 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVD$^2$: Efficient Multiview 3D Reconstruction for Multiview Diffusion
Feb 22, 2024



As a promising 3D generation technique, multiview diffusion (MVD) has received a lot of attention due to its advantages in terms of generalizability, quality, and efficiency. By finetuning pretrained large image diffusion models with 3D data, the MVD methods first generate multiple views of a 3D object based on an image or text prompt and then reconstruct 3D shapes with multiview 3D reconstruction. However, the sparse views and inconsistent details in the generated images make 3D reconstruction challenging. We present MVD$^2$, an efficient 3D reconstruction method for multiview diffusion (MVD) images. MVD$^2$ aggregates image features into a 3D feature volume by projection and convolution and then decodes volumetric features into a 3D mesh. We train MVD$^2$ with 3D shape collections and MVD images prompted by rendered views of 3D shapes. To address the discrepancy between the generated multiview images and ground-truth views of the 3D shapes, we design a simple-yet-efficient view-dependent training scheme. MVD$^2$ improves the 3D generation quality of MVD and is fast and robust to various MVD methods. After training, it can efficiently decode 3D meshes from multiview images within one second. We train MVD$^2$ with Zero-123++ and ObjectVerse-LVIS 3D dataset and demonstrate its superior performance in generating 3D models from multiview images generated by different MVD methods, using both synthetic and real images as prompts.
Mastering the Game of Guandan with Deep Reinforcement Learning and Behavior Regulating
Feb 21, 2024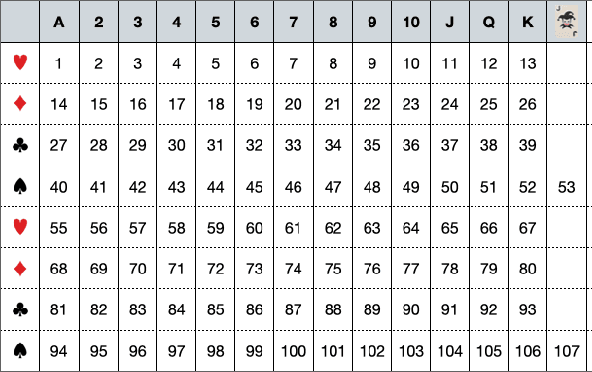
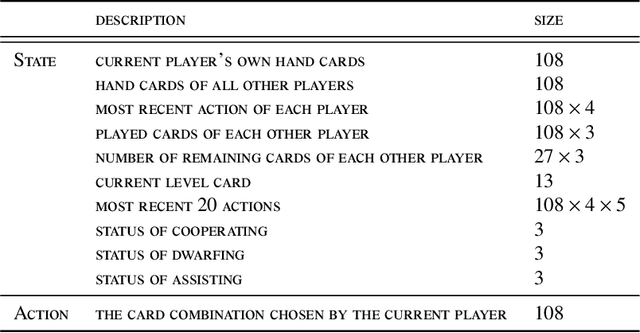
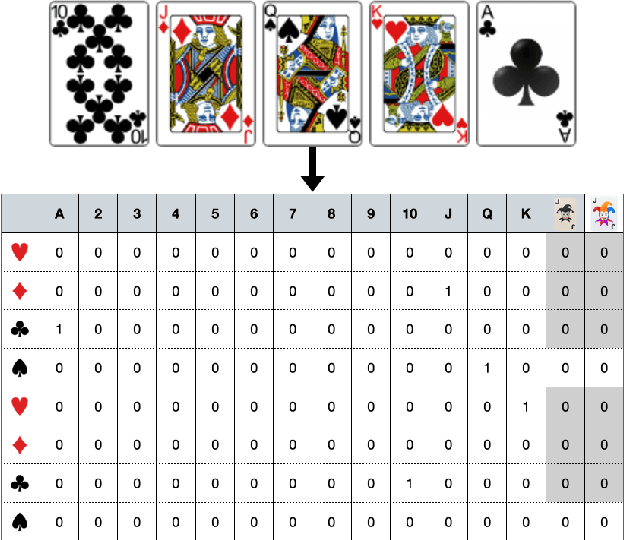

Games are a simplified model of reality and often serve as a favored platform for Artificial Intelligence (AI) research. Much of the research is concerned with game-playing agents and their decision making processes. The game of Guandan (literally, "throwing eggs") is a challenging game where even professional human players struggle to make the right decision at times. In this paper we propose a framework named GuanZero for AI agents to master this game using Monte-Carlo methods and deep neural networks. The main contribution of this paper is about regulating agents' behavior through a carefully designed neural network encoding scheme. We then demonstrate the effectiveness of the proposed framework by comparing it with state-of-the-art approaches.
StructRe: Rewriting for Structured Shape Modeling
Nov 30, 2023



