 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Detail-Preserved Completion of Complex Tubular Structures based on Point Cloud: a Dataset and a Benchmark
Aug 25, 2025



Complex tubular structures are essential in medical imaging and computer-assisted diagnosis, where their integrity enhances anatomical visualization and lesion detection. However, existing segmentation algorithms struggle with structural discontinuities, particularly in severe clinical cases such as coronary artery stenosis and vessel occlusions, which leads to undesired discontinuity and compromising downstream diagnostic accuracy. Therefore, it is imperative to reconnect discontinuous structures to ensure their completeness. In this study, we explore the tubular structure completion based on point cloud for the first time and establish a Point Cloud-based Coronary Artery Completion (PC-CAC) dataset, which is derived from real clinical data. This dataset provides a novel benchmark for tubular structure completion. Additionally, we propose TSRNet, a Tubular Structure Reconnection Network that integrates a detail-preservated feature extractor, a multiple dense refinement strategy, and a global-to-local loss function to ensure accurate reconnection while maintaining structural integrity. Comprehensive experiments on our PC-CAC and two additional public datasets (PC-ImageCAS and PC-PTR) demonstrate that our method consistently outperforms state-of-the-art approaches across multiple evaluation metrics, setting a new benchmark for point cloud-based tubular structure reconstruction. Our benchmark is available at https://github.com/YaoleiQi/PCCAC.
On-Policy Optimization with Group Equivalent Preference for Multi-Programming Language Understanding
May 19, 2025Large language models (LLMs) achieve remarkable performance in code generation tasks. However, a significant performance disparity persists between popular programming languages (e.g., Python, C++) and others. To address this capability gap, we leverage the code translation task to train LLMs, thereby facilitating the transfer of coding proficiency across diverse programming languages. Moreover, we introduce OORL for training, a novel reinforcement learning (RL) framework that integrates on-policy and off-policy strategies. Within OORL, on-policy RL is applied during code translation, guided by a rule-based reward signal derived from unit tests. Complementing this coarse-grained rule-based reward, we propose Group Equivalent Preference Optimization (GEPO), a novel preference optimization method. Specifically, GEPO trains the LLM using intermediate representations (IRs) groups. LLMs can be guided to discern IRs equivalent to the source code from inequivalent ones, while also utilizing signals about the mutual equivalence between IRs within the group. This process allows LLMs to capture nuanced aspects of code functionality. By employing OORL for training with code translation tasks, LLMs improve their recognition of code functionality and their understanding of the relationships between code implemented in different languages. Extensive experiments demonstrate that our OORL for LLMs training with code translation tasks achieves significant performance improvements on code benchmarks across multiple programming languages.
Prospective Identification of Ictal Electroencephalogram
Mar 03, 2021
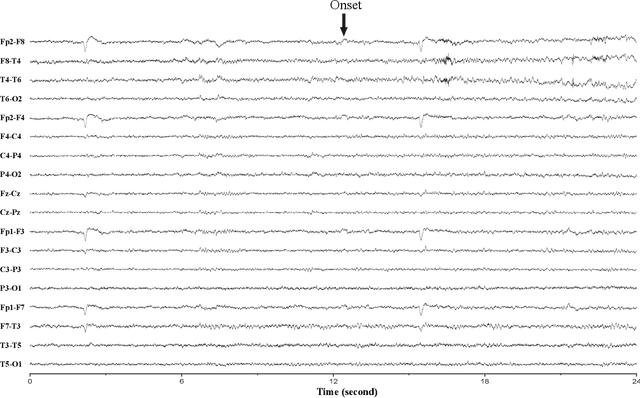
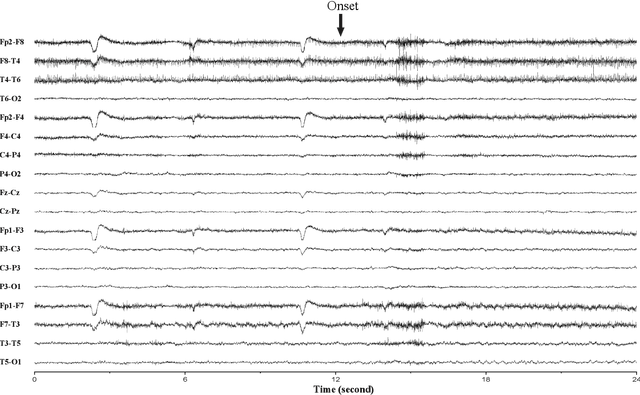
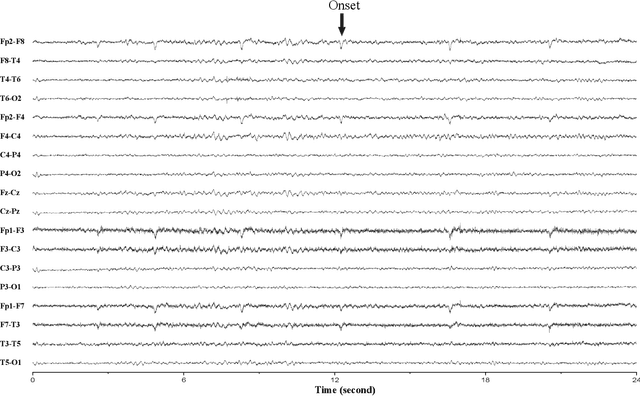
A vast majority of epileptic seizure (ictal) detection on electroencephalogram (EEG) data has been retrospective. Therefore, even though some may include many patients and extensive evaluation benchmarking, they all share a heavy reliance on labelled data. This is perhaps the most significant obstacle against the utility of seizure detection systems in clinical settings. In this paper, we present a prospective automatic ictal detection and labelling performed at the level of a human expert (arbiter) and reduces labelling time by more than an order of magnitude. Accurate seizure detection and labelling are still a time-consuming and cumbersome task in epilepsy monitoring units (EMUs) and epilepsy centres, particularly in countries with limited facilities and insufficiently trained human resources. This work implements a convolutional long short-term memory (ConvLSTM) network that is pre-trained and tested on Temple University Hospital (TUH) EEG corpus. It is then deployed prospectively at the Comprehensive Epilepsy Service at the Royal Prince Alfred Hospital (RPAH) in Sydney, Australia, testing nearly 14,590 hours of EEG data across nine years. Our system prospectively labelled RPAH epilepsy ward data and subsequently reviewed by two neurologists and three certified EEG specialists. Our clinical result shows the proposed method achieves a 92.19% detection rate for an average time of 7.62 mins per 24 hrs of recorded 18-channel EEG. A human expert usually requires about 2 hrs of reviewing and labelling per any 24 hrs of recorded EEG and is often assisted by a wide range of auxiliary data such as patient, carer, or nurse inputs. In this prospective analysis, we consider humans' role as an expert arbiter who confirms to reject each alarm raised by our system. We achieved an average of 56 false alarms per 24 hrs.