 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models
Feb 20, 2024We introduce Generalized Instruction Tuning (called GLAN), a general and scalable method for instruction tuning of Large Language Models (LLMs). Unlike prior work that relies on seed examples or existing datasets to construct instruction tuning data, GLAN exclusively utilizes a pre-curated taxonomy of human knowledge and capabilities as input and generates large-scale synthetic instruction data across all disciplines. Specifically, inspired by the systematic structure in human education system, we build the taxonomy by decomposing human knowledge and capabilities to various fields, sub-fields and ultimately, distinct disciplines semi-automatically, facilitated by LLMs. Subsequently, we generate a comprehensive list of subjects for every discipline and proceed to design a syllabus tailored to each subject, again utilizing LLMs. With the fine-grained key concepts detailed in every class session of the syllabus, we are able to generate diverse instructions with a broad coverage across the entire spectrum of human knowledge and skills. Extensive experiments on large language models (e.g., Mistral) demonstrate that GLAN excels in multiple dimensions from mathematical reasoning, coding, academic exams, logical reasoning to general instruction following without using task-specific training data of these tasks. In addition, GLAN allows for easy customization and new fields or skills can be added by simply incorporating a new node into our taxonomy.
One-stop Training of Multiple Capacity Models
May 24, 2023



Training models with varying capacities can be advantageous for deploying them in different scenarios. While high-capacity models offer better performance, low-capacity models require fewer computing resources for training and inference. In this work, we propose a novel one-stop training framework to jointly train high-capacity and low-capactiy models. This framework consists of two composite model architectures and a joint training algorithm called Two-Stage Joint-Training (TSJT). Unlike knowledge distillation, where multiple capacity models are trained from scratch separately, our approach integrates supervisions from different capacity models simultaneously, leading to faster and more efficient convergence. Extensive experiments on the multilingual machine translation benchmark WMT10 show that our method outperforms low-capacity baseline models and achieves comparable or better performance on high-capacity models. Notably, the analysis demonstrates that our method significantly influences the initial training process, leading to more efficient convergence and superior solutions.
Not All Metrics Are Guilty: Improving NLG Evaluation with LLM Paraphrasing
May 24, 2023



Most research about natural language generation (NLG) relies on evaluation benchmarks with limited references for a sample, which may result in poor correlations with human judgements. The underlying reason is that one semantic meaning can actually be expressed in different forms, and the evaluation with a single or few references may not accurately reflect the quality of the model's hypotheses. To address this issue, this paper presents a novel method, named Para-Ref, to enhance existing evaluation benchmarks by enriching the number of references. We leverage large language models (LLMs) to paraphrase a single reference into multiple high-quality ones in diverse expressions. Experimental results on representative NLG tasks of machine translation, text summarization, and image caption demonstrate that our method can effectively improve the correlation with human evaluation for sixteen automatic evaluation metrics by +7.82% in ratio. We release the code and data at https://github.com/RUCAIBox/Para-Ref.
Chain-of-Dictionary Prompting Elicits Translation in Large Language Models
May 24, 2023



Large language models (LLMs) have shown surprisingly good performance in multilingual neural machine translation (MNMT) even when trained without parallel data. Yet, despite the fact that the amount of training data is gigantic, they still struggle with translating rare words, particularly for low-resource languages. Even worse, it is usually unrealistic to retrieve relevant demonstrations for in-context learning with low-resource languages on LLMs, which restricts the practical use of LLMs for translation -- how should we mitigate this problem? To this end, we present a novel method, CoD, which augments LLMs with prior knowledge with the chains of multilingual dictionaries for a subset of input words to elicit translation abilities for LLMs. Extensive experiments indicate that augmenting ChatGPT with CoD elicits large gains by up to 13x chrF++ points for MNMT (3.08 to 42.63 for English to Serbian written in Cyrillic script) on FLORES-200 full devtest set. We further demonstrate the importance of chaining the multilingual dictionaries, as well as the superiority of CoD to few-shot demonstration for low-resource languages.
Not All Languages Are Created Equal in LLMs: Improving Multilingual Capability by Cross-Lingual-Thought Prompting
May 11, 2023



Large language models (LLMs) demonstrate impressive multilingual capability, but their performance varies substantially across different languages. In this work, we introduce a simple yet effective method, called cross-lingual-thought prompting (XLT), to systematically improve the multilingual capability of LLMs. Specifically, XLT is a generic template prompt that stimulates cross-lingual and logical reasoning skills to enhance task performance across languages. We conduct comprehensive evaluations on 7 typical benchmarks related to reasoning, understanding, and generation tasks, covering both high-resource and low-resource languages. Experimental results show that XLT not only remarkably enhances the performance of various multilingual tasks but also significantly reduces the gap between the average performance and the best performance of each task in different languages. Notably, XLT brings over 10 points of average improvement in arithmetic reasoning and open-domain question-answering tasks.
HanoiT: Enhancing Context-aware Translation via Selective Context
Jan 17, 2023Context-aware neural machine translation aims to use the document-level context to improve translation quality. However, not all words in the context are helpful. The irrelevant or trivial words may bring some noise and distract the model from learning the relationship between the current sentence and the auxiliary context. To mitigate this problem, we propose a novel end-to-end encoder-decoder model with a layer-wise selection mechanism to sift and refine the long document context. To verify the effectiveness of our method, extensive experiments and extra quantitative analysis are conducted on four document-level machine translation benchmarks. The experimental results demonstrate that our model significantly outperforms previous models on all datasets via the soft selection mechanism.
GanLM: Encoder-Decoder Pre-training with an Auxiliary Discriminator
Dec 20, 2022



