 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use
Mar 05, 2024From content moderation to wildlife conservation, the number of applications that require models to recognize nuanced or subjective visual concepts is growing. Traditionally, developing classifiers for such concepts requires substantial manual effort measured in hours, days, or even months to identify and annotate data needed for training. Even with recently proposed Agile Modeling techniques, which enable rapid bootstrapping of image classifiers, users are still required to spend 30 minutes or more of monotonous, repetitive data labeling just to train a single classifier. Drawing on Fiske's Cognitive Miser theory, we propose a new framework that alleviates manual effort by replacing human labeling with natural language interactions, reducing the total effort required to define a concept by an order of magnitude: from labeling 2,000 images to only 100 plus some natural language interactions. Our framework leverages recent advances in foundation models, both large language models and vision-language models, to carve out the concept space through conversation and by automatically labeling training data points. Most importantly, our framework eliminates the need for crowd-sourced annotations. Moreover, our framework ultimately produces lightweight classification models that are deployable in cost-sensitive scenarios. Across 15 subjective concepts and across 2 public image classification datasets, our trained models outperform traditional Agile Modeling as well as state-of-the-art zero-shot classification models like ALIGN, CLIP, CuPL, and large visual question-answering models like PaLI-X.
Enhancing Sequential Recommendation with Graph Contrastive Learning
Jun 07, 2022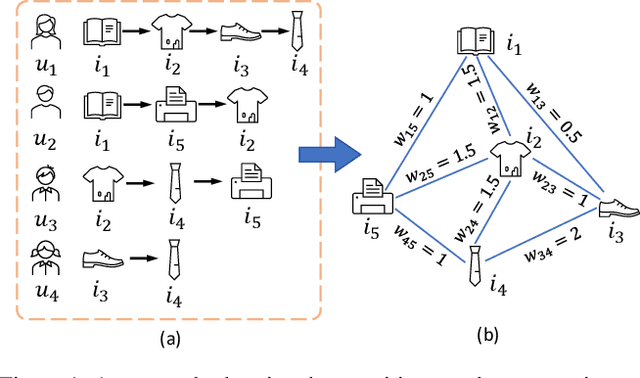
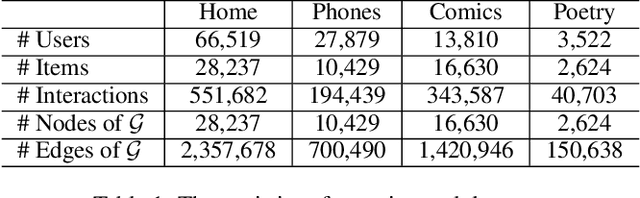
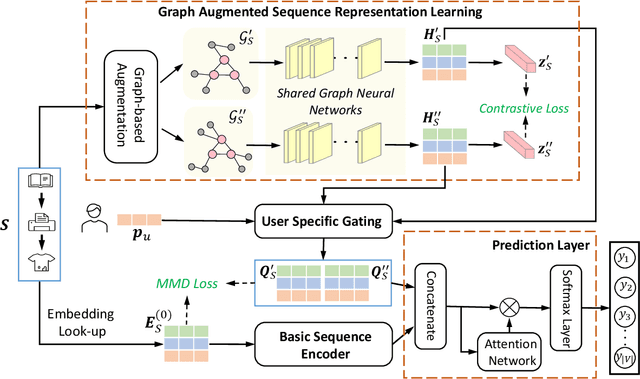
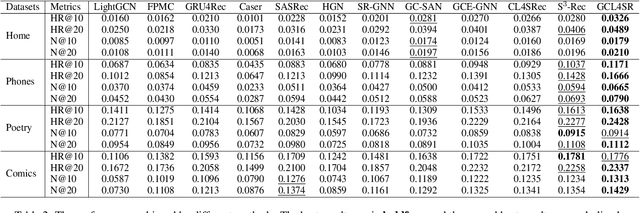
The sequential recommendation systems capture users' dynamic behavior patterns to predict their next interaction behaviors. Most existing sequential recommendation methods only exploit the local context information of an individual interaction sequence and learn model parameters solely based on the item prediction loss. Thus, they usually fail to learn appropriate sequence representations. This paper proposes a novel recommendation framework, namely Graph Contrastive Learning for Sequential Recommendation (GCL4SR). Specifically, GCL4SR employs a Weighted Item Transition Graph (WITG), built based on interaction sequences of all users, to provide global context information for each interaction and weaken the noise information in the sequence data. Moreover, GCL4SR uses subgraphs of WITG to augment the representation of each interaction sequence. Two auxiliary learning objectives have also been proposed to maximize the consistency between augmented representations induced by the same interaction sequence on WITG, and minimize the difference between the representations augmented by the global context on WITG and the local representation of the original sequence. Extensive experiments on real-world datasets demonstrate that GCL4SR consistently outperforms state-of-the-art sequential recommendation methods.
