 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model
Feb 26, 2026SkyReels V4 is a unified multi modal video foundation model for joint video audio generation, inpainting, and editing. The model adopts a dual stream Multimodal Diffusion Transformer (MMDiT) architecture, where one branch synthesizes video and the other generates temporally aligned audio, while sharing a powerful text encoder based on the Multimodal Large Language Models (MMLM). SkyReels V4 accepts rich multi modal instructions, including text, images, video clips, masks, and audio references. By combining the MMLMs multi modal instruction following capability with in context learning in the video branch MMDiT, the model can inject fine grained visual guidance under complex conditioning, while the audio branch MMDiT simultaneously leverages audio references to guide sound generation. On the video side, we adopt a channel concatenation formulation that unifies a wide range of inpainting style tasks, such as image to video, video extension, and video editing under a single interface, and naturally extends to vision referenced inpainting and editing via multi modal prompts. SkyReels V4 supports up to 1080p resolution, 32 FPS, and 15 second duration, enabling high fidelity, multi shot, cinema level video generation with synchronized audio. To make such high resolution, long-duration generation computationally feasible, we introduce an efficiency strategy: Joint generation of low resolution full sequences and high-resolution keyframes, followed by dedicated super-resolution and frame interpolation models. To our knowledge, SkyReels V4 is the first video foundation model that simultaneously supports multi-modal input, joint video audio generation, and a unified treatment of generation, inpainting, and editing, while maintaining strong efficiency and quality at cinematic resolutions and durations.
ComplexGen: CAD Reconstruction by B-Rep Chain Complex Generation
May 29, 2022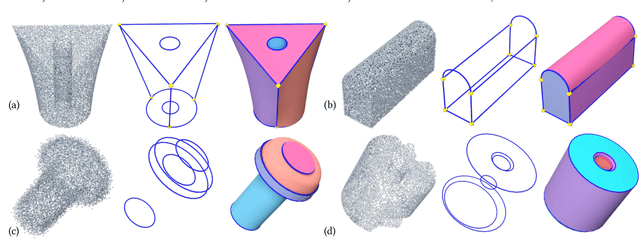

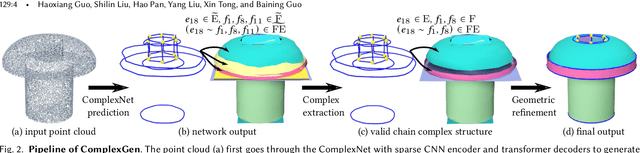

We view the reconstruction of CAD models in the boundary representation (B-Rep) as the detection of geometric primitives of different orders, i.e. vertices, edges and surface patches, and the correspondence of primitives, which are holistically modeled as a chain complex, and show that by modeling such comprehensive structures more complete and regularized reconstructions can be achieved. We solve the complex generation problem in two steps. First, we propose a novel neural framework that consists of a sparse CNN encoder for input point cloud processing and a tri-path transformer decoder for generating geometric primitives and their mutual relationships with estimated probabilities. Second, given the probabilistic structure predicted by the neural network, we recover a definite B-Rep chain complex by solving a global optimization maximizing the likelihood under structural validness constraints and applying geometric refinements. Extensive tests on large scale CAD datasets demonstrate that the modeling of B-Rep chain complex structure enables more accurate detection for learning and more constrained reconstruction for optimization, leading to structurally more faithful and complete CAD B-Rep models than previous results.