 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Free 3D Quantitative Phase Imaging of Flowing Cellular Populations
Sep 05, 2025High-throughput 3D quantitative phase imaging (QPI) in flow cytometry enables label-free, volumetric characterization of individual cells by reconstructing their refractive index (RI) distributions from multiple viewing angles during flow through microfluidic channels. However, current imaging methods assume that cells undergo uniform, single-axis rotation, which require their poses to be known at each frame. This assumption restricts applicability to near-spherical cells and prevents accurate imaging of irregularly shaped cells with complex rotations. As a result, only a subset of the cellular population can be analyzed, limiting the ability of flow-based assays to perform robust statistical analysis. We introduce OmniFHT, a pose-free 3D RI reconstruction framework that leverages the Fourier diffraction theorem and implicit neural representations (INRs) for high-throughput flow cytometry tomographic imaging. By jointly optimizing each cell's unknown rotational trajectory and volumetric structure under weak scattering assumptions, OmniFHT supports arbitrary cell geometries and multi-axis rotations. Its continuous representation also allows accurate reconstruction from sparsely sampled projections and restricted angular coverage, producing high-fidelity results with as few as 10 views or only 120 degrees of angular range. OmniFHT enables, for the first time, in situ, high-throughput tomographic imaging of entire flowing cell populations, providing a scalable and unbiased solution for label-free morphometric analysis in flow cytometry platforms.
SelfAug: Mitigating Catastrophic Forgetting in Retrieval-Augmented Generation via Distribution Self-Alignment
Sep 04, 2025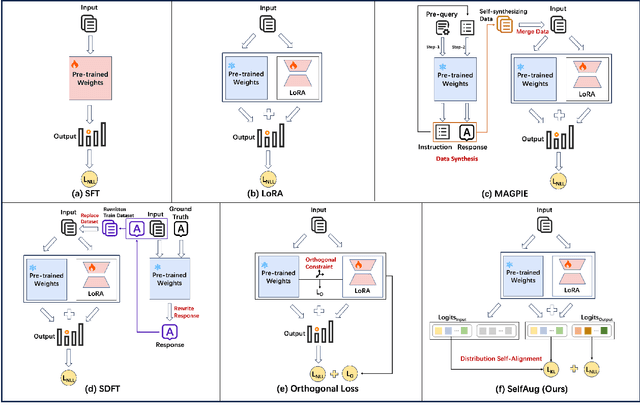
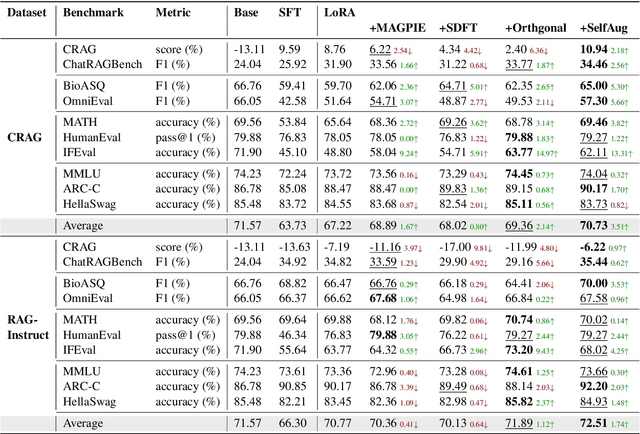
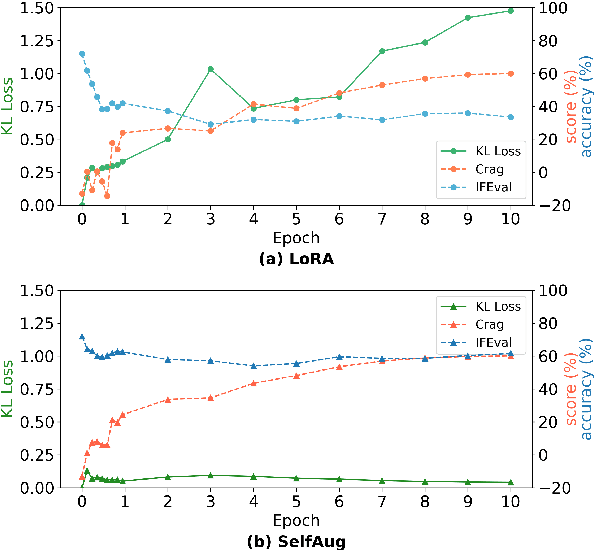
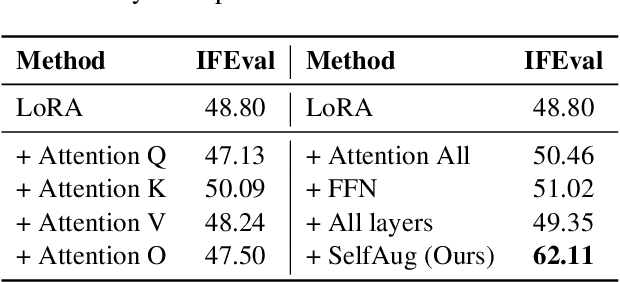
Recent advancements in large language models (LLMs) have revolutionized natural language processing through their remarkable capabilities in understanding and executing diverse tasks. While supervised fine-tuning, particularly in Retrieval-Augmented Generation (RAG) scenarios, effectively enhances task-specific performance, it often leads to catastrophic forgetting, where models lose their previously acquired knowledge and general capabilities. Existing solutions either require access to general instruction data