JIZHI: A Fast and Cost-Effective Model-As-A-Service System for Web-Scale Online Inference at Baidu
Jun 03, 2021
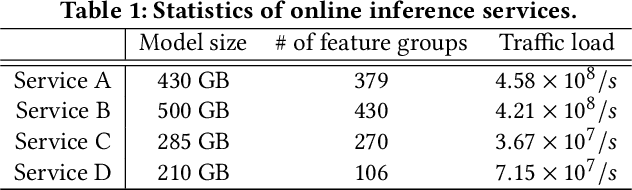
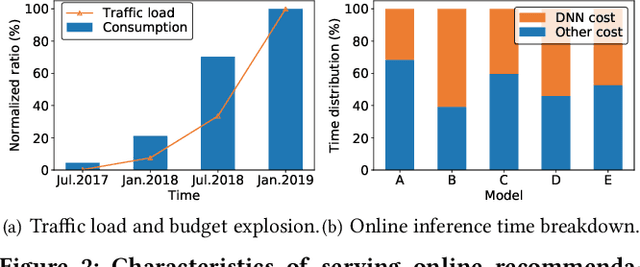
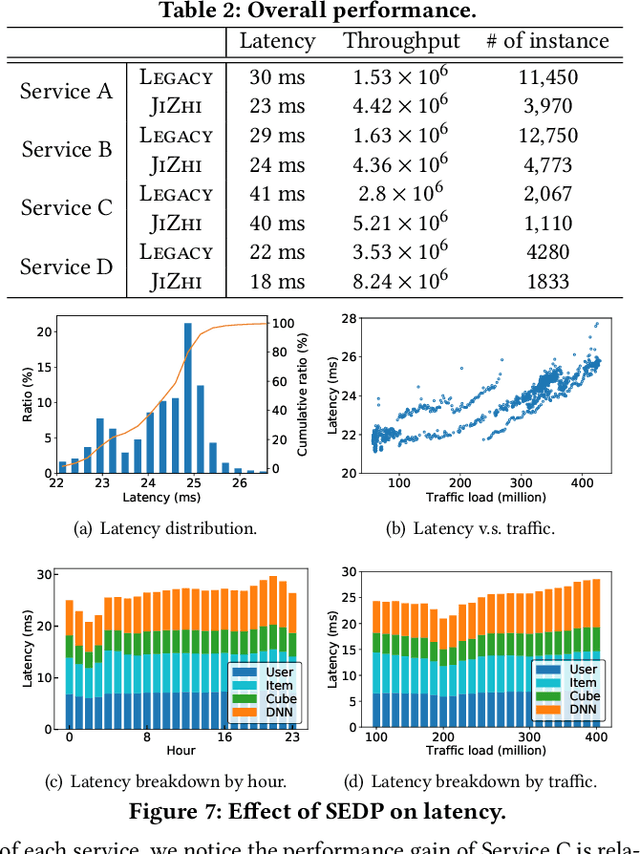
In modern internet industries, deep learning based recommender systems have became an indispensable building block for a wide spectrum of applications, such as search engine, news feed, and short video clips. However, it remains challenging to carry the well-trained deep models for online real-time inference serving, with respect to the time-varying web-scale traffics from billions of users, in a cost-effective manner. In this work, we present JIZHI - a Model-as-a-Service system - that per second handles hundreds of millions of online inference requests to huge deep models with more than trillions of sparse parameters, for over twenty real-time recommendation services at Baidu, Inc. In JIZHI, the inference workflow of every recommendation request is transformed to a Staged Event-Driven Pipeline (SEDP), where each node in the pipeline refers to a staged computation or I/O intensive task processor. With traffics of real-time inference requests arrived, each modularized processor can be run in a fully asynchronized way and managed separately. Besides, JIZHI introduces heterogeneous and hierarchical storage to further accelerate the online inference process by reducing unnecessary computations and potential data access latency induced by ultra-sparse model parameters. Moreover, an intelligent resource manager has been deployed to maximize the throughput of JIZHI over the shared infrastructure by searching the optimal resource allocation plan from historical logs and fine-tuning the load shedding policies over intermediate system feedback. Extensive experiments have been done to demonstrate the advantages of JIZHI from the perspectives of end-to-end service latency, system-wide throughput, and resource consumption. JIZHI has helped Baidu saved more than ten million US dollars in hardware and utility costs while handling 200% more traffics without sacrificing inference efficiency.
