 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoRegressive Generation with B-rep Holistic Token Sequence Representation
Jan 23, 2026Previous representation and generation approaches for the B-rep relied on graph-based representations that disentangle geometric and topological features through decoupled computational pipelines, thereby precluding the application of sequence-based generative frameworks, such as transformer architectures that have demonstrated remarkable performance. In this paper, we propose BrepARG, the first attempt to encode B-rep's geometry and topology into a holistic token sequence representation, enabling sequence-based B-rep generation with an autoregressive architecture. Specifically, BrepARG encodes B-rep into 3 types of tokens: geometry and position tokens representing geometric features, and face index tokens representing topology. Then the holistic token sequence is constructed hierarchically, starting with constructing the geometry blocks (i.e., faces and edges) using the above tokens, followed by geometry block sequencing. Finally, we assemble the holistic sequence representation for the entire B-rep. We also construct a transformer-based autoregressive model that learns the distribution over holistic token sequences via next-token prediction, using a multi-layer decoder-only architecture with causal masking. Experiments demonstrate that BrepARG achieves state-of-the-art (SOTA) performance. BrepARG validates the feasibility of representing B-rep as holistic token sequences, opening new directions for B-rep generation.
LarS-Net: A Large-Scale Framework for Network-Level Spectrum Sensing
Jan 16, 2026As the demand of wireless communication continues to rise, the radio spectrum (a finite resource) requires increasingly efficient utilization. This trend is driving the evolution from static, stand-alone spectrum allocation toward spectrum sharing and dynamic spectrum sharing. A critical element of this transition is spectrum sensing, which facilitates informed decision-making in shared environments. Previous studies on spectrum sensing and cognitive radio have been largely limited to individual sensors or small sensor groups. In this work, a large-scale spectrum sensing network (LarS-Net) is designed in a cost-effective manner. Spectrum sensors are either co-located with base stations (BSs) to share the tower, backhaul, and power infrastructure, or integrated directly into BSs as a new feature leveraging active BS antenna systems. As an example incumbent system, fixed service microwave link operating in the lower-7 GHz band is investigated. This band is a primary candidate for 6G, being considered by the WRC-23, ITU, and FCC. Based on Monte Carlo simulations, we determine the minimum subset of BSs equipped with sensing capability to guarantee a target incumbent detection probability. The simulations account for various sensor antenna configurations, propagation channel models, and duty cycles for both incumbent transmissions and sensing operations. Building on this framework, we introduce three network-level sensing performance metrics: Emission Detection Probability (EDP), Temporal Detection Probability (TDP), and Temporal Mis-detection Probability (TMP), which jointly capture spatial coverage, temporal detectability, and multi-node diversity effects. Using these metrics, we analyze the impact of LarS-Net inter-site distance, noise uncertainty, and sensing duty-cycle on large-scale sensing performance.
AI-Driven Spectrum Occupancy Prediction Using Real-World Spectrum Measurements
Jan 16, 2026Spectrum occupancy prediction is a critical enabler for real-time and proactive dynamic spectrum sharing (DSS), as it can provide short-term channel availability information to support more efficient spectrum access decisions in wireless communication systems. Instead of relying on open-source datasets or simulated data, commonly used in the literature, this paper investigates short-horizon spectrum occupancy prediction using mid-band, 24X7 real-world spectrum measurement data collected in the United States. We construct a multi-band channel occupancy dataset through analyzing 61 days of empirical data and formulate a next-minute channel occupancy prediction task across all frequency channels. This study focuses on AI-driven prediction methods, including Random Forest, Extreme Gradient Boosting (XGBoost), and a Long Short-Term Memory (LSTM) network, and compares their performance against a conventional Markov chain-based statistical baseline. Numerical results show that learning-based methods outperform the statistical baseline on dynamic channels, particularly under fixed false-alarm constraints. These results demonstrate the effectiveness of AI-driven spectrum occupancy prediction, indicating that lightweight learning models can effectively support future deployment-oriented DSS systems.