Pre-trained models have achieved remarkable success in natural language processing (NLP). However, existing pre-training methods underutilize the benefits of language understanding for generation. Inspired by the idea of Generative Adversarial Networks (GANs), we propose a GAN-style model for encoder-decoder pre-training by introducing an auxiliary discriminator, unifying the ability of language understanding and generation in a single model. Our model, named as GanLM, is trained with two pre-training objectives: replaced token detection and replaced token denoising. Specifically, given masked source sentences, the generator outputs the target distribution and the discriminator predicts whether the target sampled tokens from distribution are incorrect. The target sentence is replaced with misclassified tokens to construct noisy previous context, which is used to generate the gold sentence. In general, both tasks improve the ability of language understanding and generation by selectively using the denoising data. Extensive experiments in language generation benchmarks show that GanLM with the powerful language understanding capability outperforms various strong pre-trained language models (PLMs) and achieves state-of-the-art performance.
TRIP: Triangular Document-level Pre-training for Multilingual Language Models
Dec 15, 2022



Despite the current success of multilingual pre-training, most prior works focus on leveraging monolingual data or bilingual parallel data and overlooked the value of trilingual parallel data. This paper presents \textbf{Tri}angular Document-level \textbf{P}re-training (\textbf{TRIP}), which is the first in the field to extend the conventional monolingual and bilingual pre-training to a trilingual setting by (i) \textbf{Grafting} the same documents in two languages into one mixed document, and (ii) predicting the remaining one language as the reference translation. Our experiments on document-level MT and cross-lingual abstractive summarization show that TRIP brings by up to 3.65 d-BLEU points and 6.2 ROUGE-L points on three multilingual document-level machine translation benchmarks and one cross-lingual abstractive summarization benchmark, including multiple strong state-of-the-art (SOTA) scores. In-depth analysis indicates that TRIP improves document-level machine translation and captures better document contexts in at least three characteristics: (i) tense consistency, (ii) noun consistency and (iii) conjunction presence.
Multilingual Transitivity and Bidirectional Multilingual Agreement for Multilingual Document-level Machine Translation
Oct 05, 2022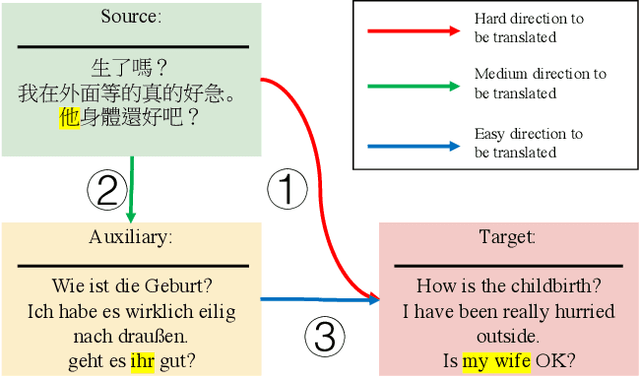
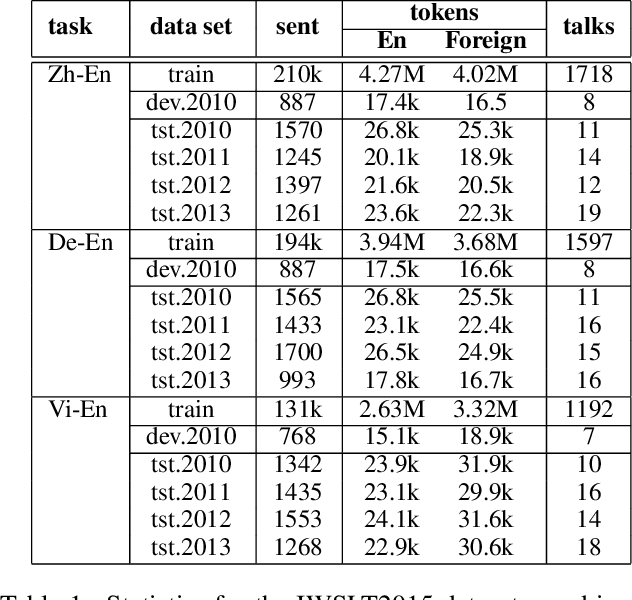
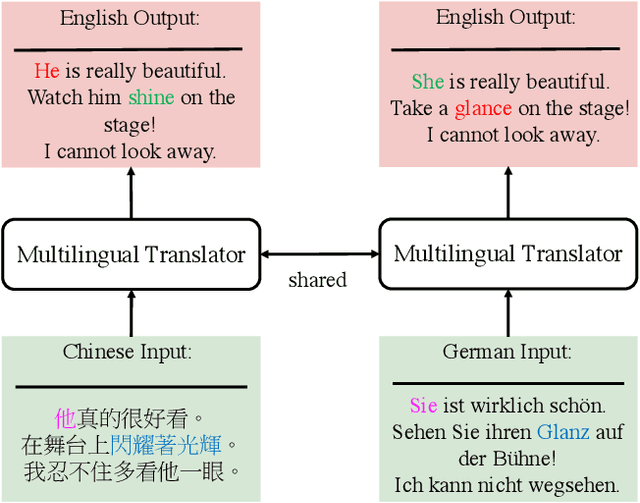