or face limitations in preserving the model's original distribution. To overcome these limitations, we propose SelfAug, a self-distribution alignment method that aligns input sequence logits to preserve the model's semantic distribution, thereby mitigating catastrophic forgetting and improving downstream performance. Extensive experiments demonstrate that SelfAug achieves a superior balance between downstream learning and general capability retention. Our comprehensive empirical analysis reveals a direct correlation between distribution shifts and the severity of catastrophic forgetting in RAG scenarios, highlighting how the absence of RAG capabilities in general instruction tuning leads to significant distribution shifts during fine-tuning. Our findings not only advance the understanding of catastrophic forgetting in RAG contexts but also provide a practical solution applicable across diverse fine-tuning scenarios. Our code is publicly available at https://github.com/USTC-StarTeam/SelfAug.
EvolveSignal: A Large Language Model Powered Coding Agent for Discovering Traffic Signal Control Algorithms
Sep 04, 2025In traffic engineering, the fixed-time traffic signal control remains widely used for its low cost, stability, and interpretability. However, its design depends on hand-crafted formulas (e.g., Webster) and manual re-timing by engineers to adapt to demand changes, which is labor-intensive and often yields suboptimal results under heterogeneous or congested conditions. This paper introduces the EvolveSignal, a large language models (LLMs) powered coding agent to automatically discover new traffic signal control algorithms. We formulate the problem as program synthesis, where candidate algorithms are represented as Python functions with fixed input-output structures, and iteratively optimized through external evaluations (e.g., a traffic simulator) and evolutionary search. Experiments on a signalized intersection demonstrate that the discovered algorithms outperform Webster's baseline, reducing average delay by 20.1% and average stops by 47.1%. Beyond performance, ablation and incremental analyses reveal that EvolveSignal modifications-such as adjusting cycle length bounds, incorporating right-turn demand, and rescaling green allocations-can offer practically meaningful insights for traffic engineers. This work opens a new research direction by leveraging AI for algorithm design in traffic signal control, bridging program synthesis with transportation engineering.