Safe Multi-Agent Reinforcement Learning through Decentralized Multiple Control Barrier Functions
Mar 23, 2021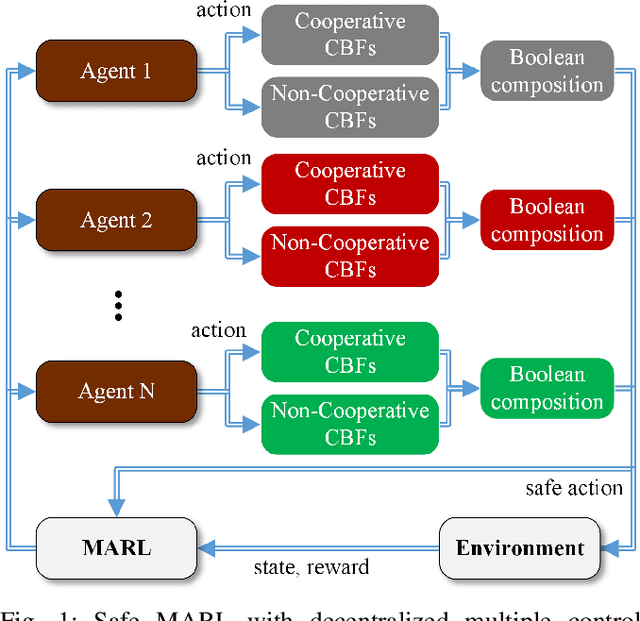
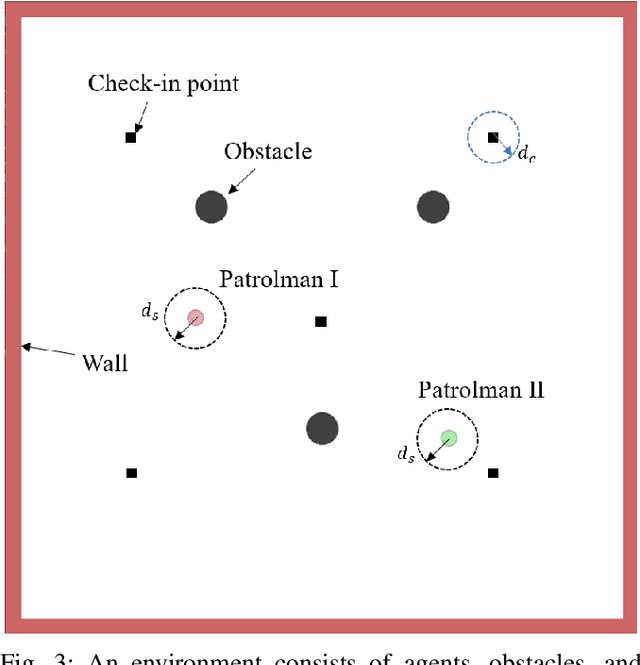
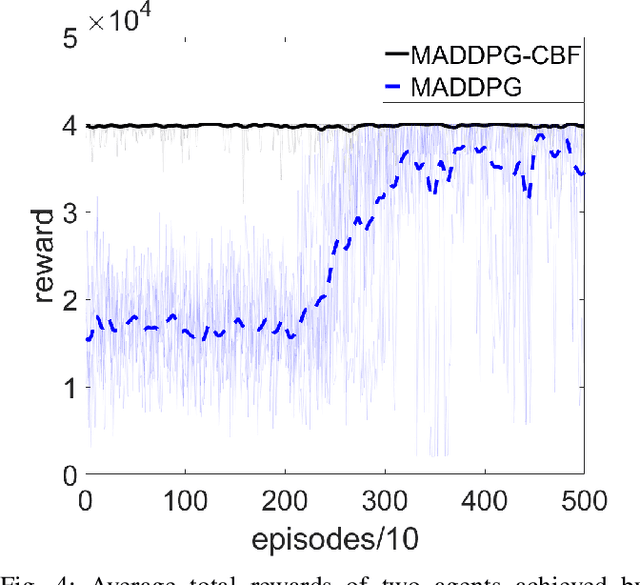
Multi-Agent Reinforcement Learning (MARL) algorithms show amazing performance in simulation in recent years, but placing MARL in real-world applications may suffer safety problems. MARL with centralized shields was proposed and verified in safety games recently. However, centralized shielding approaches can be infeasible in several real-world multi-agent applications that involve non-cooperative agents or communication delay. Thus, we propose to combine MARL with decentralized Control Barrier Function (CBF) shields based on available local information. We establish a safe MARL framework with decentralized multiple CBFs and develop Multi-Agent Deep Deterministic Policy Gradient (MADDPG) to Multi-Agent Deep Deterministic Policy Gradient with decentralized multiple Control Barrier Functions (MADDPG-CBF). Based on a collision-avoidance problem that includes not only cooperative agents but obstacles, we demonstrate the construction of multiple CBFs with safety guarantees in theory. Experiments are conducted and experiment results verify that the proposed safe MARL framework can guarantee the safety of agents included in MARL.