Automated Spectrum Sensing and Analysis Framework
Jan 16, 2026Spectrum sensing and analysis is crucial for a variety of reasons, including regulatory compliance, interference detection and mitigation, and spectrum resource planning and optimization. Effective, real-time spectrum analysis remains a challenge, stemming from the need to analyse an increasingly complex and dynamic environment with limited resources. The vast amount of data generated from sensing the spectrum at multiple sites requires sophisticated data analysis and processing techniques, which can be technically demanding and expensive. This paper presents a novel, holistic framework developed and deployed at multiple locations across the USA for spectrum analysis and describes the different parts of the end-to-end pipeline. The details of each of the modules of the pipeline, data collection and pre-processing at remote locations, transfer to a centralized location, post-processing analysis, visualization, and long-term storage, are reported. The motivation behind this work is to develop a robust spectrum analysis framework that can help gain greater insights into the spectrum usage across the country and augment additional use cases such as dynamic spectrum sharing.
Muses: Designing, Composing, Generating Nonexistent Fantasy 3D Creatures without Training
Jan 06, 2026We present Muses, the first training-free method for fantastic 3D creature generation in a feed-forward paradigm. Previous methods, which rely on part-aware optimization, manual assembly, or 2D image generation, often produce unrealistic or incoherent 3D assets due to the challenges of intricate part-level manipulation and limited out-of-domain generation. In contrast, Muses leverages the 3D skeleton, a fundamental representation of biological forms, to explicitly and rationally compose diverse elements. This skeletal foundation formalizes 3D content creation as a structure-aware pipeline of design, composition, and generation. Muses begins by constructing a creatively composed 3D skeleton with coherent layout and scale through graph-constrained reasoning. This skeleton then guides a voxel-based assembly process within a structured latent space, integrating regions from different objects. Finally, image-guided appearance modeling under skeletal conditions is applied to generate a style-consistent and harmonious texture for the assembled shape. Extensive experiments establish Muses' state-of-the-art performance in terms of visual fidelity and alignment with textual descriptions, and potential on flexible 3D object editing. Project page: https://luhexiao.github.io/Muses.github.io/.
Towards Natural Language-Based Document Image Retrieval: New Dataset and Benchmark
Dec 23, 2025Document image retrieval (DIR) aims to retrieve document images from a gallery according to a given query. Existing DIR methods are primarily based on image queries that retrieve documents within the same coarse semantic category, e.g., newspapers or receipts. However, these methods struggle to effectively retrieve document images in real-world scenarios where textual queries with fine-grained semantics are usually provided. To bridge this gap, we introduce a new Natural Language-based Document Image Retrieval (NL-DIR) benchmark with corresponding evaluation metrics. In this work, natural language descriptions serve as semantically rich queries for the DIR task. The NL-DIR dataset contains 41K authentic document images, each paired with five high-quality, fine-grained semantic queries generated and evaluated through large language models in conjunction with manual verification. We perform zero-shot and fine-tuning evaluations of existing mainstream contrastive vision-language models and OCR-free visual document understanding (VDU) models. A two-stage retrieval method is further investigated for performance improvement while achieving both time and space efficiency. We hope the proposed NL-DIR benchmark can bring new opportunities and facilitate research for the VDU community. Datasets and codes will be publicly available at huggingface.co/datasets/nianbing/NL-DIR.
BrepLLM: Native Boundary Representation Understanding with Large Language Models
Dec 18, 2025



Current token-sequence-based Large Language Models (LLMs) are not well-suited for directly processing 3D Boundary Representation (Brep) models that contain complex geometric and topological information. We propose BrepLLM, the first framework that enables LLMs to parse and reason over raw Brep data, bridging the modality gap between structured 3D geometry and natural language. BrepLLM employs a two-stage training pipeline: Cross-modal Alignment Pre-training and Multi-stage LLM Fine-tuning. In the first stage, an adaptive UV sampling strategy converts Breps into graphs representation with geometric and topological information. We then design a hierarchical BrepEncoder to extract features from geometry (i.e., faces and edges) and topology, producing both a single global token and a sequence of node tokens. Then we align the global token with text embeddings from a frozen CLIP text encoder (ViT-L/14) via contrastive learning. In the second stage, we integrate the pretrained BrepEncoder into an LLM. We then align its sequence of node tokens using a three-stage progressive training strategy: (1) training an MLP-based semantic mapping from Brep representation to 2D with 2D-LLM priors. (2) performing fine-tuning of the LLM. (3) designing a Mixture-of-Query Experts (MQE) to enhance geometric diversity modeling. We also construct Brep2Text, a dataset comprising 269,444 Brep-text question-answer pairs. Experiments show that BrepLLM achieves state-of-the-art (SOTA) results on 3D object classification and captioning tasks.
