 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs
Mar 19, 2026Recent advancements in omnimodal large language models (OmniLLMs) have significantly improved the comprehension of audio and video inputs. However, current evaluations primarily focus on short audio and video clips ranging from 10 seconds to 5 minutes, failing to reflect the demands of real-world applications, where videos typically run for tens of minutes. To address this critical gap, we introduce LVOmniBench, a new benchmark designed specifically for the cross-modal comprehension of long-form audio and video. This dataset comprises high-quality videos sourced from open platforms that feature rich audio-visual dynamics. Through rigorous manual selection and annotation, LVOmniBench comprises 275 videos, ranging in duration from 10 to 90 minutes, and 1,014 question-answer (QA) pairs. LVOmniBench aims to rigorously evaluate the capabilities of OmniLLMs across domains, including long-term memory, temporal localization, fine-grained understanding, and multimodal perception. Our extensive evaluation reveals that current OmniLLMs encounter significant challenges when processing extended audio-visual inputs. Open-source models generally achieve accuracies below 35%, whereas the Gemini 3 Pro reaches a peak accuracy of approximately 65%. We anticipate that this dataset, along with our empirical findings, will stimulate further research and the development of advanced models capable of resolving complex cross-modal understanding problems within long-form audio-visual contexts.
MobileKernelBench: Can LLMs Write Efficient Kernels for Mobile Devices?
Mar 12, 2026Large language models (LLMs) have demonstrated remarkable capabilities in code generation, yet their potential for generating kernels specifically for mobile de- vices remains largely unexplored. In this work, we extend the scope of automated kernel generation to the mobile domain to investigate the central question: Can LLMs write efficient kernels for mobile devices? To enable systematic investigation, we introduce MobileKernelBench, a comprehensive evaluation framework comprising a benchmark prioritizing operator diversity and cross-framework interoperability, coupled with an automated pipeline that bridges the host-device gap for on-device verification. Leveraging this framework, we conduct extensive evaluation on the CPU backend of Mobile Neural Network (MNN), revealing that current LLMs struggle with the engineering complexity and data scarcity inher-ent to mobile frameworks; standard models and even fine-tuned variants exhibit high compilation failure rates (over 54%) and negligible performance gains due to hallucinations and a lack of domain-specific grounding. To overcome these limitations, we propose the Mobile K ernel A gent (MoKA), a multi-agent system equipped with repository-aware reasoning and a plan-and-execute paradigm.Validated on MobileKernelBench, MoKA achieves state-of-the-art performance, boosting compilation success to 93.7% and enabling 27.4% of generated kernelsto deliver measurable speedups over native libraries.
DICE: Diffusion Large Language Models Excel at Generating CUDA Kernels
Feb 12, 2026Diffusion large language models (dLLMs) have emerged as a compelling alternative to autoregressive (AR) LLMs, owing to their capacity for parallel token generation. This paradigm is particularly well-suited for code generation, where holistic structural planning and non-sequential refinement are critical. Despite this potential, tailoring dLLMs for CUDA kernel generation remains challenging, obstructed not only by the high specialization but also by the severe lack of high-quality training data. To address these challenges, we construct CuKe, an augmented supervised fine-tuning dataset optimized for high-performance CUDA kernels. On top of it, we propose a bi-phase curated reinforcement learning (BiC-RL) framework consisting of a CUDA kernel infilling stage and an end-to-end CUDA kernel generation stage. Leveraging this training framework, we introduce DICE, a series of diffusion large language models designed for CUDA kernel generation, spanning three parameter scales, 1.7B, 4B, and 8B. Extensive experiments on KernelBench demonstrate that DICE significantly outperforms both autoregressive and diffusion LLMs of comparable scale, establishing a new state-of-the-art for CUDA kernel generation.
