 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Egocentric Referring Video Object Segmentation via Dual-Modal Causal Intervention
Dec 30, 2025Egocentric Referring Video Object Segmentation (Ego-RVOS) aims to segment the specific object actively involved in a human action, as described by a language query, within first-person videos. This task is critical for understanding egocentric human behavior. However, achieving such segmentation robustly is challenging due to ambiguities inherent in egocentric videos and biases present in training data. Consequently, existing methods often struggle, learning spurious correlations from skewed object-action pairings in datasets and fundamental visual confounding factors of the egocentric perspective, such as rapid motion and frequent occlusions. To address these limitations, we introduce Causal Ego-REferring Segmentation (CERES), a plug-in causal framework that adapts strong, pre-trained RVOS backbones to the egocentric domain. CERES implements dual-modal causal intervention: applying backdoor adjustment principles to counteract language representation biases learned from dataset statistics, and leveraging front-door adjustment concepts to address visual confounding by intelligently integrating semantic visual features with geometric depth information guided by causal principles, creating representations more robust to egocentric distortions. Extensive experiments demonstrate that CERES achieves state-of-the-art performance on Ego-RVOS benchmarks, highlighting the potential of applying causal reasoning to build more reliable models for broader egocentric video understanding.
DART: Dual Adaptive Refinement Transfer for Open-Vocabulary Multi-Label Recognition
Aug 07, 2025Open-Vocabulary Multi-Label Recognition (OV-MLR) aims to identify multiple seen and unseen object categories within an image, requiring both precise intra-class localization to pinpoint objects and effective inter-class reasoning to model complex category dependencies. While Vision-Language Pre-training (VLP) models offer a strong open-vocabulary foundation, they often struggle with fine-grained localization under weak supervision and typically fail to explicitly leverage structured relational knowledge beyond basic semantics, limiting performance especially for unseen classes. To overcome these limitations, we propose the Dual Adaptive Refinement Transfer (DART) framework. DART enhances a frozen VLP backbone via two synergistic adaptive modules. For intra-class refinement, an Adaptive Refinement Module (ARM) refines patch features adaptively, coupled with a novel Weakly Supervised Patch Selecting (WPS) loss that enables discriminative localization using only image-level labels. Concurrently, for inter-class transfer, an Adaptive Transfer Module (ATM) leverages a Class Relationship Graph (CRG), constructed using structured knowledge mined from a Large Language Model (LLM), and employs graph attention network to adaptively transfer relational information between class representations. DART is the first framework, to our knowledge, to explicitly integrate external LLM-derived relational knowledge for adaptive inter-class transfer while simultaneously performing adaptive intra-class refinement under weak supervision for OV-MLR. Extensive experiments on challenging benchmarks demonstrate that our DART achieves new state-of-the-art performance, validating its effectiveness.
Category-Adaptive Cross-Modal Semantic Refinement and Transfer for Open-Vocabulary Multi-Label Recognition
Dec 09, 2024



Benefiting from the generalization capability of CLIP, recent vision language pre-training (VLP) models have demonstrated an impressive ability to capture virtually any visual concept in daily images. However, due to the presence of unseen categories in open-vocabulary settings, existing algorithms struggle to effectively capture strong semantic correlations between categories, resulting in sub-optimal performance on the open-vocabulary multi-label recognition (OV-MLR). Furthermore, the substantial variation in the number of discriminative areas across diverse object categories is misaligned with the fixed-number patch matching used in current methods, introducing noisy visual cues that hinder the accurate capture of target semantics. To tackle these challenges, we propose a novel category-adaptive cross-modal semantic refinement and transfer (C$^2$SRT) framework to explore the semantic correlation both within each category and across different categories, in a category-adaptive manner. The proposed framework consists of two complementary modules, i.e., intra-category semantic refinement (ISR) module and inter-category semantic transfer (IST) module. Specifically, the ISR module leverages the cross-modal knowledge of the VLP model to adaptively find a set of local discriminative regions that best represent the semantics of the target category. The IST module adaptively discovers a set of most correlated categories for a target category by utilizing the commonsense capabilities of LLMs to construct a category-adaptive correlation graph and transfers semantic knowledge from the correlated seen categories to unseen ones. Extensive experiments on OV-MLR benchmarks clearly demonstrate that the proposed C$^2$SRT framework outperforms current state-of-the-art algorithms.