Multi-robot Cooperative Object Transportation using Decentralized Deep Reinforcement Learning
Jul 17, 2020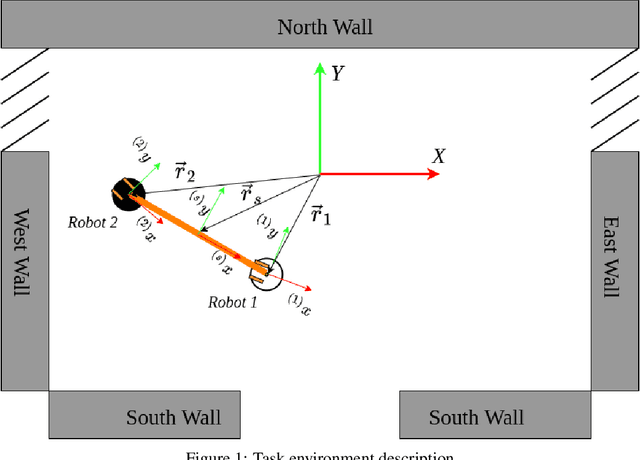
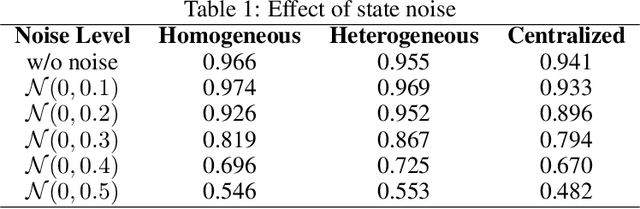
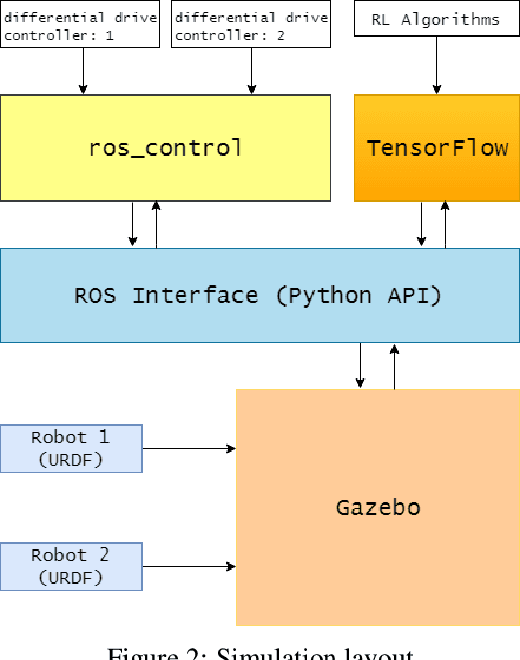
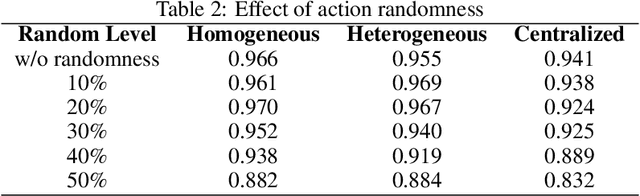
Object transportation could be a challenging problem for a single robot due to the oversize and/or overweight issues. A multi-robot system can take the advantage of increased driving power and more flexible configuration to solve such a problem. However, increased number of individuals also changed the dynamics of the system which makes control of a multi-robot system more complicated. Even worse, if the whole system is sitting on a centralized decision making unit, the data flow could be easily overloaded due to the upscaling of the system. In this research, we propose a decentralized control scheme on a multi-robot system with each individual equipped with a deep Q-network (DQN) controller to perform an oversized object transportation task. DQN is a deep reinforcement learning algorithm thus does not require the knowledge of system dynamics, instead, it enables the robots to learn appropriate control strategies through trial-and-error style interactions within the task environment. Since analogous controllers are distributed on the individuals, the computational bottleneck is avoided systematically. We demonstrate such a system in a scenario of carrying an oversized rod through a doorway by a two-robot team. The presented multi-robot system learns abstract features of the task and cooperative behaviors are observed. The decentralized DQN-style controller is showing strong robustness against uncertainties. In addition, We propose a universal metric to assess the cooperation quantitatively.
