 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA bio-inspired sand-rolling robot: effect of body shape on sand rolling performance
Mar 18, 2025



The capability of effectively moving on complex terrains such as sand and gravel can empower our robots to robustly operate in outdoor environments, and assist with critical tasks such as environment monitoring, search-and-rescue, and supply delivery. Inspired by the Mount Lyell salamander's ability to curl its body into a loop and effectively roll down {\Revision hill slopes}, in this study we develop a sand-rolling robot and investigate how its locomotion performance is governed by the shape of its body. We experimentally tested three different body shapes: Hexagon, Quadrilateral, and Triangle. We found that Hexagon and Triangle can achieve a faster rolling speed on sand, but exhibited more frequent failures of getting stuck. Analysis of the interaction between robot and sand revealed the failure mechanism: the deformation of the sand produced a local ``sand incline'' underneath robot contact segments, increasing the effective region of supporting polygon (ERSP) and preventing the robot from shifting its center of mass (CoM) outside the ERSP to produce sustainable rolling. Based on this mechanism, a highly-simplified model successfully captured the critical body pitch for each rolling shape to produce sustained rolling on sand, and informed design adaptations that mitigated the locomotion failures and improved robot speed by more than 200$\%$. Our results provide insights into how locomotors can utilize different morphological features to achieve robust rolling motion across deformable substrates.
Adaptive Stochastic Gradient Descents on Manifolds with an Application on Weighted Low-Rank Approximation
Mar 14, 2025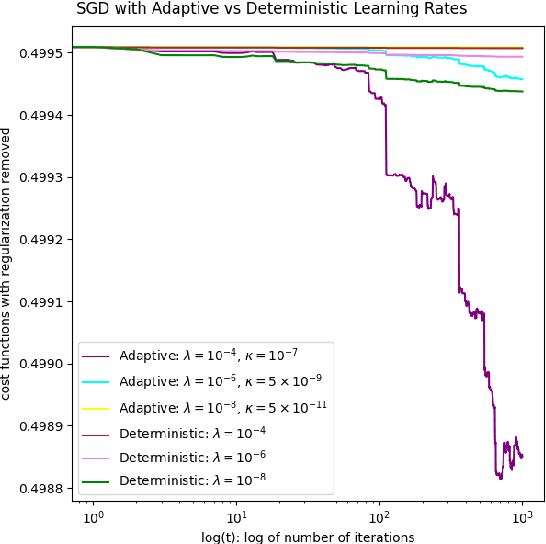
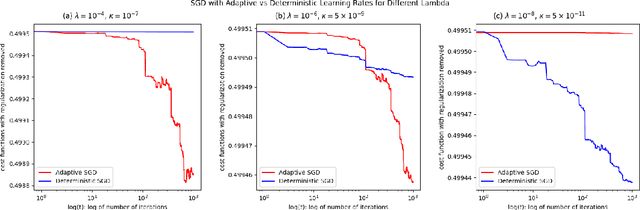
We prove a convergence theorem for stochastic gradient descents on manifolds with adaptive learning rate and apply it to the weighted low-rank approximation problem.
Pushing DSP-Free Coherent Interconnect to the Last Inch by Optically Analog Signal Processing
Mar 14, 2025



