 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoTrans: A Benchmark for Understanding, Reasoning, and Predicting Emotion Transitions in Multimodal LLMs
Apr 25, 2026Recent multimodal large language models (MLLMs) have shown strong capabilities in perception, reasoning, and generation, and are increasingly used in applications such as social robots and human-computer interaction, where understanding human emotions is essential. However, existing benchmarks mainly formulate emotion understanding as a static recognition problem, leaving it largely unclear whether current MLLMs can understand emotion as a dynamic process that evolves, shifts between states, and unfolds across diverse social contexts. To bridge this gap, we present EmoTrans, a benchmark for evaluating emotion dynamics understanding in multimodal videos. EmoTrans contains 1,000 carefully collected and manually annotated video clips, covering 12 real-world scenarios, and further provides over 3,000 task-specific question-answer (QA) pairs for fine-grained evaluation. The benchmark introduces four tasks, namely Emotion Change Detection (ECD), Emotion State Identification (ESI), Emotion Transition Reasoning (ETR), and Next Emotion Prediction (NEP), forming a progressive evaluation framework from coarse-grained detection to deeper reasoning and prediction. We conduct a comprehensive evaluation of 18 state-of-the-art MLLMs on EmoTrans and obtain two main findings. First, although current MLLMs show relatively stronger performance on coarse-grained emotion change detection, they still struggle with fine-grained emotion dynamics modeling. Second, socially complex settings, especially multi-person scenarios, remain substantially challenging, while reasoning-oriented variants do not consistently yield clear improvements. To facilitate future research, we publicly release the benchmark, evaluation protocol, and code at https://github.com/Emo-gml/EmoTrans.
Investigating Data Pruning for Pretraining Biological Foundation Models at Scale
Dec 15, 2025Biological foundation models (BioFMs), pretrained on large-scale biological sequences, have recently shown strong potential in providing meaningful representations for diverse downstream bioinformatics tasks. However, such models often rely on millions to billions of training sequences and billions of parameters, resulting in prohibitive computational costs and significant barriers to reproducibility and accessibility, particularly for academic labs. To address these challenges, we investigate the feasibility of data pruning for BioFM pretraining and propose a post-hoc influence-guided data pruning framework tailored to biological domains. Our approach introduces a subset-based self-influence formulation that enables efficient estimation of sample importance at low computational cost, and builds upon it two simple yet effective selection strategies, namely Top-k Influence (Top I) and Coverage-Centric Influence (CCI). We empirically validate our method on two representative BioFMs, RNA-FM and ESM-C. For RNA, our framework consistently outperforms random selection baselines under an extreme pruning rate of over 99 percent, demonstrating its effectiveness. Furthermore, we show the generalizability of our framework on protein-related tasks using ESM-C. In particular, our coreset even outperforms random subsets that are ten times larger in both RNA and protein settings, revealing substantial redundancy in biological sequence datasets. These findings underscore the potential of influence-guided data pruning to substantially reduce the computational cost of BioFM pretraining, paving the way for more efficient, accessible, and sustainable biological AI research.
TheraMind: A Strategic and Adaptive Agent for Longitudinal Psychological Counseling
Oct 29, 2025



Large language models (LLMs) in psychological counseling have attracted increasing attention. However, existing approaches often lack emotional understanding, adaptive strategies, and the use of therapeutic methods across multiple sessions with long-term memory, leaving them far from real clinical practice. To address these critical gaps, we introduce TheraMind, a strategic and adaptive agent for longitudinal psychological counseling. The cornerstone of TheraMind is a novel dual-loop architecture that decouples the complex counseling process into an Intra-Session Loop for tactical dialogue management and a Cross-Session Loop for strategic therapeutic planning. The Intra-Session Loop perceives the patient's emotional state to dynamically select response strategies while leveraging cross-session memory to ensure continuity. Crucially, the Cross-Session Loop empowers the agent with long-term adaptability by evaluating the efficacy of the applied therapy after each session and adjusting the method for subsequent interactions. We validate our approach in a high-fidelity simulation environment grounded in real clinical cases. Extensive evaluations show that TheraMind outperforms other methods, especially on multi-session metrics like Coherence, Flexibility, and Therapeutic Attunement, validating the effectiveness of its dual-loop design in emulating strategic, adaptive, and longitudinal therapeutic behavior. The code is publicly available at https://0mwwm0.github.io/TheraMind/.
Beyond Empathy: Integrating Diagnostic and Therapeutic Reasoning with Large Language Models for Mental Health Counseling
May 21, 2025