Synchronous Speech Recognition and Speech-to-Text Translation with Interactive Decoding
Dec 16, 2019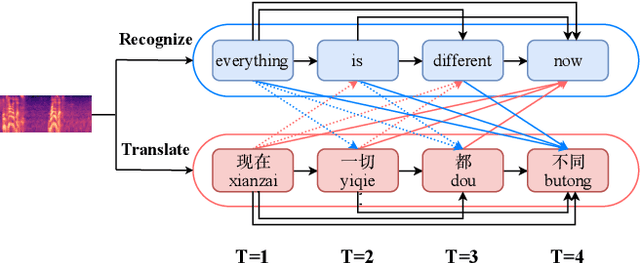
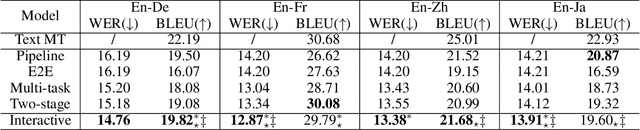
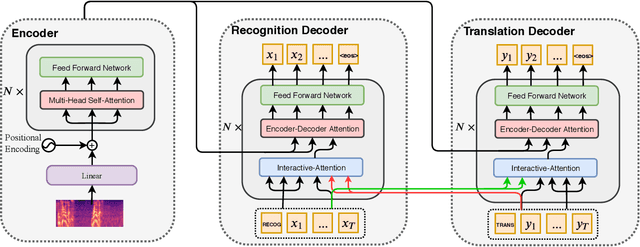
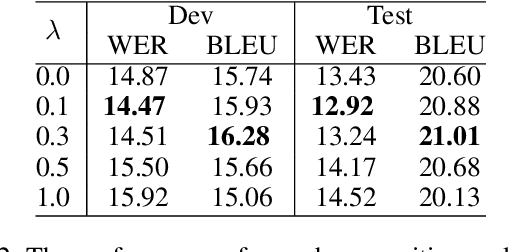
Speech-to-text translation (ST), which translates source language speech into target language text, has attracted intensive attention in recent years. Compared to the traditional pipeline system, the end-to-end ST model has potential benefits of lower latency, smaller model size, and less error propagation. However, it is notoriously difficult to implement such a model without transcriptions as intermediate. Existing works generally apply multi-task learning to improve translation quality by jointly training end-to-end ST along with automatic speech recognition (ASR). However, different tasks in this method cannot utilize information from each other, which limits the improvement. Other works propose a two-stage model where the second model can use the hidden state from the first one, but its cascade manner greatly affects the efficiency of training and inference process. In this paper, we propose a novel interactive attention mechanism which enables ASR and ST to perform synchronously and interactively in a single model. Specifically, the generation of transcriptions and translations not only relies on its previous outputs but also the outputs predicted in the other task. Experiments on TED speech translation corpora have shown that our proposed model can outperform strong baselines on the quality of speech translation and achieve better speech recognition performances as well.