To support the boosting interconnect capacity of the AI-related data centers, novel techniques enabled high-speed and low-cost optics are continuously emerging. When the baud rate approaches 200 GBaud per lane, the bottle-neck of traditional intensity modulation direct detection (IM-DD) architectures becomes increasingly evident. The simplified coherent solutions are widely discussed and considered as one of the most promising candidates. In this paper, a novel coherent architecture based on self-homodyne coherent detection and optically analog signal processing (OASP) is demonstrated. Proved by experiment, the first DSP-free baud-rate sampled 64-GBaud QPSK/16-QAM receptions are achieved, with BERs of 1e-6 and 2e-2, respectively. Even with 1-km fiber link propagation, the BER for QPSK reception remains at 3.6e-6. When an ultra-simple 1-sps SISO filter is utilized, the performance degradation of the proposed scheme is less than 1 dB compared to legacy DSP-based coherent reception. The proposed results pave the way for the ultra-high-speed coherent optical interconnections, offering high power and cost efficiency.
Water Quality Data Imputation via A Fast Latent Factorization of Tensors with PID-based Optimizer
Mar 10, 2025Water quality data can supply a substantial decision support for water resources utilization and pollution prevention. However, there are numerous missing values in water quality data due to inescapable factors like sensor failure, thereby leading to biased result for hydrological analysis and failing to support environmental governance decision accurately. A Latent Factorization of Tensors (LFT) with Stochastic Gradient Descent (SGD) proves to be an efficient imputation method. However, a standard SGD-based LFT model commonly surfers from the slow convergence that impairs its efficiency. To tackle this issue, this paper proposes a Fast Latent Factorization of Tensors (FLFT) model. It constructs an adjusted instance error into SGD via leveraging a nonlinear PID controller to incorporates the past, current and future information of prediction error for improving convergence rate. Comparing with state-of-art models in real world datasets, the results of experiment indicate that the FLFT model achieves a better convergence rate and higher accuracy.
SGA-INTERACT: A 3D Skeleton-based Benchmark for Group Activity Understanding in Modern Basketball Tactic
Mar 09, 2025Group Activity Understanding is predominantly studied as Group Activity Recognition (GAR) task. However, existing GAR benchmarks suffer from coarse-grained activity vocabularies and the only data form in single-view, which hinder the evaluation of state-of-the-art algorithms. To address these limitations, we introduce SGA-INTERACT, the first 3D skeleton-based benchmark for group activity understanding. It features complex activities inspired by basketball tactics, emphasizing rich spatial interactions and long-term dependencies. SGA-INTERACT introduces Temporal Group Activity Localization (TGAL) task, extending group activity understanding to untrimmed sequences, filling the gap left by GAR as a standalone task. In addition to the benchmark, we propose One2Many, a novel framework that employs a pretrained 3D skeleton backbone for unified individual feature extraction. This framework aligns with the feature extraction paradigm in RGB-based methods, enabling direct evaluation of RGB-based models on skeleton-based benchmarks. We conduct extensive evaluations on SGA-INTERACT using two skeleton-based methods, three RGB-based methods, and a proposed baseline within the One2Many framework. The general low performance of baselines highlights the benchmark's challenges, motivating advancements in group activity understanding.
StreamMind: Unlocking Full Frame Rate Streaming Video Dialogue through Event-Gated Cognition
Mar 08, 2025



With the rise of real-world human-AI interaction applications, such as AI assistants, the need for Streaming Video Dialogue is critical. To address this need, we introduce \sys, a video LLM framework that achieves ultra-FPS streaming video processing (100 fps on a single A100) and enables proactive, always-on responses in real time, without explicit user intervention. To solve the key challenge of the contradiction between linear video streaming speed and quadratic transformer computation cost, we propose a novel perception-cognition interleaving paradigm named ''event-gated LLM invocation'', in contrast to the existing per-time-step LLM invocation. By introducing a Cognition Gate network between the video encoder and the LLM, LLM is only invoked when relevant events occur. To realize the event feature extraction with constant cost, we propose Event-Preserving Feature Extractor (EPFE) based on state-space method, generating a single perception token for spatiotemporal features. These techniques enable the video LLM with full-FPS perception and real-time cognition response. Experiments on Ego4D and SoccerNet streaming tasks, as well as standard offline benchmarks, demonstrate state-of-the-art performance in both model capability and real-time efficiency, paving the way for ultra-high-FPS applications, such as Game AI Copilot and interactive media.
SpecServe: Efficient and SLO-Aware Large Language Model Serving with Adaptive Speculative Decoding
Mar 07, 2025Large Language Model (LLM) services often face challenges in achieving low inference latency and meeting Service Level Objectives (SLOs) under dynamic request patterns. Speculative decoding, which exploits lightweight models for drafting and LLMs for verification, has emerged as a compelling technique to accelerate LLM inference. However, existing speculative decoding solutions often fail to adapt to varying workloads and system environments, resulting in performance variability and SLO violations. In this paper, we introduce SpecServe, an efficient LLM inference system that dynamically adjusts speculative strategies according to real-time request loads and system configurations. SpecServe proposes a theoretical model to understand and predict the efficiency of speculative decoding across diverse scenarios. Additionally, it implements intelligent drafting and verification algorithms to guarantee optimal performance while achieving high SLO attainment. Experimental results on real-world LLM traces demonstrate that SpecServe consistently meets SLOs and achieves substantial performance improvements, yielding 1.14$\times$-14.3$\times$ speedups over state-of-the-art speculative inference systems.
Learning-Augmented Frequent Directions
Mar 02, 2025