Man-made 3D shapes are naturally organized in parts and hierarchies; such structures provide important constraints for shape reconstruction and generation. Modeling shape structures is difficult, because there can be multiple hierarchies for a given shape, causing ambiguity, and across different categories the shape structures are correlated with semantics, limiting generalization. We present StructRe, a structure rewriting system, as a novel approach to structured shape modeling. Given a 3D object represented by points and components, StructRe can rewrite it upward into more concise structures, or downward into more detailed structures; by iterating the rewriting process, hierarchies are obtained. Such a localized rewriting process enables probabilistic modeling of ambiguous structures and robust generalization across object categories. We train StructRe on PartNet data and show its generalization to cross-category and multiple object hierarchies, and test its extension to ShapeNet. We also demonstrate the benefits of probabilistic and generalizable structure modeling for shape reconstruction, generation and editing tasks.
CADTalk: An Algorithm and Benchmark for Semantic Commenting of CAD Programs
Nov 30, 2023



CAD programs are a popular way to compactly encode shapes as a sequence of operations that are easy to parametrically modify. However, without sufficient semantic comments and structure, such programs can be challenging to understand, let alone modify. We introduce the problem of semantic commenting CAD programs, wherein the goal is to segment the input program into code blocks corresponding to semantically meaningful shape parts and assign a semantic label to each block. We solve the problem by combining program parsing with visual-semantic analysis afforded by recent advances in foundational language and vision models. Specifically, by executing the input programs, we create shapes, which we use to generate conditional photorealistic images to make use of semantic annotators for such images. We then distill the information across the images and link back to the original programs to semantically comment on them. Additionally, we collected and annotated a benchmark dataset, CADTalk, consisting of 5,280 machine-made programs and 45 human-made programs with ground truth semantic comments to foster future research. We extensively evaluated our approach, compared to a GPT-based baseline approach, and an open-set shape segmentation baseline, i.e., PartSLIP, and reported an 83.24% accuracy on the new CADTalk dataset. Project page: https://enigma-li.github.io/CADTalk/.
Generative Hierarchical Temporal Transformer for Hand Action Recognition and Motion Prediction
Nov 29, 2023



We present a novel framework that concurrently tackles hand action recognition and 3D future hand motion prediction. While previous works focus on either recognition or prediction, we propose a generative Transformer VAE architecture to jointly capture both aspects, facilitating realistic motion prediction by leveraging the short-term hand motion and long-term action consistency observed across timestamps.To ensure faithful representation of the semantic dependency and different temporal granularity of hand pose and action, our framework is decomposed into two cascaded VAE blocks. The lower pose block models short-span poses, while the upper action block models long-span action. These are connected by a mid-level feature that represents sub-second series of hand poses.Our framework is trained across multiple datasets, where pose and action blocks are trained separately to fully utilize pose-action annotations of different qualities. Evaluations show that on multiple datasets, the joint modeling of recognition and prediction improves over separate solutions, and the semantic and temporal hierarchy enables long-term pose and action modeling.
iPUNet:Iterative Cross Field Guided Point Cloud Upsampling
Oct 13, 2023Point clouds acquired by 3D scanning devices are often sparse, noisy, and non-uniform, causing a loss of geometric features. To facilitate the usability of point clouds in downstream applications, given such input, we present a learning-based point upsampling method, i.e., iPUNet, which generates dense and uniform points at arbitrary ratios and better captures sharp features. To generate feature-aware points, we introduce cross fields that are aligned to sharp geometric features by self-supervision to guide point generation. Given cross field defined frames, we enable arbitrary ratio upsampling by learning at each input point a local parameterized surface. The learned surface consumes the neighboring points and 2D tangent plane coordinates as input, and maps onto a continuous surface in 3D where arbitrary ratios of output points can be sampled. To solve the non-uniformity of input points, on top of the cross field guided upsampling, we further introduce an iterative strategy that refines the point distribution by moving sparse points onto the desired continuous 3D surface in each iteration. Within only a few iterations, the sparse points are evenly distributed and their corresponding dense samples are more uniform and better capture geometric features. Through extensive evaluations on diverse scans of objects and scenes, we demonstrate that iPUNet is robust to handle noisy and non-uniformly distributed inputs, and outperforms state-of-the-art point cloud upsampling methods.
Large Language Models Empowered Autonomous Edge AI for Connected Intelligence
Jul 06, 2023