Multi-agent Learning for Neural Machine Translation
Sep 03, 2019
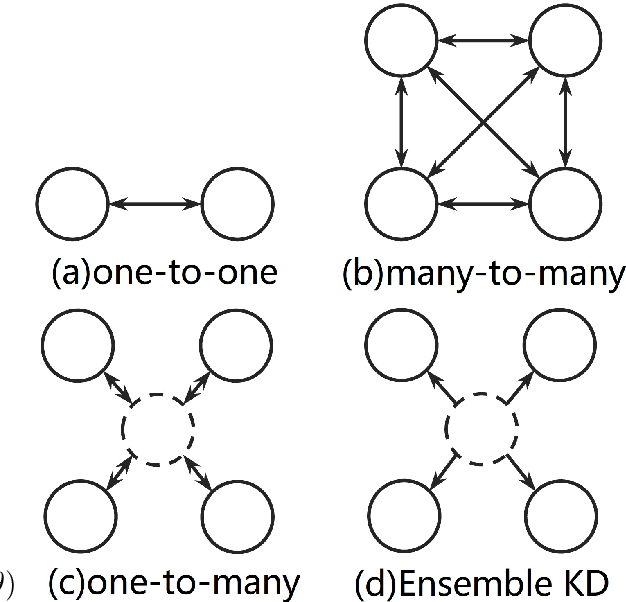
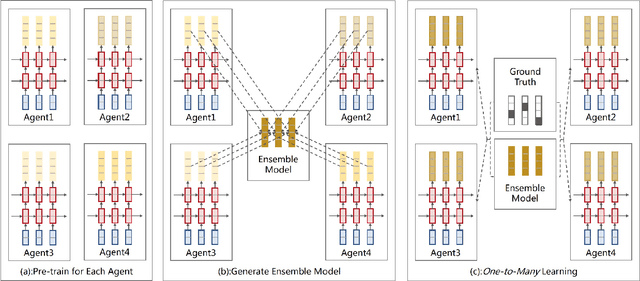
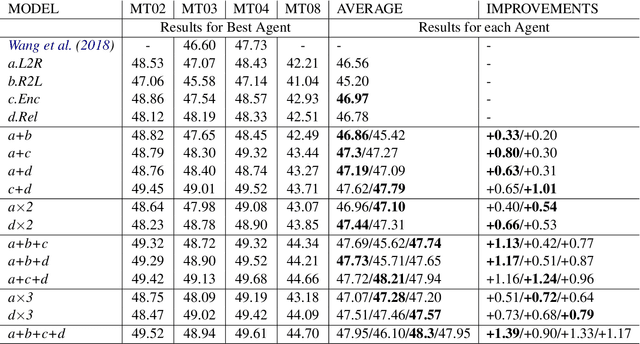
Conventional Neural Machine Translation (NMT) models benefit from the training with an additional agent, e.g., dual learning, and bidirectional decoding with one agent decoding from left to right and the other decoding in the opposite direction. In this paper, we extend the training framework to the multi-agent scenario by introducing diverse agents in an interactive updating process. At training time, each agent learns advanced knowledge from others, and they work together to improve translation quality. Experimental results on NIST Chinese-English, IWSLT 2014 German-English, WMT 2014 English-German and large-scale Chinese-English translation tasks indicate that our approach achieves absolute improvements over the strong baseline systems and shows competitive performance on all tasks.
DuTongChuan: Context-aware Translation Model for Simultaneous Interpreting
Aug 16, 2019


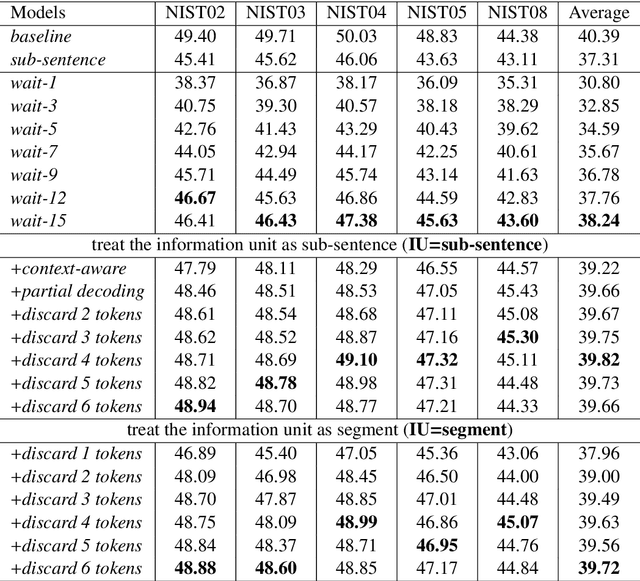
In this paper, we present DuTongChuan, a novel context-aware translation model for simultaneous interpreting. This model allows to constantly read streaming text from the Automatic Speech Recognition (ASR) model and simultaneously determine the boundaries of Information Units (IUs) one after another. The detected IU is then translated into a fluent translation with two simple yet effective decoding strategies: partial decoding and context-aware decoding. In practice, by controlling the granularity of IUs and the size of the context, we can get a good trade-off between latency and translation quality easily. Elaborate evaluation from human translators reveals that our system achieves promising translation quality (85.71% for Chinese-English, and 86.36% for English-Chinese), specially in the sense of surprisingly good discourse coherence. According to an End-to-End (speech-to-speech simultaneous interpreting) evaluation, this model presents impressive performance in reducing latency (to less than 3 seconds at most times). Furthermore, we successfully deploy this model in a variety of Baidu's products which have hundreds of millions of users, and we release it as a service in our AI platform.
