 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Approximations for Hard Graph Problems using Predictions
May 29, 2025

We design improved approximation algorithms for NP-hard graph problems by incorporating predictions (e.g., learned from past data). Our prediction model builds upon and extends the $\varepsilon$-prediction framework by Cohen-Addad, d'Orsi, Gupta, Lee, and Panigrahi (NeurIPS 2024). We consider an edge-based version of this model, where each edge provides two bits of information, corresponding to predictions about whether each of its endpoints belong to an optimal solution. Even with weak predictions where each bit is only $\varepsilon$-correlated with the true solution, this information allows us to break approximation barriers in the standard setting. We develop algorithms with improved approximation ratios for MaxCut, Vertex Cover, Set Cover, and Maximum Independent Set problems (among others). Across these problems, our algorithms share a unifying theme, where we separately satisfy constraints related to high degree vertices (using predictions) and low-degree vertices (without using predictions) and carefully combine the answers.
WTEFNet: Real-Time Low-Light Object Detection for Advanced Driver-Assistance Systems
May 29, 2025Object detection is a cornerstone of environmental perception in advanced driver assistance systems(ADAS). However, most existing methods rely on RGB cameras, which suffer from significant performance degradation under low-light conditions due to poor image quality. To address this challenge, we proposes WTEFNet, a real-time object detection framework specifically designed for low-light scenarios, with strong adaptability to mainstream detectors. WTEFNet comprises three core modules: a Low-Light Enhancement (LLE) module, a Wavelet-based Feature Extraction (WFE) module, and an Adaptive Fusion Detection (AFFD) module. The LLE enhances dark regions while suppressing overexposed areas; the WFE applies multi-level discrete wavelet transforms to isolate high- and low-frequency components, enabling effective denoising and structural feature retention; the AFFD fuses semantic and illumination features for robust detection. To support training and evaluation, we introduce GSN, a manually annotated dataset covering both clear and rainy night-time scenes. Extensive experiments on BDD100K, SHIFT, nuScenes, and GSN demonstrate that WTEFNet achieves state-of-the-art accuracy under low-light conditions. Furthermore, deployment on a embedded platform (NVIDIA Jetson AGX Orin) confirms the framework's suitability for real-time ADAS applications.
Say What You Mean: Natural Language Access Control with Large Language Models for Internet of Things
May 28, 2025



Access control in the Internet of Things (IoT) is becoming increasingly complex, as policies must account for dynamic and contextual factors such as time, location, user behavior, and environmental conditions. However, existing platforms either offer only coarse-grained controls or rely on rigid rule matching, making them ill-suited for semantically rich or ambiguous access scenarios. Moreover, the policy authoring process remains fragmented: domain experts describe requirements in natural language, but developers must manually translate them into code, introducing semantic gaps and potential misconfiguration. In this work, we present LACE, the Language-based Access Control Engine, a hybrid framework that leverages large language models (LLMs) to bridge the gap between human intent and machine-enforceable logic. LACE combines prompt-guided policy generation, retrieval-augmented reasoning, and formal validation to support expressive, interpretable, and verifiable access control. It enables users to specify policies in natural language, automatically translates them into structured rules, validates semantic correctness, and makes access decisions using a hybrid LLM-rule-based engine. We evaluate LACE in smart home environments through extensive experiments. LACE achieves 100% correctness in verified policy generation and up to 88% decision accuracy with 0.79 F1-score using DeepSeek-V3, outperforming baselines such as GPT-3.5 and Gemini. The system also demonstrates strong scalability under increasing policy volume and request concurrency. Our results highlight LACE's potential to enable secure, flexible, and user-friendly access control across real-world IoT platforms.
Xinyu AI Search: Enhanced Relevance and Comprehensive Results with Rich Answer Presentations
May 28, 2025Traditional search engines struggle to synthesize fragmented information for complex queries, while generative AI search engines face challenges in relevance, comprehensiveness, and presentation. To address these limitations, we introduce Xinyu AI Search, a novel system that incorporates a query-decomposition graph to dynamically break down complex queries into sub-queries, enabling stepwise retrieval and generation. Our retrieval pipeline enhances diversity through multi-source aggregation and query expansion, while filtering and re-ranking strategies optimize passage relevance. Additionally, Xinyu AI Search introduces a novel approach for fine-grained, precise built-in citation and innovates in result presentation by integrating timeline visualization and textual-visual choreography. Evaluated on recent real-world queries, Xinyu AI Search outperforms eight existing technologies in human assessments, excelling in relevance, comprehensiveness, and insightfulness. Ablation studies validate the necessity of its key sub-modules. Our work presents the first comprehensive framework for generative AI search engines, bridging retrieval, generation, and user-centric presentation.