Using Argument-based Features to Predict and Analyse Review Helpfulness
Jul 23, 2017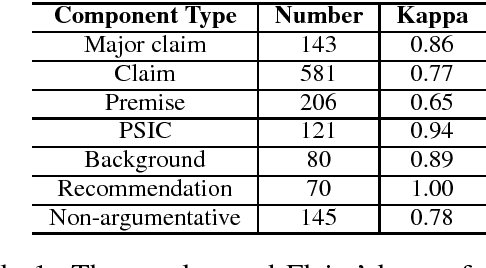
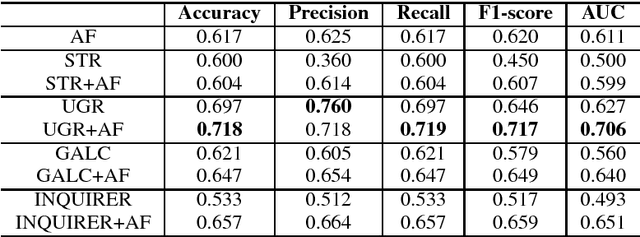
We study the helpful product reviews identification problem in this paper. We observe that the evidence-conclusion discourse relations, also known as arguments, often appear in product reviews, and we hypothesise that some argument-based features, e.g. the percentage of argumentative sentences, the evidences-conclusions ratios, are good indicators of helpful reviews. To validate this hypothesis, we manually annotate arguments in 110 hotel reviews, and investigate the effectiveness of several combinations of argument-based features. Experiments suggest that, when being used together with the argument-based features, the state-of-the-art baseline features can enjoy a performance boost (in terms of F1) of 11.01\% in average.
Joint RNN Model for Argument Component Boundary Detection
May 05, 2017
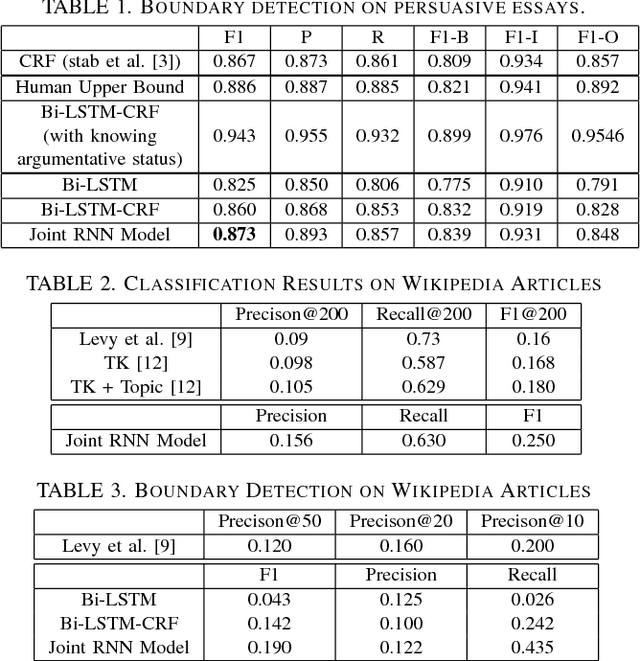
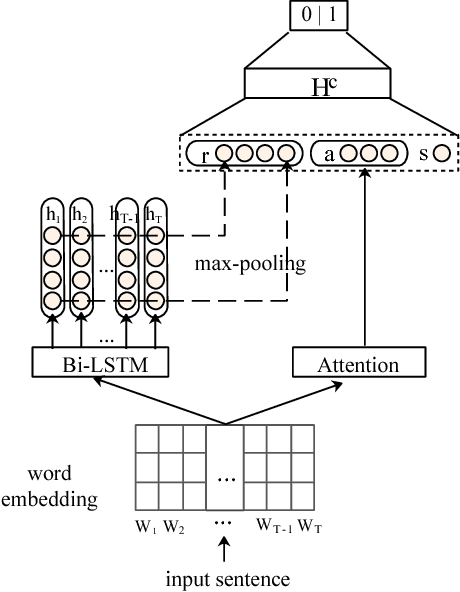
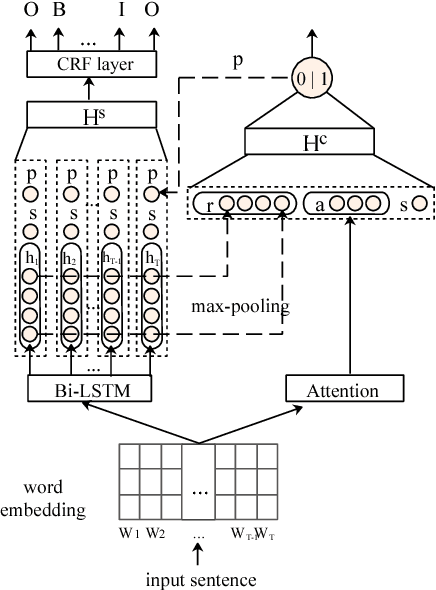
Argument Component Boundary Detection (ACBD) is an important sub-task in argumentation mining; it aims at identifying the word sequences that constitute argument components, and is usually considered as the first sub-task in the argumentation mining pipeline. Existing ACBD methods heavily depend on task-specific knowledge, and require considerable human efforts on feature-engineering. To tackle these problems, in this work, we formulate ACBD as a sequence labeling problem and propose a variety of Recurrent Neural Network (RNN) based methods, which do not use domain specific or handcrafted features beyond the relative position of the sentence in the document. In particular, we propose a novel joint RNN model that can predict whether sentences are argumentative or not, and use the predicted results to more precisely detect the argument component boundaries. We evaluate our techniques on two corpora from two different genres; results suggest that our joint RNN model obtain the state-of-the-art performance on both datasets.