An influential paper of Hsu et al. (ICLR'19) introduced the study of learning-augmented streaming algorithms in the context of frequency estimation. A fundamental problem in the streaming literature, the goal of frequency estimation is to approximate the number of occurrences of items appearing in a long stream of data using only a small amount of memory. Hsu et al. develop a natural framework to combine the worst-case guarantees of popular solutions such as CountMin and CountSketch with learned predictions of high frequency elements. They demonstrate that learning the underlying structure of data can be used to yield better streaming algorithms, both in theory and practice. We simplify and generalize past work on learning-augmented frequency estimation. Our first contribution is a learning-augmented variant of the Misra-Gries algorithm which improves upon the error of learned CountMin and learned CountSketch and achieves the state-of-the-art performance of randomized algorithms (Aamand et al., NeurIPS'23) with a simpler, deterministic algorithm. Our second contribution is to adapt learning-augmentation to a high-dimensional generalization of frequency estimation corresponding to finding important directions (top singular vectors) of a matrix given its rows one-by-one in a stream. We analyze a learning-augmented variant of the Frequent Directions algorithm, extending the theoretical and empirical understanding of learned predictions to matrix streaming.
BeamVQ: Beam Search with Vector Quantization to Mitigate Data Scarcity in Physical Spatiotemporal Forecasting
Feb 26, 2025



In practice, physical spatiotemporal forecasting can suffer from data scarcity, because collecting large-scale data is non-trivial, especially for extreme events. Hence, we propose \method{}, a novel probabilistic framework to realize iterative self-training with new self-ensemble strategies, achieving better physical consistency and generalization on extreme events. Following any base forecasting model, we can encode its deterministic outputs into a latent space and retrieve multiple codebook entries to generate probabilistic outputs. Then BeamVQ extends the beam search from discrete spaces to the continuous state spaces in this field. We can further employ domain-specific metrics (e.g., Critical Success Index for extreme events) to filter out the top-k candidates and develop the new self-ensemble strategy by combining the high-quality candidates. The self-ensemble can not only improve the inference quality and robustness but also iteratively augment the training datasets during continuous self-training. Consequently, BeamVQ realizes the exploration of rare but critical phenomena beyond the original dataset. Comprehensive experiments on different benchmarks and backbones show that BeamVQ consistently reduces forecasting MSE (up to 39%), enhancing extreme events detection and proving its effectiveness in handling data scarcity.
SCA3D: Enhancing Cross-modal 3D Retrieval via 3D Shape and Caption Paired Data Augmentation
Feb 26, 2025The cross-modal 3D retrieval task aims to achieve mutual matching between text descriptions and 3D shapes. This has the potential to enhance the interaction between natural language and the 3D environment, especially within the realms of robotics and embodied artificial intelligence (AI) applications. However, the scarcity and expensiveness of 3D data constrain the performance of existing cross-modal 3D retrieval methods. These methods heavily rely on features derived from the limited number of 3D shapes, resulting in poor generalization ability across diverse scenarios. To address this challenge, we introduce SCA3D, a novel 3D shape and caption online data augmentation method for cross-modal 3D retrieval. Our approach uses the LLaVA model to create a component library, captioning each segmented part of every 3D shape within the dataset. Notably, it facilitates the generation of extensive new 3D-text pairs containing new semantic features. We employ both inter and intra distances to align various components into a new 3D shape, ensuring that the components do not overlap and are closely fitted. Further, text templates are utilized to process the captions of each component and generate new text descriptions. Besides, we use unimodal encoders to extract embeddings for 3D shapes and texts based on the enriched dataset. We then calculate fine-grained cross-modal similarity using Earth Mover's Distance (EMD) and enhance cross-modal matching with contrastive learning, enabling bidirectional retrieval between texts and 3D shapes. Extensive experiments show our SCA3D outperforms previous works on the Text2Shape dataset, raising the Shape-to-Text RR@1 score from 20.03 to 27.22 and the Text-to-Shape RR@1 score from 13.12 to 16.67. Codes can be found in https://github.com/3DAgentWorld/SCA3D.