Large language models (LLMs) hold significant potential for mental health support, capable of generating empathetic responses and simulating therapeutic conversations. However, existing LLM-based approaches often lack the clinical grounding necessary for real-world psychological counseling, particularly in explicit diagnostic reasoning aligned with standards like the DSM/ICD and incorporating diverse therapeutic modalities beyond basic empathy or single strategies. To address these critical limitations, we propose PsyLLM, the first large language model designed to systematically integrate both diagnostic and therapeutic reasoning for mental health counseling. To develop the PsyLLM, we propose a novel automated data synthesis pipeline. This pipeline processes real-world mental health posts, generates multi-turn dialogue structures, and leverages LLMs guided by international diagnostic standards (e.g., DSM/ICD) and multiple therapeutic frameworks (e.g., CBT, ACT, psychodynamic) to simulate detailed clinical reasoning processes. Rigorous multi-dimensional filtering ensures the generation of high-quality, clinically aligned dialogue data. In addition, we introduce a new benchmark and evaluation protocol, assessing counseling quality across four key dimensions: comprehensiveness, professionalism, authenticity, and safety. Our experiments demonstrate that PsyLLM significantly outperforms state-of-the-art baseline models on this benchmark.
EmoBench-M: Benchmarking Emotional Intelligence for Multimodal Large Language Models
Feb 06, 2025



With the integration of Multimodal large language models (MLLMs) into robotic systems and various AI applications, embedding emotional intelligence (EI) capabilities into these models is essential for enabling robots to effectively address human emotional needs and interact seamlessly in real-world scenarios. Existing static, text-based, or text-image benchmarks overlook the multimodal complexities of real-world interactions and fail to capture the dynamic, multimodal nature of emotional expressions, making them inadequate for evaluating MLLMs' EI. Based on established psychological theories of EI, we build EmoBench-M, a novel benchmark designed to evaluate the EI capability of MLLMs across 13 valuation scenarios from three key dimensions: foundational emotion recognition, conversational emotion understanding, and socially complex emotion analysis. Evaluations of both open-source and closed-source MLLMs on EmoBench-M reveal a significant performance gap between them and humans, highlighting the need to further advance their EI capabilities. All benchmark resources, including code and datasets, are publicly available at https://emo-gml.github.io/.
MemoryMamba: Memory-Augmented State Space Model for Defect Recognition
May 06, 2024



As automation advances in manufacturing, the demand for precise and sophisticated defect detection technologies grows. Existing vision models for defect recognition methods are insufficient for handling the complexities and variations of defects in contemporary manufacturing settings. These models especially struggle in scenarios involving limited or imbalanced defect data. In this work, we introduce MemoryMamba, a novel memory-augmented state space model (SSM), designed to overcome the limitations of existing defect recognition models. MemoryMamba integrates the state space model with the memory augmentation mechanism, enabling the system to maintain and retrieve essential defect-specific information in training. Its architecture is designed to capture dependencies and intricate defect characteristics, which are crucial for effective defect detection. In the experiments, MemoryMamba was evaluated across four industrial datasets with diverse defect types and complexities. The model consistently outperformed other methods, demonstrating its capability to adapt to various defect recognition scenarios.
Data-CUBE: Data Curriculum for Instruction-based Sentence Representation Learning
Jan 07, 2024