NeuralOM: Neural Ocean Model for Subseasonal-to-Seasonal Simulation
May 27, 2025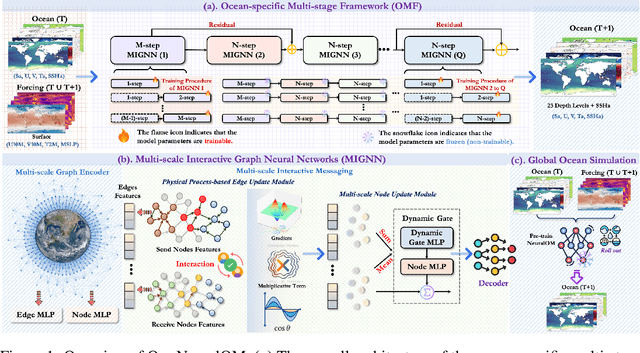
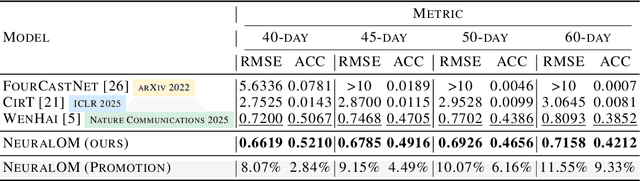
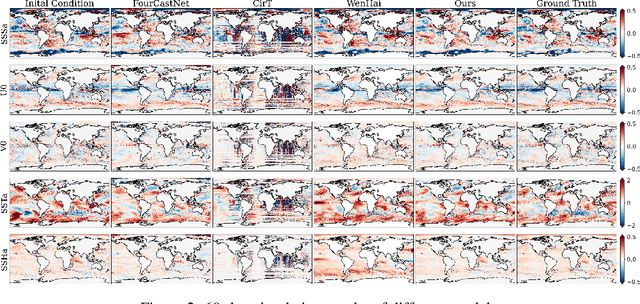
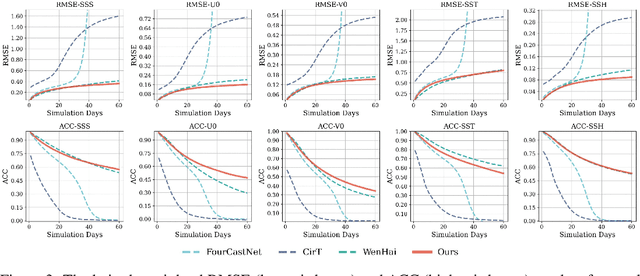
Accurate Subseasonal-to-Seasonal (S2S) ocean simulation is critically important for marine research, yet remains challenging due to its substantial thermal inertia and extended time delay. Machine learning (ML)-based models have demonstrated significant advancements in simulation accuracy and computational efficiency compared to traditional numerical methods. Nevertheless, a significant limitation of current ML models for S2S ocean simulation is their inadequate incorporation of physical consistency and the slow-changing properties of the ocean system. In this work, we propose a neural ocean model (NeuralOM) for S2S ocean simulation with a multi-scale interactive graph neural network to emulate diverse physical phenomena associated with ocean systems effectively. Specifically, we propose a multi-stage framework tailored to model the ocean's slowly changing nature. Additionally, we introduce a multi-scale interactive messaging module to capture complex dynamical behaviors, such as gradient changes and multiplicative coupling relationships inherent in ocean dynamics. Extensive experimental evaluations confirm that our proposed NeuralOM outperforms state-of-the-art models in S2S and extreme event simulation. The codes are available at https://github.com/YuanGao-YG/NeuralOM.
Advanced long-term earth system forecasting by learning the small-scale nature
May 26, 2025Reliable long-term forecast of Earth system dynamics is heavily hampered by instabilities in current AI models during extended autoregressive simulations. These failures often originate from inherent spectral bias, leading to inadequate representation of critical high-frequency, small-scale processes and subsequent uncontrolled error amplification. We present Triton, an AI framework designed to address this fundamental challenge. Inspired by increasing grids to explicitly resolve small scales in numerical models, Triton employs a hierarchical architecture processing information across multiple resolutions to mitigate spectral bias and explicitly model cross-scale dynamics. We demonstrate Triton's superior performance on challenging forecast tasks, achieving stable year-long global temperature forecasts, skillful Kuroshio eddy predictions till 120 days, and high-fidelity turbulence simulations preserving fine-scale structures all without external forcing, with significantly surpassing baseline AI models in long-term stability and accuracy. By effectively suppressing high-frequency error accumulation, Triton offers a promising pathway towards trustworthy AI-driven simulation for climate and earth system science.
