical for cutting-edge models to align paired point clouds in a partial-to-partial manner. However, there inherently exists uncertainty between the overlapping and non-overlapping regions, which has always been neglected and significantly affects the registration performance. Beyond the current wisdom, we propose a novel uncertainty-aware overlap prediction network, dubbed UTOPIC, to tackle the ambiguous overlap prediction problem; to our knowledge, this is the first to explicitly introduce overlap uncertainty to point cloud registration. Moreover, we induce the feature extractor to implicitly perceive the shape knowledge through a completion decoder, and present a geometric relation embedding for Transformer to obtain transformation-invariant geometry-aware feature representations. With the merits of more reliable overlap scores and more precise dense correspondences, UTOPIC can achieve stable and accurate registration results, even for the inputs with limited overlapping areas. Extensive quantitative and qualitative experiments on synthetic and real benchmarks demonstrate the superiority of our approach over state-of-the-art methods.