 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
Apr 22, 2026We present LLaDA2.0-Uni, a unified discrete diffusion large language model (dLLM) that supports multimodal understanding and generation within a natively integrated framework. Its architecture combines a fully semantic discrete tokenizer, a MoE-based dLLM backbone, and a diffusion decoder. By discretizing continuous visual inputs via SigLIP-VQ, the model enables block-level masked diffusion for both text and vision inputs within the backbone, while the decoder reconstructs visual tokens into high-fidelity images. Inference efficiency is enhanced beyond parallel decoding through prefix-aware optimizations in the backbone and few-step distillation in the decoder. Supported by carefully curated large-scale data and a tailored multi-stage training pipeline, LLaDA2.0-Uni matches specialized VLMs in multimodal understanding while delivering strong performance in image generation and editing. Its native support for interleaved generation and reasoning establishes a promising and scalable paradigm for next-generation unified foundation models. Codes and models are available at https://github.com/inclusionAI/LLaDA2.0-Uni.
Diversity or Precision? A Deep Dive into Next Token Prediction
Dec 28, 2025Recent advancements have shown that reinforcement learning (RL) can substantially improve the reasoning abilities of large language models (LLMs). The effectiveness of such RL training, however, depends critically on the exploration space defined by the pre-trained model's token-output distribution. In this paper, we revisit the standard cross-entropy loss, interpreting it as a specific instance of policy gradient optimization applied within a single-step episode. To systematically study how the pre-trained distribution shapes the exploration potential for subsequent RL, we propose a generalized pre-training objective that adapts on-policy RL principles to supervised learning. By framing next-token prediction as a stochastic decision process, we introduce a reward-shaping strategy that explicitly balances diversity and precision. Our method employs a positive reward scaling factor to control probability concentration on ground-truth tokens and a rank-aware mechanism that treats high-ranking and low-ranking negative tokens asymmetrically. This allows us to reshape the pre-trained token-output distribution and investigate how to provide a more favorable exploration space for RL, ultimately enhancing end-to-end reasoning performance. Contrary to the intuition that higher distribution entropy facilitates effective exploration, we find that imposing a precision-oriented prior yields a superior exploration space for RL.
Grove MoE: Towards Efficient and Superior MoE LLMs with Adjugate Experts
Aug 11, 2025The Mixture of Experts (MoE) architecture is a cornerstone of modern state-of-the-art (SOTA) large language models (LLMs). MoE models facilitate scalability by enabling sparse parameter activation. However, traditional MoE architecture uses homogeneous experts of a uniform size, activating a fixed number of parameters irrespective of input complexity and thus limiting computational efficiency. To overcome this limitation, we introduce Grove MoE, a novel architecture incorporating experts of varying sizes, inspired by the heterogeneous big.LITTLE CPU architecture. This architecture features novel adjugate experts with a dynamic activation mechanism, enabling model capacity expansion while maintaining manageable computational overhead. Building on this architecture, we present GroveMoE-Base and GroveMoE-Inst, 33B-parameter LLMs developed by applying an upcycling strategy to the Qwen3-30B-A3B-Base model during mid-training and post-training. GroveMoE models dynamically activate 3.14-3.28B parameters based on token complexity and achieve performance comparable to SOTA open-source models of similar or even larger size.
Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis
May 19, 2025Graphical user interface (GUI) grounding, the ability to map natural language instructions to specific actions on graphical user interfaces, remains a critical bottleneck in computer use agent development. Current benchmarks oversimplify grounding tasks as short referring expressions, failing to capture the complexity of real-world interactions that require software commonsense, layout understanding, and fine-grained manipulation capabilities. To address these limitations, we introduce OSWorld-G, a comprehensive benchmark comprising 564 finely annotated samples across diverse task types including text matching, element recognition, layout understanding, and precise manipulation. Additionally, we synthesize and release the largest computer use grounding dataset Jedi, which contains 4 million examples through multi-perspective decoupling of tasks. Our multi-scale models trained on Jedi demonstrate its effectiveness by outperforming existing approaches on ScreenSpot-v2, ScreenSpot-Pro, and our OSWorld-G. Furthermore, we demonstrate that improved grounding with Jedi directly enhances agentic capabilities of general foundation models on complex computer tasks, improving from 5% to 27% on OSWorld. Through detailed ablation studies, we identify key factors contributing to grounding performance and verify that combining specialized data for different interface elements enables compositional generalization to novel interfaces. All benchmark, data, checkpoints, and code are open-sourced and available at https://osworld-grounding.github.io.