Crowdsourcing Argumentation Structures in Chinese Hotel Reviews
May 05, 2017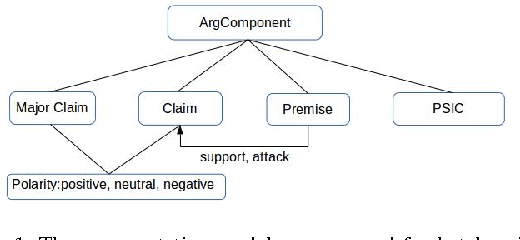
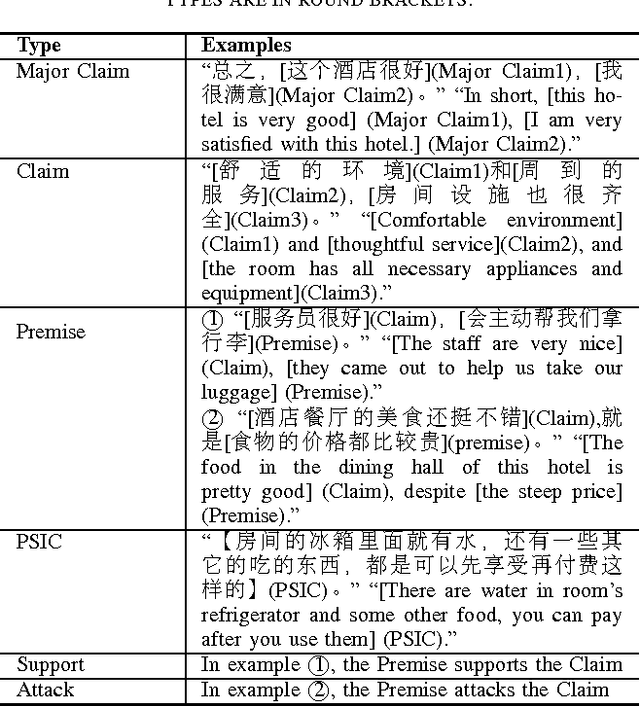
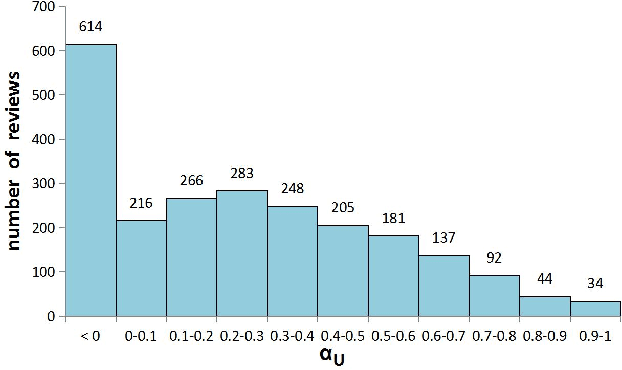

Argumentation mining aims at automatically extracting the premises-claim discourse structures in natural language texts. There is a great demand for argumentation corpora for customer reviews. However, due to the controversial nature of the argumentation annotation task, there exist very few large-scale argumentation corpora for customer reviews. In this work, we novelly use the crowdsourcing technique to collect argumentation annotations in Chinese hotel reviews. As the first Chinese argumentation dataset, our corpus includes 4814 argument component annotations and 411 argument relation annotations, and its annotations qualities are comparable to some widely used argumentation corpora in other languages.