The evolution of wireless networks gravitates towards connected intelligence, a concept that envisions seamless interconnectivity among humans, objects, and intelligence in a hyper-connected cyber-physical world. Edge AI emerges as a promising solution to achieve connected intelligence by delivering high-quality, low-latency, and privacy-preserving AI services at the network edge. In this article, we introduce an autonomous edge AI system that automatically organizes, adapts, and optimizes itself to meet users' diverse requirements. The system employs a cloud-edge-client hierarchical architecture, where the large language model, i.e., Generative Pretrained Transformer (GPT), resides in the cloud, and other AI models are co-deployed on devices and edge servers. By leveraging the powerful abilities of GPT in language understanding, planning, and code generation, we present a versatile framework that efficiently coordinates edge AI models to cater to users' personal demands while automatically generating code to train new models via edge federated learning. Experimental results demonstrate the system's remarkable ability to accurately comprehend user demands, efficiently execute AI models with minimal cost, and effectively create high-performance AI models through federated learning.
Locally Attentional SDF Diffusion for Controllable 3D Shape Generation
May 09, 2023Although the recent rapid evolution of 3D generative neural networks greatly improves 3D shape generation, it is still not convenient for ordinary users to create 3D shapes and control the local geometry of generated shapes. To address these challenges, we propose a diffusion-based 3D generation framework -- locally attentional SDF diffusion, to model plausible 3D shapes, via 2D sketch image input. Our method is built on a two-stage diffusion model. The first stage, named occupancy-diffusion, aims to generate a low-resolution occupancy field to approximate the shape shell. The second stage, named SDF-diffusion, synthesizes a high-resolution signed distance field within the occupied voxels determined by the first stage to extract fine geometry. Our model is empowered by a novel view-aware local attention mechanism for image-conditioned shape generation, which takes advantage of 2D image patch features to guide 3D voxel feature learning, greatly improving local controllability and model generalizability. Through extensive experiments in sketch-conditioned and category-conditioned 3D shape generation tasks, we validate and demonstrate the ability of our method to provide plausible and diverse 3D shapes, as well as its superior controllability and generalizability over existing work. Our code and trained models are available at https://zhengxinyang.github.io/projects/LAS-Diffusion.html
* Accepted to SIGGRAPH 2023 (Journal version)
Swin3D: A Pretrained Transformer Backbone for 3D Indoor Scene Understanding
Apr 24, 2023Pretrained backbones with fine-tuning have been widely adopted in 2D vision and natural language processing tasks and demonstrated significant advantages to task-specific networks. In this paper, we present a pretrained 3D backbone, named Swin3D, which first outperforms all state-of-the-art methods in downstream 3D indoor scene understanding tasks. Our backbone network is based on a 3D Swin transformer and carefully designed to efficiently conduct self-attention on sparse voxels with linear memory complexity and capture the irregularity of point signals via generalized contextual relative positional embedding. Based on this backbone design, we pretrained a large Swin3D model on a synthetic Structured3D dataset that is 10 times larger than the ScanNet dataset and fine-tuned the pretrained model in various downstream real-world indoor scene understanding tasks. The results demonstrate that our model pretrained on the synthetic dataset not only exhibits good generality in both downstream segmentation and detection on real 3D point datasets, but also surpasses the state-of-the-art methods on downstream tasks after fine-tuning with +2.3 mIoU and +2.2 mIoU on S3DIS Area5 and 6-fold semantic segmentation, +2.1 mIoU on ScanNet segmentation (val), +1.9 mAP@0.5 on ScanNet detection, +8.1 mAP@0.5 on S3DIS detection. Our method demonstrates the great potential of pretrained 3D backbones with fine-tuning for 3D understanding tasks. The code and models are available at https://github.com/microsoft/Swin3D .
3D Feature Prediction for Masked-AutoEncoder-Based Point Cloud Pretraining
Apr 14, 2023



Masked autoencoders (MAE) have recently been introduced to 3D self-supervised pretraining for point clouds due to their great success in NLP and computer vision. Unlike MAEs used in the image domain, where the pretext task is to restore features at the masked pixels, such as colors, the existing 3D MAE works reconstruct the missing geometry only, i.e, the location of the masked points. In contrast to previous studies, we advocate that point location recovery is inessential and restoring intrinsic point features is much superior. To this end, we propose to ignore point position reconstruction and recover high-order features at masked points including surface normals and surface variations, through a novel attention-based decoder which is independent of the encoder design. We validate the effectiveness of our pretext task and decoder design using different encoder structures for 3D training and demonstrate the advantages of our pretrained networks on various point cloud analysis tasks.