End-to-End Speech Translation with Knowledge Distillation
Apr 17, 2019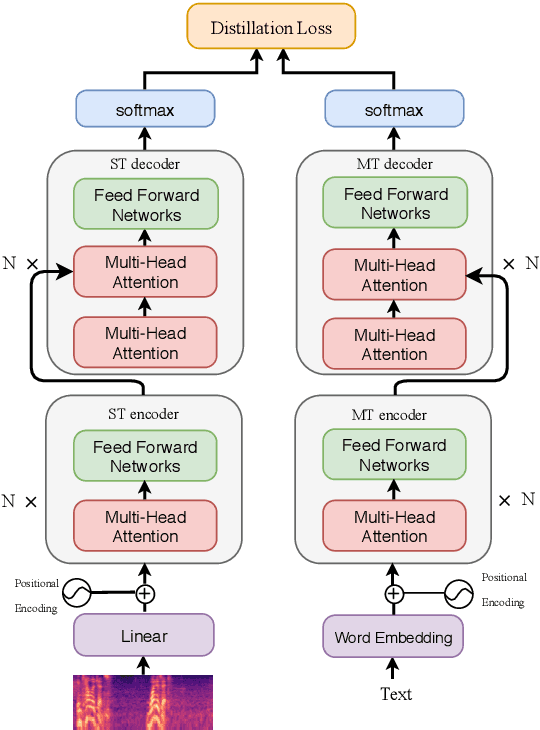
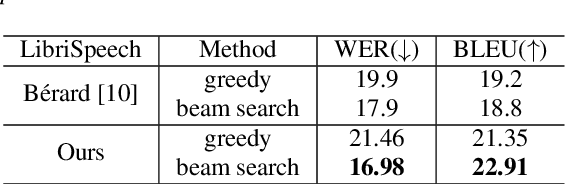
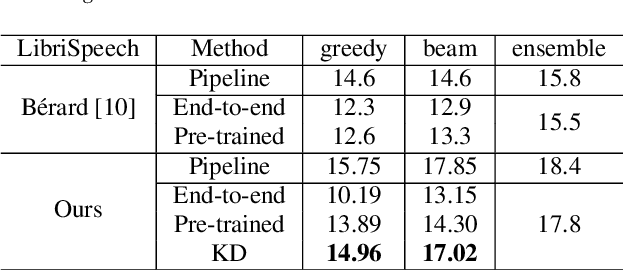
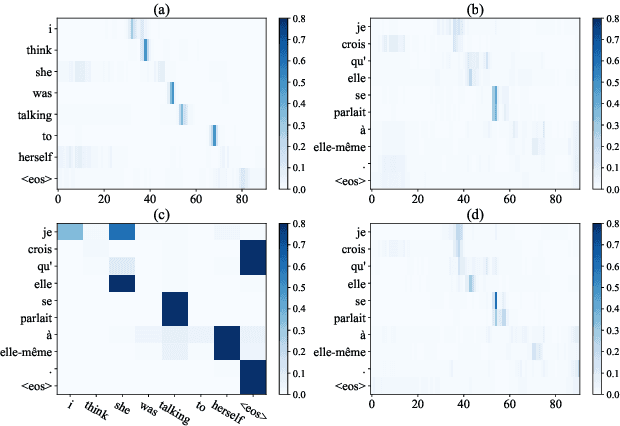
End-to-end speech translation (ST), which directly translates from source language speech into target language text, has attracted intensive attentions in recent years. Compared to conventional pipeline systems, end-to-end ST models have advantages of lower latency, smaller model size and less error propagation. However, the combination of speech recognition and text translation in one model is more difficult than each of these two tasks. In this paper, we propose a knowledge distillation approach to improve ST model by transferring the knowledge from text translation model. Specifically, we first train a text translation model, regarded as a teacher model, and then ST model is trained to learn output probabilities from teacher model through knowledge distillation. Experiments on English- French Augmented LibriSpeech and English-Chinese TED corpus show that end-to-end ST is possible to implement on both similar and dissimilar language pairs. In addition, with the instruction of teacher model, end-to-end ST model can gain significant improvements by over 3.5 BLEU points.