SAT: Supervisor Regularization and Animation Augmentation for Two-process Monocular Texture 3D Human Reconstruction
Aug 27, 2025



Monocular texture 3D human reconstruction aims to create a complete 3D digital avatar from just a single front-view human RGB image. However, the geometric ambiguity inherent in a single 2D image and the scarcity of 3D human training data are the main obstacles limiting progress in this field. To address these issues, current methods employ prior geometric estimation networks to derive various human geometric forms, such as the SMPL model and normal maps. However, they struggle to integrate these modalities effectively, leading to view inconsistencies, such as facial distortions. To this end, we propose a two-process 3D human reconstruction framework, SAT, which seamlessly learns various prior geometries in a unified manner and reconstructs high-quality textured 3D avatars as the final output. To further facilitate geometry learning, we introduce a Supervisor Feature Regularization module. By employing a multi-view network with the same structure to provide intermediate features as training supervision, these varied geometric priors can be better fused. To tackle data scarcity and further improve reconstruction quality, we also propose an Online Animation Augmentation module. By building a one-feed-forward animation network, we augment a massive number of samples from the original 3D human data online for model training. Extensive experiments on two benchmarks show the superiority of our approach compared to state-of-the-art methods.
VistaWise: Building Cost-Effective Agent with Cross-Modal Knowledge Graph for Minecraft
Aug 26, 2025Large language models (LLMs) have shown significant promise in embodied decision-making tasks within virtual open-world environments. Nonetheless, their performance is hindered by the absence of domain-specific knowledge. Methods that finetune on large-scale domain-specific data entail prohibitive development costs. This paper introduces VistaWise, a cost-effective agent framework that integrates cross-modal domain knowledge and finetunes a dedicated object detection model for visual analysis. It reduces the requirement for domain-specific training data from millions of samples to a few hundred. VistaWise integrates visual information and textual dependencies into a cross-modal knowledge graph (KG), enabling a comprehensive and accurate understanding of multimodal environments. We also equip the agent with a retrieval-based pooling strategy to extract task-related information from the KG, and a desktop-level skill library to support direct operation of the Minecraft desktop client via mouse and keyboard inputs. Experimental results demonstrate that VistaWise achieves state-of-the-art performance across various open-world tasks, highlighting its effectiveness in reducing development costs while enhancing agent performance.
CausalMACE: Causality Empowered Multi-Agents in Minecraft Cooperative Tasks
Aug 26, 2025Minecraft, as an open-world virtual interactive environment, has become a prominent platform for research on agent decision-making and execution. Existing works primarily adopt a single Large Language Model (LLM) agent to complete various in-game tasks. However, for complex tasks requiring lengthy sequences of actions, single-agent approaches often face challenges related to inefficiency and limited fault tolerance. Despite these issues, research on multi-agent collaboration remains scarce. In this paper, we propose CausalMACE, a holistic causality planning framework designed to enhance multi-agent systems, in which we incorporate causality to manage dependencies among subtasks. Technically, our proposed framework introduces two modules: an overarching task graph for global task planning and a causality-based module for dependency management, where inherent rules are adopted to perform causal intervention. Experimental results demonstrate our approach achieves state-of-the-art performance in multi-agent cooperative tasks of Minecraft.
D$^2$-LIO: Enhanced Optimization for LiDAR-IMU Odometry Considering Directional Degeneracy
Aug 20, 2025



LiDAR-inertial odometry (LIO) plays a vital role in achieving accurate localization and mapping, especially in complex environments. However, the presence of LiDAR feature degeneracy poses a major challenge to reliable state estimation. To overcome this issue, we propose an enhanced LIO framework that integrates adaptive outlier-tolerant correspondence with a scan-to-submap registration strategy. The core contribution lies in an adaptive outlier removal threshold, which dynamically adjusts based on point-to-sensor distance and the motion amplitude of platform. This mechanism improves the robustness of feature matching in varying conditions. Moreover, we introduce a flexible scan-to-submap registration method that leverages IMU data to refine pose estimation, particularly in degenerate geometric configurations. To further enhance localization accuracy, we design a novel weighting matrix that fuses IMU preintegration covariance with a degeneration metric derived from the scan-to-submap process. Extensive experiments conducted in both indoor and outdoor environments-characterized by sparse or degenerate features-demonstrate that our method consistently outperforms state-of-the-art approaches in terms of both robustness and accuracy.
