 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
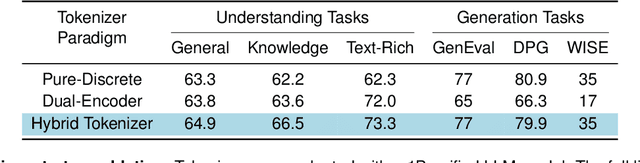
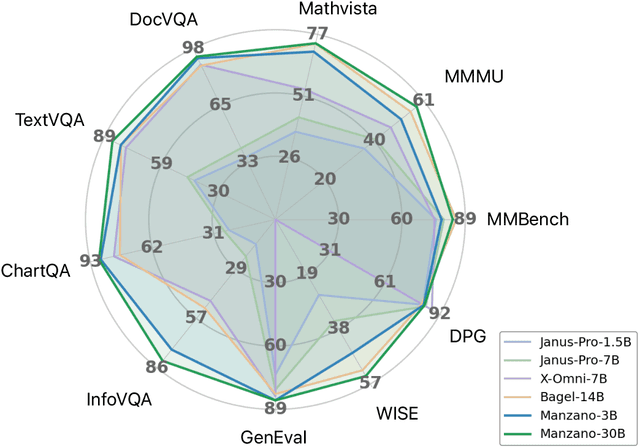
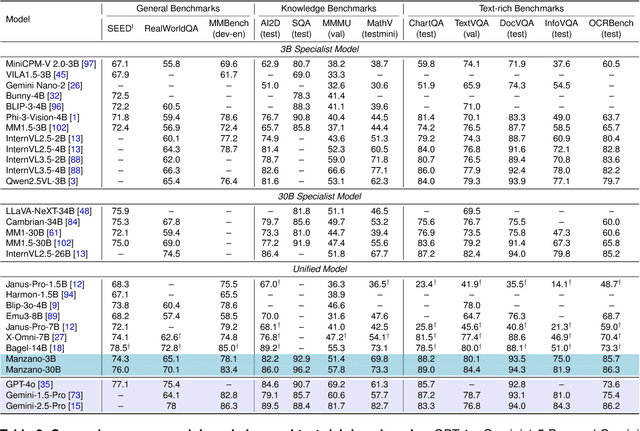
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios
Jul 27, 2025



Multimodal large language models (MLLMs) have made remarkable strides, largely driven by their ability to process increasingly long and complex contexts, such as high-resolution images, extended video sequences, and lengthy audio input. While this ability significantly enhances MLLM capabilities, it introduces substantial computational challenges, primarily due to the quadratic complexity of self-attention mechanisms with numerous input tokens. To mitigate these bottlenecks, token compression has emerged as an auspicious and critical approach, efficiently reducing the number of tokens during both training and inference. In this paper, we present the first systematic survey and synthesis of the burgeoning field of multimodal long context token compression. Recognizing that effective compression strategies are deeply tied to the unique characteristics and redundancies of each modality, we categorize existing approaches by their primary data focus, enabling researchers to quickly access and learn methods tailored to their specific area of interest: (1) image-centric compression, which addresses spatial redundancy in visual data; (2) video-centric compression, which tackles spatio-temporal redundancy in dynamic sequences; and (3) audio-centric compression, which handles temporal and spectral redundancy in acoustic signals. Beyond this modality-driven categorization, we further dissect methods based on their underlying mechanisms, including transformation-based, similarity-based, attention-based, and query-based approaches. By providing a comprehensive and structured overview, this survey aims to consolidate current progress, identify key challenges, and inspire future research directions in this rapidly evolving domain. We also maintain a public repository to continuously track and update the latest advances in this promising area.
HoliTom: Holistic Token Merging for Fast Video Large Language Models
May 28, 2025Video large language models (video LLMs) excel at video comprehension but face significant computational inefficiency due to redundant video tokens. Existing token pruning methods offer solutions. However, approaches operating within the LLM (inner-LLM pruning), such as FastV, incur intrinsic computational overhead in shallow layers. In contrast, methods performing token pruning before the LLM (outer-LLM pruning) primarily address spatial redundancy within individual frames or limited temporal windows, neglecting the crucial global temporal dynamics and correlations across longer video sequences. This leads to sub-optimal spatio-temporal reduction and does not leverage video compressibility fully. Crucially, the synergistic potential and mutual influence of combining these strategies remain unexplored. To further reduce redundancy, we introduce HoliTom, a novel training-free holistic token merging framework. HoliTom employs outer-LLM pruning through global redundancy-aware temporal segmentation, followed by spatial-temporal merging to reduce visual tokens by over 90%, significantly alleviating the LLM's computational burden. Complementing this, we introduce a robust inner-LLM token similarity-based merging approach, designed for superior performance and compatibility with outer-LLM pruning. Evaluations demonstrate our method's promising efficiency-performance trade-off on LLaVA-OneVision-7B, reducing computational costs to 6.9% of FLOPs while maintaining 99.1% of the original performance. Furthermore, we achieve a 2.28x reduction in Time-To-First-Token (TTFT) and a 1.32x acceleration in decoding throughput, highlighting the practical benefits of our integrated pruning approach for efficient video LLMs inference.
Plug-and-Play 1.x-Bit KV Cache Quantization for Video Large Language Models
Mar 20, 2025