Skillful Subseasonal-to-Seasonal Forecasting of Extreme Events with a Multi-Sphere Coupled Probabilistic Model
Dec 14, 2025Accurate subseasonal-to-seasonal (S2S) prediction of extreme events is critical for resource planning and disaster mitigation under accelerating climate change. However, such predictions remain challenging due to complex multi-sphere interactions and intrinsic atmospheric uncertainty. Here we present TianXing-S2S, a multi-sphere coupled probabilistic model for global S2S daily ensemble forecast. TianXing-S2S first encodes diverse multi-sphere predictors into a compact latent space, then employs a diffusion model to generate daily ensemble forecasts. A novel coupling module based on optimal transport (OT) is incorporated in the denoiser to optimize the interactions between atmospheric and multi-sphere boundary conditions. Across key atmospheric variables, TianXing-S2S outperforms both the European Centre for Medium-Range Weather Forecasts (ECMWF) S2S system and FuXi-S2S in 45-day daily-mean ensemble forecasts at 1.5 resolution. Our model achieves skillful subseasonal prediction of extreme events including heat waves and anomalous precipitation, identifying soil moisture as a critical precursor signal. Furthermore, we demonstrate that TianXing-S2S can generate stable rollout forecasts up to 180 days, establishing a robust framework for S2S research in a warming world.
Action is All You Need: Dual-Flow Generative Ranking Network for Recommendation
May 22, 2025We introduce the Dual-Flow Generative Ranking Network (DFGR), a two-stream architecture designed for recommendation systems. DFGR integrates innovative interaction patterns between real and fake flows within the QKV modules of the self-attention mechanism, enhancing both training and inference efficiency. This approach effectively addresses a key limitation observed in Meta's proposed HSTU generative recommendation approach, where heterogeneous information volumes are mapped into identical vector spaces, leading to training instability. Unlike traditional recommendation models, DFGR only relies on user history behavior sequences and minimal attribute information, eliminating the need for extensive manual feature engineering. Comprehensive evaluations on open-source and industrial datasets reveal DFGR's superior performance compared to established baselines such as DIN, DCN, DIEN, and DeepFM. We also investigate optimal parameter allocation strategies under computational constraints, establishing DFGR as an efficient and effective next-generation generate ranking paradigm.
Cross-layer Integrated Sensing and Communication: A Joint Industrial and Academic Perspective
May 16, 2025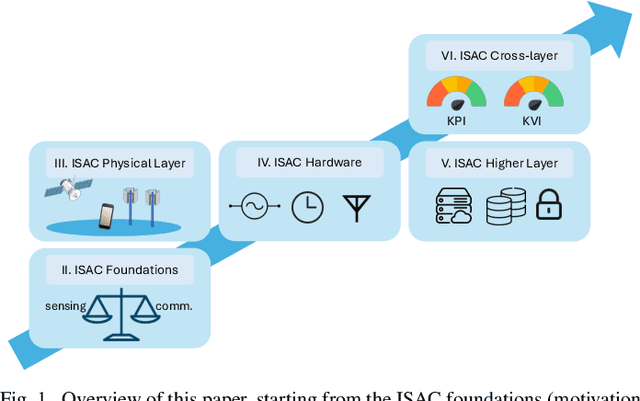



Integrated sensing and communication (ISAC) enables radio systems to simultaneously sense and communicate with their environment. This paper, developed within the Hexa-X-II project funded by the European Union, presents a comprehensive cross-layer vision for ISAC in 6G networks, integrating insights from physical-layer design, hardware architectures, AI-driven intelligence, and protocol-level innovations. We begin by revisiting the foundational principles of ISAC, highlighting synergies and trade-offs between sensing and communication across different integration levels. Enabling technologies, such as multiband operation, massive and distributed MIMO, non-terrestrial networks, reconfigurable intelligent surfaces, and machine learning, are analyzed in conjunction with hardware considerations including waveform design, synchronization, and full-duplex operation. To bridge implementation and system-level evaluation, we introduce a quantitative cross-layer framework linking design parameters to key performance and value indicators. By synthesizing perspectives from both academia and industry, this paper outlines how deeply integrated ISAC can transform 6G into a programmable and context-aware platform supporting applications from reliable wireless access to autonomous mobility and digital twinning.