On-Policy Optimization with Group Equivalent Preference for Multi-Programming Language Understanding
May 19, 2025Large language models (LLMs) achieve remarkable performance in code generation tasks. However, a significant performance disparity persists between popular programming languages (e.g., Python, C++) and others. To address this capability gap, we leverage the code translation task to train LLMs, thereby facilitating the transfer of coding proficiency across diverse programming languages. Moreover, we introduce OORL for training, a novel reinforcement learning (RL) framework that integrates on-policy and off-policy strategies. Within OORL, on-policy RL is applied during code translation, guided by a rule-based reward signal derived from unit tests. Complementing this coarse-grained rule-based reward, we propose Group Equivalent Preference Optimization (GEPO), a novel preference optimization method. Specifically, GEPO trains the LLM using intermediate representations (IRs) groups. LLMs can be guided to discern IRs equivalent to the source code from inequivalent ones, while also utilizing signals about the mutual equivalence between IRs within the group. This process allows LLMs to capture nuanced aspects of code functionality. By employing OORL for training with code translation tasks, LLMs improve their recognition of code functionality and their understanding of the relationships between code implemented in different languages. Extensive experiments demonstrate that our OORL for LLMs training with code translation tasks achieves significant performance improvements on code benchmarks across multiple programming languages.
ToTRL: Unlock LLM Tree-of-Thoughts Reasoning Potential through Puzzles Solving
May 19, 2025
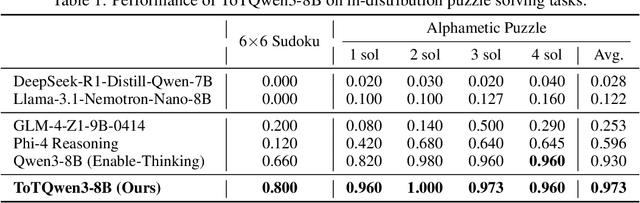
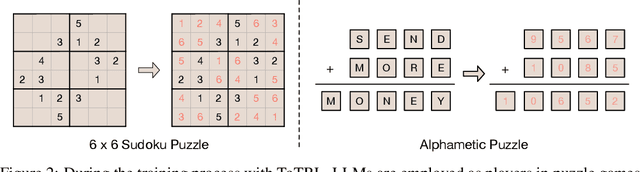
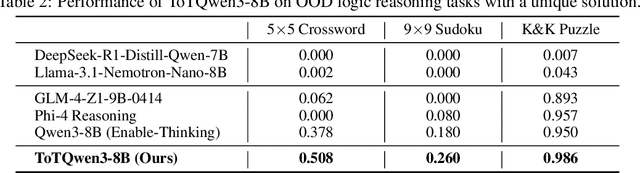
Large language models (LLMs) demonstrate significant reasoning capabilities, particularly through long chain-of-thought (CoT) processes, which can be elicited by reinforcement learning (RL). However, prolonged CoT reasoning presents limitations, primarily verbose outputs due to excessive introspection. The reasoning process in these LLMs often appears to follow a trial-and-error methodology rather than a systematic, logical deduction. In contrast, tree-of-thoughts (ToT) offers a conceptually more advanced approach by modeling reasoning as an exploration within a tree structure. This reasoning structure facilitates the parallel generation and evaluation of multiple reasoning branches, allowing for the active identification, assessment, and pruning of unproductive paths. This process can potentially lead to improved performance and reduced token costs. Building upon the long CoT capability of LLMs, we introduce tree-of-thoughts RL (ToTRL), a novel on-policy RL framework with a rule-based reward. ToTRL is designed to guide LLMs in developing the parallel ToT strategy based on the sequential CoT strategy. Furthermore, we employ LLMs as players in a puzzle game during the ToTRL training process. Solving puzzle games inherently necessitates exploring interdependent choices and managing multiple constraints, which requires the construction and exploration of a thought tree, providing challenging tasks for cultivating the ToT reasoning capability. Our empirical evaluations demonstrate that our ToTQwen3-8B model, trained with our ToTRL, achieves significant improvement in performance and reasoning efficiency on complex reasoning tasks.