Turb-L1: Achieving Long-term Turbulence Tracing By Tackling Spectral Bias
May 25, 2025



Accurately predicting the long-term evolution of turbulence is crucial for advancing scientific understanding and optimizing engineering applications. However, existing deep learning methods face significant bottlenecks in long-term autoregressive prediction, which exhibit excessive smoothing and fail to accurately track complex fluid dynamics. Our extensive experimental and spectral analysis of prevailing methods provides an interpretable explanation for this shortcoming, identifying Spectral Bias as the core obstacle. Concretely, spectral bias is the inherent tendency of models to favor low-frequency, smooth features while overlooking critical high-frequency details during training, thus reducing fidelity and causing physical distortions in long-term predictions. Building on this insight, we propose Turb-L1, an innovative turbulence prediction method, which utilizes a Hierarchical Dynamics Synthesis mechanism within a multi-grid architecture to explicitly overcome spectral bias. It accurately captures cross-scale interactions and preserves the fidelity of high-frequency dynamics, enabling reliable long-term tracking of turbulence evolution. Extensive experiments on the 2D turbulence benchmark show that Turb-L1 demonstrates excellent performance: (I) In long-term predictions, it reduces Mean Squared Error (MSE) by $80.3\%$ and increases Structural Similarity (SSIM) by over $9\times$ compared to the SOTA baseline, significantly improving prediction fidelity. (II) It effectively overcomes spectral bias, accurately reproducing the full enstrophy spectrum and maintaining physical realism in high-wavenumber regions, thus avoiding the spectral distortions or spurious energy accumulation seen in other methods.
Unlocking Smarter Device Control: Foresighted Planning with a World Model-Driven Code Execution Approach
May 22, 2025The automatic control of mobile devices is essential for efficiently performing complex tasks that involve multiple sequential steps. However, these tasks pose significant challenges due to the limited environmental information available at each step, primarily through visual observations. As a result, current approaches, which typically rely on reactive policies, focus solely on immediate observations and often lead to suboptimal decision-making. To address this problem, we propose \textbf{Foresighted Planning with World Model-Driven Code Execution (FPWC)},a framework that prioritizes natural language understanding and structured reasoning to enhance the agent's global understanding of the environment by developing a task-oriented, refinable \emph{world model} at the outset of the task. Foresighted actions are subsequently generated through iterative planning within this world model, executed in the form of executable code. Extensive experiments conducted in simulated environments and on real mobile devices demonstrate that our method outperforms previous approaches, particularly achieving a 44.4\% relative improvement in task success rate compared to the state-of-the-art in the simulated environment. Code and demo are provided in the supplementary material.
InSpire: Vision-Language-Action Models with Intrinsic Spatial Reasoning
May 20, 2025Leveraging pretrained Vision-Language Models (VLMs) to map language instruction and visual observations to raw low-level actions, Vision-Language-Action models (VLAs) hold great promise for achieving general-purpose robotic systems. Despite their advancements, existing VLAs tend to spuriously correlate task-irrelevant visual features with actions, limiting their generalization capacity beyond the training data. To tackle this challenge, we propose Intrinsic Spatial Reasoning (InSpire), a simple yet effective approach that mitigates the adverse effects of spurious correlations by boosting the spatial reasoning ability of VLAs. Specifically, InSpire redirects the VLA's attention to task-relevant factors by prepending the question "In which direction is the [object] relative to the robot?" to the language instruction and aligning the answer "right/left/up/down/front/back/grasped" and predicted actions with the ground-truth. Notably, InSpire can be used as a plugin to enhance existing autoregressive VLAs, requiring no extra training data or interaction with other large models. Extensive experimental results in both simulation and real-world environments demonstrate the effectiveness and flexibility of our approach. Our code, pretrained models and demos are publicly available at: https://Koorye.github.io/proj/Inspire.
CellVerse: Do Large Language Models Really Understand Cell Biology?
May 09, 2025



Recent studies have demonstrated the feasibility of modeling single-cell data as natural languages and the potential of leveraging powerful large language models (LLMs) for understanding cell biology. However, a comprehensive evaluation of LLMs' performance on language-driven single-cell analysis tasks still remains unexplored. Motivated by this challenge, we introduce CellVerse, a unified language-centric question-answering benchmark that integrates four types of single-cell multi-omics data and encompasses three hierarchical levels of single-cell analysis tasks: cell type annotation (cell-level), drug response prediction (drug-level), and perturbation analysis (gene-level). Going beyond this, we systematically evaluate the performance across 14 open-source and closed-source LLMs ranging from 160M to 671B on CellVerse. Remarkably, the experimental results reveal: (1) Existing specialist models (C2S-Pythia) fail to make reasonable decisions across all sub-tasks within CellVerse, while generalist models such as Qwen, Llama, GPT, and DeepSeek family models exhibit preliminary understanding capabilities within the realm of cell biology. (2) The performance of current LLMs falls short of expectations and has substantial room for improvement. Notably, in the widely studied drug response prediction task, none of the evaluated LLMs demonstrate significant performance improvement over random guessing. CellVerse offers the first large-scale empirical demonstration that significant challenges still remain in applying LLMs to cell biology. By introducing CellVerse, we lay the foundation for advancing cell biology through natural languages and hope this paradigm could facilitate next-generation single-cell analysis.