Recently, multi-task instruction tuning has been applied into sentence representation learning, which endows the capability of generating specific representations with the guidance of task instruction, exhibiting strong generalization ability on new tasks. However, these methods mostly neglect the potential interference problems across different tasks and instances, which may affect the training and convergence of the model. To address it, we propose a data curriculum method, namely Data-CUBE, that arranges the orders of all the multi-task data for training, to minimize the interference risks from the two views. In the task level, we aim to find the optimal task order to minimize the total cross-task interference risk, which is exactly the traveling salesman problem, hence we utilize a simulated annealing algorithm to find its solution. In the instance level, we measure the difficulty of all instances per task, then divide them into the easy-to-difficult mini-batches for training. Experiments on MTEB sentence representation evaluation tasks show that our approach can boost the performance of state-of-the-art methods. Our code and data are publicly available at the link: \url{https://github.com/RUCAIBox/Data-CUBE}.
C2-CRS: Coarse-to-Fine Contrastive Learning for Conversational Recommender System
Jan 04, 2022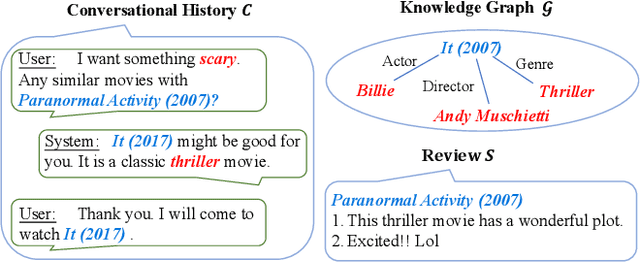
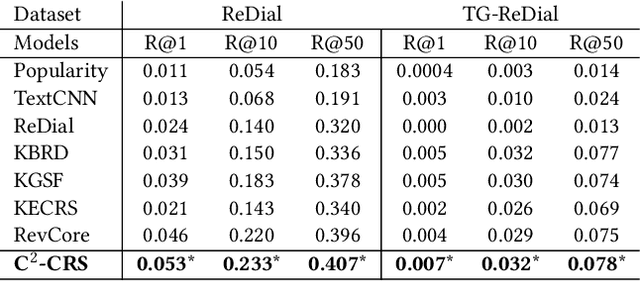
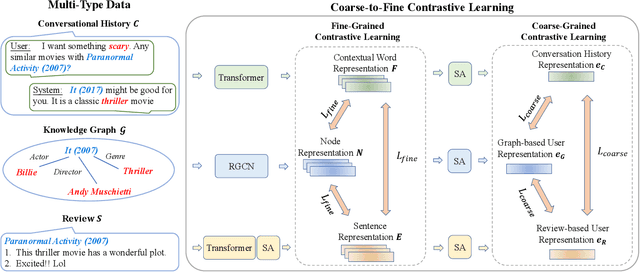
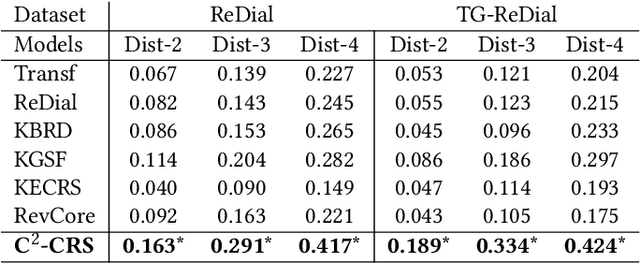
Conversational recommender systems (CRS) aim to recommend suitable items to users through natural language conversations. For developing effective CRSs, a major technical issue is how to accurately infer user preference from very limited conversation context. To address issue, a promising solution is to incorporate external data for enriching the context information. However, prior studies mainly focus on designing fusion models tailored for some specific type of external data, which is not general to model and utilize multi-type external data. To effectively leverage multi-type external data, we propose a novel coarse-to-fine contrastive learning framework to improve data semantic fusion for CRS. In our approach, we first extract and represent multi-grained semantic units from different data signals, and then align the associated multi-type semantic units in a coarse-to-fine way. To implement this framework, we design both coarse-grained and fine-grained procedures for modeling user preference, where the former focuses on more general, coarse-grained semantic fusion and the latter focuses on more specific, fine-grained semantic fusion. Such an approach can be extended to incorporate more kinds of external data. Extensive experiments on two public CRS datasets have demonstrated the effectiveness of our approach in both recommendation and conversation tasks.