Video large language models (VideoLLMs) have demonstrated the capability to process longer video inputs and enable complex reasoning and analysis. However, due to the thousands of visual tokens from the video frames, key-value (KV) cache can significantly increase memory requirements, becoming a bottleneck for inference speed and memory usage. KV cache quantization is a widely used approach to address this problem. In this paper, we find that 2-bit KV quantization of VideoLLMs can hardly hurt the model performance, while the limit of KV cache quantization in even lower bits has not been investigated. To bridge this gap, we introduce VidKV, a plug-and-play KV cache quantization method to compress the KV cache to lower than 2 bits. Specifically, (1) for key, we propose a mixed-precision quantization strategy in the channel dimension, where we perform 2-bit quantization for anomalous channels and 1-bit quantization combined with FFT for normal channels; (2) for value, we implement 1.58-bit quantization while selectively filtering semantically salient visual tokens for targeted preservation, for a better trade-off between precision and model performance. Importantly, our findings suggest that the value cache of VideoLLMs should be quantized in a per-channel fashion instead of the per-token fashion proposed by prior KV cache quantization works for LLMs. Empirically, extensive results with LLaVA-OV-7B and Qwen2.5-VL-7B on six benchmarks show that VidKV effectively compresses the KV cache to 1.5-bit and 1.58-bit precision with almost no performance drop compared to the FP16 counterparts.
DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models
Nov 22, 2024



Video large language models (VLLMs) have significantly advanced recently in processing complex video content, yet their inference efficiency remains constrained because of the high computational cost stemming from the thousands of visual tokens generated from the video inputs. We empirically observe that, unlike single image inputs, VLLMs typically attend visual tokens from different frames at different decoding iterations, making a one-shot pruning strategy prone to removing important tokens by mistake. Motivated by this, we present DyCoke, a training-free token compression method to optimize token representation and accelerate VLLMs. DyCoke incorporates a plug-and-play temporal compression module to minimize temporal redundancy by merging redundant tokens across frames, and applies dynamic KV cache reduction to prune spatially redundant tokens selectively. It ensures high-quality inference by dynamically retaining the critical tokens at each decoding step. Extensive experimental results demonstrate that DyCoke can outperform the prior SoTA counterparts, achieving 1.5X inference speedup, 1.4X memory reduction against the baseline VLLM, while still improving the performance, with no training.
MM-Ego: Towards Building Egocentric Multimodal LLMs
Oct 09, 2024



This research aims to comprehensively explore building a multimodal foundation model for egocentric video understanding. To achieve this goal, we work on three fronts. First, as there is a lack of QA data for egocentric video understanding, we develop a data engine that efficiently generates 7M high-quality QA samples for egocentric videos ranging from 30 seconds to one hour long, based on human-annotated data. This is currently the largest egocentric QA dataset. Second, we contribute a challenging egocentric QA benchmark with 629 videos and 7,026 questions to evaluate the models' ability in recognizing and memorizing visual details across videos of varying lengths. We introduce a new de-biasing evaluation method to help mitigate the unavoidable language bias present in the models being evaluated. Third, we propose a specialized multimodal architecture featuring a novel "Memory Pointer Prompting" mechanism. This design includes a global glimpse step to gain an overarching understanding of the entire video and identify key visual information, followed by a fallback step that utilizes the key visual information to generate responses. This enables the model to more effectively comprehend extended video content. With the data, benchmark, and model, we successfully build MM-Ego, an egocentric multimodal LLM that shows powerful performance on egocentric video understanding.
MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
Sep 30, 2024