Multiple Sclerosis Lesion Inpainting Using Non-Local Partial Convolutions
Dec 24, 2018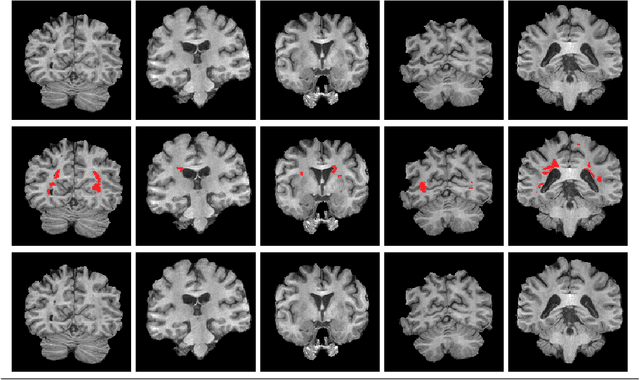
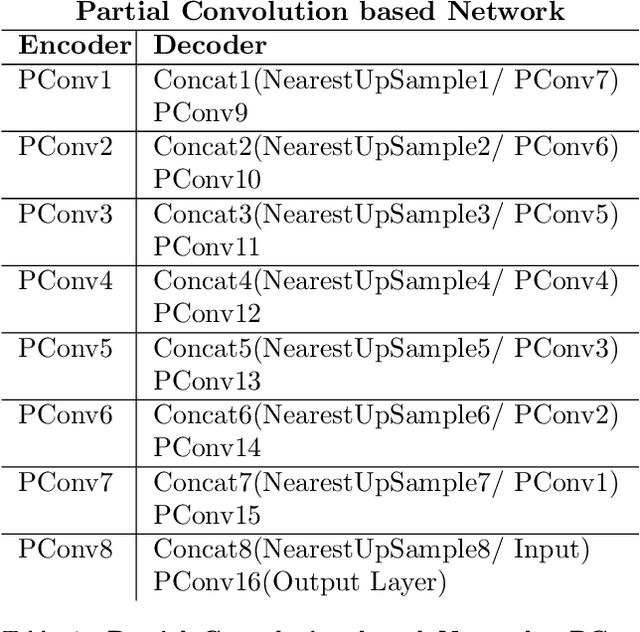
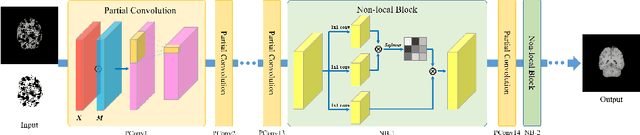
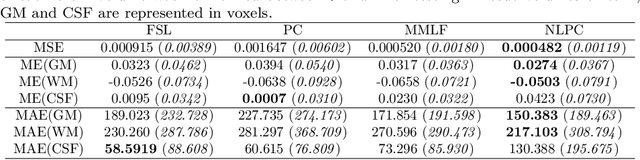
Multiple sclerosis (MS) is an inflammatory demyelinating disease of the central nervous system (CNS) that results in focal injury to the grey and white matter. The presence of white matter lesions biases morphometric analyses such as registration, individual longitudinal measurements and tissue segmentation for brain volume measurements. Lesion-inpainting with intensities derived from surround healthy tissue represent one approach to alleviate such problems. However, existing methods inpaint lesions based on texture information derived from local surrounding tissue, often leading to inconsistent inpainting and the generation of artifacts such as intensity discrepancy and blurriness. Based on these observations, we propose non-local partial convolutions (NLPC) which integrates a Unet-like network with the non-local module. The non-local module is exploited to capture long range dependencies between the lesion area and remaining normal-appearing brain regions. Then, the lesion area is filled by referring to normal-appearing regions with more similar features. This method generates inpainted regions that appear more realistic and natural. Our quantitative experimental results also demonstrate superiority of this technique of existing state-of-the-art inpainting methods.