Multilingual machine translation has been proven an effective strategy to support translation between multiple languages with a single model. However, most studies focus on multilingual sentence translation without considering generating long documents across different languages, which requires an understanding of multilingual context dependency and is typically harder. In this paper, we first spot that naively incorporating auxiliary multilingual data either auxiliary-target or source-auxiliary brings no improvement to the source-target language pair in our interest. Motivated by this observation, we propose a novel framework called Multilingual Transitivity (MTrans) to find an implicit optimal route via source-auxiliary-target within the multilingual model. To encourage MTrans, we propose a novel method called Triplet Parallel Data (TPD), which uses parallel triplets that contain (source-auxiliary, auxiliary-target, and source-target) for training. The auxiliary language then serves as a pivot and automatically facilitates the implicit information transition flow which is easier to translate. We further propose a novel framework called Bidirectional Multilingual Agreement (Bi-MAgree) that encourages the bidirectional agreement between different languages. To encourage Bi-MAgree, we propose a novel method called Multilingual Kullback-Leibler Divergence (MKL) that forces the output distribution of the inputs with the same meaning but in different languages to be consistent with each other. The experimental results indicate that our methods bring consistent improvements over strong baselines on three document translation tasks: IWSLT2015 Zh-En, De-En, and Vi-En. Our analysis validates the usefulness and existence of MTrans and Bi-MAgree, and our frameworks and methods are effective on synthetic auxiliary data.
GTrans: Grouping and Fusing Transformer Layers for Neural Machine Translation
Jul 29, 2022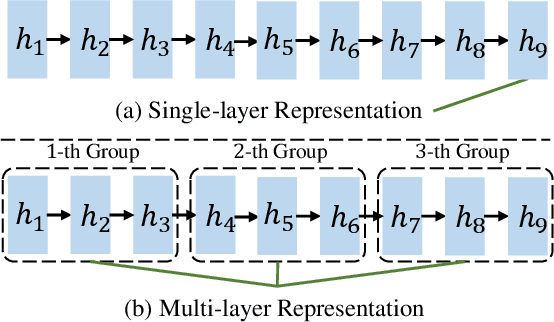
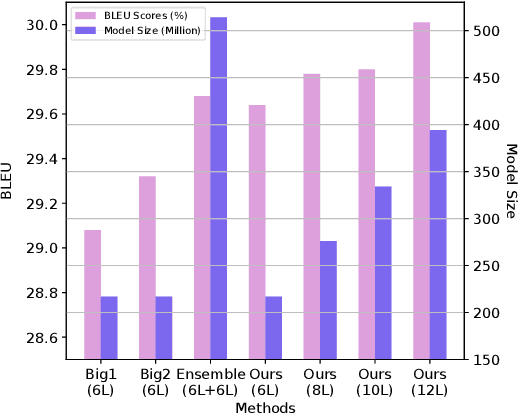
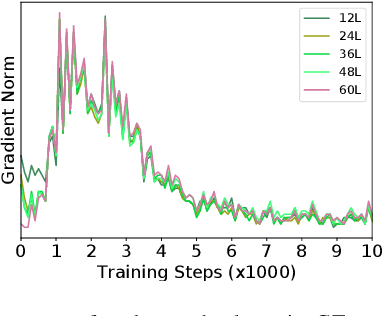
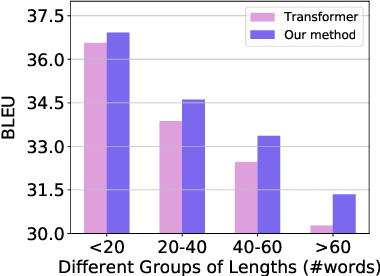
Transformer structure, stacked by a sequence of encoder and decoder network layers, achieves significant development in neural machine translation. However, vanilla Transformer mainly exploits the top-layer representation, assuming the lower layers provide trivial or redundant information and thus ignoring the bottom-layer feature that is potentially valuable. In this work, we propose the Group-Transformer model (GTrans) that flexibly divides multi-layer representations of both encoder and decoder into different groups and then fuses these group features to generate target words. To corroborate the effectiveness of the proposed method, extensive experiments and analytic experiments are conducted on three bilingual translation benchmarks and two multilingual translation tasks, including the IWLST-14, IWLST-17, LDC, WMT-14 and OPUS-100 benchmark. Experimental and analytical results demonstrate that our model outperforms its Transformer counterparts by a consistent gain. Furthermore, it can be successfully scaled up to 60 encoder layers and 36 decoder layers.