We present MM1.5, a new family of multimodal large language models (MLLMs) designed to enhance capabilities in text-rich image understanding, visual referring and grounding, and multi-image reasoning. Building upon the MM1 architecture, MM1.5 adopts a data-centric approach to model training, systematically exploring the impact of diverse data mixtures across the entire model training lifecycle. This includes high-quality OCR data and synthetic captions for continual pre-training, as well as an optimized visual instruction-tuning data mixture for supervised fine-tuning. Our models range from 1B to 30B parameters, encompassing both dense and mixture-of-experts (MoE) variants, and demonstrate that careful data curation and training strategies can yield strong performance even at small scales (1B and 3B). Additionally, we introduce two specialized variants: MM1.5-Video, designed for video understanding, and MM1.5-UI, tailored for mobile UI understanding. Through extensive empirical studies and ablations, we provide detailed insights into the training processes and decisions that inform our final designs, offering valuable guidance for future research in MLLM development.
Detecting Multimodal Situations with Insufficient Context and Abstaining from Baseless Predictions
May 23, 2024



Despite the widespread adoption of Vision-Language Understanding (VLU) benchmarks such as VQA v2, OKVQA, A-OKVQA, GQA, VCR, SWAG, and VisualCOMET, our analysis reveals a pervasive issue affecting their integrity: these benchmarks contain samples where answers rely on assumptions unsupported by the provided context. Training models on such data foster biased learning and hallucinations as models tend to make similar unwarranted assumptions. To address this issue, we collect contextual data for each sample whenever available and train a context selection module to facilitate evidence-based model predictions. Strong improvements across multiple benchmarks demonstrate the effectiveness of our approach. Further, we develop a general-purpose Context-AwaRe Abstention (CARA) detector to identify samples lacking sufficient context and enhance model accuracy by abstaining from responding if the required context is absent. CARA exhibits generalization to new benchmarks it wasn't trained on, underscoring its utility for future VLU benchmarks in detecting or cleaning samples with inadequate context. Finally, we curate a Context Ambiguity and Sufficiency Evaluation (CASE) set to benchmark the performance of insufficient context detectors. Overall, our work represents a significant advancement in ensuring that vision-language models generate trustworthy and evidence-based outputs in complex real-world scenarios.
Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models
Apr 11, 2024



While Ferret seamlessly integrates regional understanding into the Large Language Model (LLM) to facilitate its referring and grounding capability, it poses certain limitations: constrained by the pre-trained fixed visual encoder and failed to perform well on broader tasks. In this work, we unveil Ferret-v2, a significant upgrade to Ferret, with three key designs. (1) Any resolution grounding and referring: A flexible approach that effortlessly handles higher image resolution, improving the model's ability to process and understand images in greater detail. (2) Multi-granularity visual encoding: By integrating the additional DINOv2 encoder, the model learns better and diverse underlying contexts for global and fine-grained visual information. (3) A three-stage training paradigm: Besides image-caption alignment, an additional stage is proposed for high-resolution dense alignment before the final instruction tuning. Experiments show that Ferret-v2 provides substantial improvements over Ferret and other state-of-the-art methods, thanks to its high-resolution scaling and fine-grained visual processing.
LLM-based Conversational AI Therapist for Daily Functioning Screening and Psychotherapeutic Intervention via Everyday Smart Devices
Mar 16, 2024



Despite the global mental health crisis, access to screenings, professionals, and treatments remains high. In collaboration with licensed psychotherapists, we propose a Conversational AI Therapist with psychotherapeutic Interventions (CaiTI), a platform that leverages large language models (LLM)s and smart devices to enable better mental health self-care. CaiTI can screen the day-to-day functioning using natural and psychotherapeutic conversations. CaiTI leverages reinforcement learning to provide personalized conversation flow. CaiTI can accurately understand and interpret user responses. When the user needs further attention during the conversation, CaiTI can provide conversational psychotherapeutic interventions, including cognitive behavioral therapy (CBT) and motivational interviewing (MI). Leveraging the datasets prepared by the licensed psychotherapists, we experiment and microbenchmark various LLMs' performance in tasks along CaiTI's conversation flow and discuss their strengths and weaknesses. With the psychotherapists, we implement CaiTI and conduct 14-day and 24-week studies. The study results, validated by therapists, demonstrate that CaiTI can converse with users naturally, accurately understand and interpret user responses, and provide psychotherapeutic interventions appropriately and effectively. We showcase the potential of CaiTI LLMs to assist the mental therapy diagnosis and treatment and improve day-to-day functioning screening and precautionary psychotherapeutic intervention systems.