ToTRL: Unlock LLM Tree-of-Thoughts Reasoning Potential through Puzzles Solving
May 19, 2025
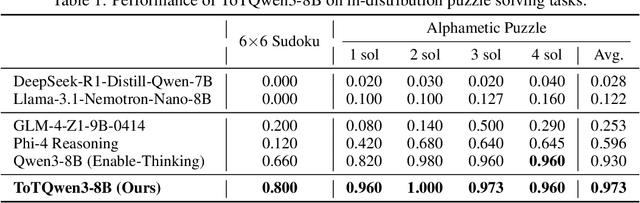
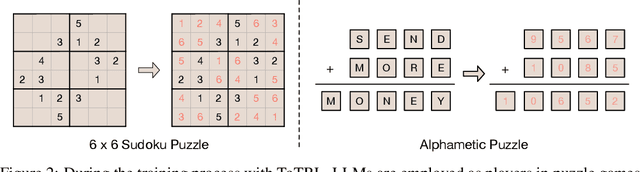
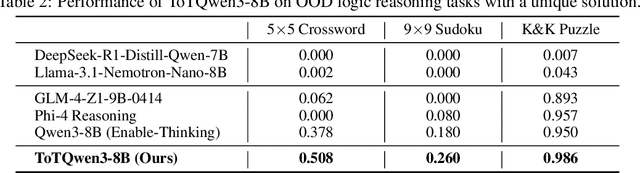
Large language models (LLMs) demonstrate significant reasoning capabilities, particularly through long chain-of-thought (CoT) processes, which can be elicited by reinforcement learning (RL). However, prolonged CoT reasoning presents limitations, primarily verbose outputs due to excessive introspection. The reasoning process in these LLMs often appears to follow a trial-and-error methodology rather than a systematic, logical deduction. In contrast, tree-of-thoughts (ToT) offers a conceptually more advanced approach by modeling reasoning as an exploration within a tree structure. This reasoning structure facilitates the parallel generation and evaluation of multiple reasoning branches, allowing for the active identification, assessment, and pruning of unproductive paths. This process can potentially lead to improved performance and reduced token costs. Building upon the long CoT capability of LLMs, we introduce tree-of-thoughts RL (ToTRL), a novel on-policy RL framework with a rule-based reward. ToTRL is designed to guide LLMs in developing the parallel ToT strategy based on the sequential CoT strategy. Furthermore, we employ LLMs as players in a puzzle game during the ToTRL training process. Solving puzzle games inherently necessitates exploring interdependent choices and managing multiple constraints, which requires the construction and exploration of a thought tree, providing challenging tasks for cultivating the ToT reasoning capability. Our empirical evaluations demonstrate that our ToTQwen3-8B model, trained with our ToTRL, achieves significant improvement in performance and reasoning efficiency on complex reasoning tasks.
On-Policy Optimization with Group Equivalent Preference for Multi-Programming Language Understanding
May 19, 2025Large language models (LLMs) achieve remarkable performance in code generation tasks. However, a significant performance disparity persists between popular programming languages (e.g., Python, C++) and others. To address this capability gap, we leverage the code translation task to train LLMs, thereby facilitating the transfer of coding proficiency across diverse programming languages. Moreover, we introduce OORL for training, a novel reinforcement learning (RL) framework that integrates on-policy and off-policy strategies. Within OORL, on-policy RL is applied during code translation, guided by a rule-based reward signal derived from unit tests. Complementing this coarse-grained rule-based reward, we propose Group Equivalent Preference Optimization (GEPO), a novel preference optimization method. Specifically, GEPO trains the LLM using intermediate representations (IRs) groups. LLMs can be guided to discern IRs equivalent to the source code from inequivalent ones, while also utilizing signals about the mutual equivalence between IRs within the group. This process allows LLMs to capture nuanced aspects of code functionality. By employing OORL for training with code translation tasks, LLMs improve their recognition of code functionality and their understanding of the relationships between code implemented in different languages. Extensive experiments demonstrate that our OORL for LLMs training with code translation tasks achieves significant performance improvements on code benchmarks across multiple programming languages.