Pruning and Malicious Injection: A Retraining-Free Backdoor Attack on Transformer Models
Aug 14, 2025Transformer models have demonstrated exceptional performance and have become indispensable in computer vision (CV) and natural language processing (NLP) tasks. However, recent studies reveal that transformers are susceptible to backdoor attacks. Prior backdoor attack methods typically rely on retraining with clean data or altering the model architecture, both of which can be resource-intensive and intrusive. In this paper, we propose Head-wise Pruning and Malicious Injection (HPMI), a novel retraining-free backdoor attack on transformers that does not alter the model's architecture. Our approach requires only a small subset of the original data and basic knowledge of the model architecture, eliminating the need for retraining the target transformer. Technically, HPMI works by pruning the least important head and injecting a pre-trained malicious head to establish the backdoor. We provide a rigorous theoretical justification demonstrating that the implanted backdoor resists detection and removal by state-of-the-art defense techniques, under reasonable assumptions. Experimental evaluations across multiple datasets further validate the effectiveness of HPMI, showing that it 1) incurs negligible clean accuracy loss, 2) achieves at least 99.55% attack success rate, and 3) bypasses four advanced defense mechanisms. Additionally, relative to state-of-the-art retraining-dependent attacks, HPMI achieves greater concealment and robustness against diverse defense strategies, while maintaining minimal impact on clean accuracy.
AtomDiffuser: Time-Aware Degradation Modeling for Drift and Beam Damage in STEM Imaging
Aug 14, 2025Scanning transmission electron microscopy (STEM) plays a critical role in modern materials science, enabling direct imaging of atomic structures and their evolution under external interferences. However, interpreting time-resolved STEM data remains challenging due to two entangled degradation effects: spatial drift caused by mechanical and thermal instabilities, and beam-induced signal loss resulting from radiation damage. These factors distort both geometry and intensity in complex, temporally correlated ways, making it difficult for existing methods to explicitly separate their effects or model material dynamics at atomic resolution. In this work, we present AtomDiffuser, a time-aware degradation modeling framework that disentangles sample drift and radiometric attenuation by predicting an affine transformation and a spatially varying decay map between any two STEM frames. Unlike traditional denoising or registration pipelines, our method leverages degradation as a physically heuristic, temporally conditioned process, enabling interpretable structural evolutions across time. Trained on synthetic degradation processes, AtomDiffuser also generalizes well to real-world cryo-STEM data. It further supports high-resolution degradation inference and drift alignment, offering tools for visualizing and quantifying degradation patterns that correlate with radiation-induced atomic instabilities.
Interpreting Fedspeak with Confidence: A LLM-Based Uncertainty-Aware Framework Guided by Monetary Policy Transmission Paths
Aug 12, 2025"Fedspeak", the stylized and often nuanced language used by the U.S. Federal Reserve, encodes implicit policy signals and strategic stances. The Federal Open Market Committee strategically employs Fedspeak as a communication tool to shape market expectations and influence both domestic and global economic conditions. As such, automatically parsing and interpreting Fedspeak presents a high-impact challenge, with significant implications for financial forecasting, algorithmic trading, and data-driven policy analysis. In this paper, we propose an LLM-based, uncertainty-aware framework for deciphering Fedspeak and classifying its underlying monetary policy stance. Technically, to enrich the semantic and contextual representation of Fedspeak texts, we incorporate domain-specific reasoning grounded in the monetary policy transmission mechanism. We further introduce a dynamic uncertainty decoding module to assess the confidence of model predictions, thereby enhancing both classification accuracy and model reliability. Experimental results demonstrate that our framework achieves state-of-the-art performance on the policy stance analysis task. Moreover, statistical analysis reveals a significant positive correlation between perceptual uncertainty and model error rates, validating the effectiveness of perceptual uncertainty as a diagnostic signal.