Architect of the Bits World: Masked Autoregressive Modeling for Circuit Generation Guided by Truth Table
Feb 18, 2025Logic synthesis, a critical stage in electronic design automation (EDA), optimizes gate-level circuits to minimize power consumption and area occupancy in integrated circuits (ICs). Traditional logic synthesis tools rely on human-designed heuristics, often yielding suboptimal results. Although differentiable architecture search (DAS) has shown promise in generating circuits from truth tables, it faces challenges such as high computational complexity, convergence to local optima, and extensive hyperparameter tuning. Consequently, we propose a novel approach integrating conditional generative models with DAS for circuit generation. Our approach first introduces CircuitVQ, a circuit tokenizer trained based on our Circuit AutoEncoder We then develop CircuitAR, a masked autoregressive model leveraging CircuitVQ as the tokenizer. CircuitAR can generate preliminary circuit structures from truth tables, which guide DAS in producing functionally equivalent circuits. Notably, we observe the scalability and emergent capability in generating complex circuit structures of our CircuitAR models. Extensive experiments also show the superior performance of our method. This research bridges the gap between probabilistic generative models and precise circuit generation, offering a robust solution for logic synthesis.
Efficient OpAmp Adaptation for Zoom Attention to Golden Contexts
Feb 18, 2025Large language models (LLMs) have shown significant promise in question-answering (QA) tasks, particularly in retrieval-augmented generation (RAG) scenarios and long-context applications. However, their performance is hindered by noisy reference documents, which often distract from essential information. Despite fine-tuning efforts, Transformer-based architectures struggle to prioritize relevant content. This is evidenced by their tendency to allocate disproportionate attention to irrelevant or later-positioned documents. Recent work proposes the differential attention mechanism to address this issue, but this mechanism is limited by an unsuitable common-mode rejection ratio (CMRR) and high computational costs. Inspired by the operational amplifier (OpAmp), we propose the OpAmp adaptation to address these challenges, which is implemented with adapters efficiently. By integrating the adapter into pre-trained Transformer blocks, our approach enhances focus on the golden context without costly training from scratch. Empirical evaluations on noisy-context benchmarks reveal that our Qwen2.5-OpAmp-72B model, trained with our OpAmp adaptation, surpasses the performance of state-of-the-art LLMs, including DeepSeek-V3 and GPT-4o.
Circuit Representation Learning with Masked Gate Modeling and Verilog-AIG Alignment
Feb 18, 2025Understanding the structure and function of circuits is crucial for electronic design automation (EDA). Circuits can be formulated as And-Inverter graphs (AIGs), enabling efficient implementation of representation learning through graph neural networks (GNNs). Masked modeling paradigms have been proven effective in graph representation learning. However, masking augmentation to original circuits will destroy their logical equivalence, which is unsuitable for circuit representation learning. Moreover, existing masked modeling paradigms often prioritize structural information at the expense of abstract information such as circuit function. To address these limitations, we introduce MGVGA, a novel constrained masked modeling paradigm incorporating masked gate modeling (MGM) and Verilog-AIG alignment (VGA). Specifically, MGM preserves logical equivalence by masking gates in the latent space rather than in the original circuits, subsequently reconstructing the attributes of these masked gates. Meanwhile, large language models (LLMs) have demonstrated an excellent understanding of the Verilog code functionality. Building upon this capability, VGA performs masking operations on original circuits and reconstructs masked gates under the constraints of equivalent Verilog codes, enabling GNNs to learn circuit functions from LLMs. We evaluate MGVGA on various logic synthesis tasks for EDA and show the superior performance of MGVGA compared to previous state-of-the-art methods. Our code is available at https://github.com/wuhy68/MGVGA.
Customized Retrieval Augmented Generation and Benchmarking for EDA Tool Documentation QA
Jul 26, 2024Retrieval augmented generation (RAG) enhances the accuracy and reliability of generative AI models by sourcing factual information from external databases, which is extensively employed in document-grounded question-answering (QA) tasks. Off-the-shelf RAG flows are well pretrained on general-purpose documents, yet they encounter significant challenges when being applied to knowledge-intensive vertical domains, such as electronic design automation (EDA). This paper addresses such issue by proposing a customized RAG framework along with three domain-specific techniques for EDA tool documentation QA, including a contrastive learning scheme for text embedding model fine-tuning, a reranker distilled from proprietary LLM, and a generative LLM fine-tuned with high-quality domain corpus. Furthermore, we have developed and released a documentation QA evaluation benchmark, ORD-QA, for OpenROAD, an advanced RTL-to-GDSII design platform. Experimental results demonstrate that our proposed RAG flow and techniques have achieved superior performance on ORD-QA as well as on a commercial tool, compared with state-of-the-arts. The ORD-QA benchmark and the training dataset for our customized RAG flow are open-source at https://github.com/lesliepy99/RAG-EDA.