 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidBot: Learning Generalizable 3D Actions from In-the-Wild 2D Human Videos for Zero-Shot Robotic Manipulation
Mar 10, 2025



Future robots are envisioned as versatile systems capable of performing a variety of household tasks. The big question remains, how can we bridge the embodiment gap while minimizing physical robot learning, which fundamentally does not scale well. We argue that learning from in-the-wild human videos offers a promising solution for robotic manipulation tasks, as vast amounts of relevant data already exist on the internet. In this work, we present VidBot, a framework enabling zero-shot robotic manipulation using learned 3D affordance from in-the-wild monocular RGB-only human videos. VidBot leverages a pipeline to extract explicit representations from them, namely 3D hand trajectories from videos, combining a depth foundation model with structure-from-motion techniques to reconstruct temporally consistent, metric-scale 3D affordance representations agnostic to embodiments. We introduce a coarse-to-fine affordance learning model that first identifies coarse actions from the pixel space and then generates fine-grained interaction trajectories with a diffusion model, conditioned on coarse actions and guided by test-time constraints for context-aware interaction planning, enabling substantial generalization to novel scenes and embodiments. Extensive experiments demonstrate the efficacy of VidBot, which significantly outperforms counterparts across 13 manipulation tasks in zero-shot settings and can be seamlessly deployed across robot systems in real-world environments. VidBot paves the way for leveraging everyday human videos to make robot learning more scalable.
FrontierNet: Learning Visual Cues to Explore
Jan 08, 2025



Exploration of unknown environments is crucial for autonomous robots; it allows them to actively reason and decide on what new data to acquire for tasks such as mapping, object discovery, and environmental assessment. Existing methods, such as frontier-based methods, rely heavily on 3D map operations, which are limited by map quality and often overlook valuable context from visual cues. This work aims at leveraging 2D visual cues for efficient autonomous exploration, addressing the limitations of extracting goal poses from a 3D map. We propose a image-only frontier-based exploration system, with FrontierNet as a core component developed in this work. FrontierNet is a learning-based model that (i) detects frontiers, and (ii) predicts their information gain, from posed RGB images enhanced by monocular depth priors. Our approach provides an alternative to existing 3D-dependent exploration systems, achieving a 16% improvement in early-stage exploration efficiency, as validated through extensive simulations and real-world experiments.
An overview of domain-specific foundation model: key technologies, applications and challenges
Sep 06, 2024The impressive performance of ChatGPT and other foundation-model-based products in human language understanding has prompted both academia and industry to explore how these models can be tailored for specific industries and application scenarios. This process, known as the customization of domain-specific foundation models, addresses the limitations of general-purpose models, which may not fully capture the unique patterns and requirements of domain-specific data. Despite its importance, there is a notable lack of comprehensive overview papers on building domain-specific foundation models, while numerous resources exist for general-purpose models. To bridge this gap, this article provides a timely and thorough overview of the methodology for customizing domain-specific foundation models. It introduces basic concepts, outlines the general architecture, and surveys key methods for constructing domain-specific models. Furthermore, the article discusses various domains that can benefit from these specialized models and highlights the challenges ahead. Through this overview, we aim to offer valuable guidance and reference for researchers and practitioners from diverse fields to develop their own customized foundation models.
Modelling the 5G Energy Consumption using Real-world Data: Energy Fingerprint is All You Need
Jun 13, 2024



The introduction of fifth-generation (5G) radio technology has revolutionized communications, bringing unprecedented automation, capacity, connectivity, and ultra-fast, reliable communications. However, this technological leap comes with a substantial increase in energy consumption, presenting a significant challenge. To improve the energy efficiency of 5G networks, it is imperative to develop sophisticated models that accurately reflect the influence of base station (BS) attributes and operational conditions on energy usage.Importantly, addressing the complexity and interdependencies of these diverse features is particularly challenging, both in terms of data processing and model architecture design. This paper proposes a novel 5G base stations energy consumption modelling method by learning from a real-world dataset used in the ITU 5G Base Station Energy Consumption Modelling Challenge in which our model ranked second. Unlike existing methods that omit the Base Station Identifier (BSID) information and thus fail to capture the unique energy fingerprint in different base stations, we incorporate the BSID into the input features and encoding it with an embedding layer for precise representation. Additionally, we introduce a novel masked training method alongside an attention mechanism to further boost the model's generalization capabilities and accuracy. After evaluation, our method demonstrates significant improvements over existing models, reducing Mean Absolute Percentage Error (MAPE) from 12.75% to 4.98%, leading to a performance gain of more than 60%.
Scalable Autonomous Drone Flight in the Forest with Visual-Inertial SLAM and Dense Submaps Built without LiDAR
Mar 14, 2024



Forestry constitutes a key element for a sustainable future, while it is supremely challenging to introduce digital processes to improve efficiency. The main limitation is the difficulty of obtaining accurate maps at high temporal and spatial resolution as a basis for informed forestry decision-making, due to the vast area forests extend over and the sheer number of trees. To address this challenge, we present an autonomous Micro Aerial Vehicle (MAV) system which purely relies on cost-effective and light-weight passive visual and inertial sensors to perform under-canopy autonomous navigation. We leverage visual-inertial simultaneous localization and mapping (VI-SLAM) for accurate MAV state estimates and couple it with a volumetric occupancy submapping system to achieve a scalable mapping framework which can be directly used for path planning. As opposed to a monolithic map, submaps inherently deal with inevitable drift and corrections from VI-SLAM, since they move with pose estimates as they are updated. To ensure the safety of the MAV during navigation, we also propose a novel reference trajectory anchoring scheme that moves and deforms the reference trajectory the MAV is tracking upon state updates from the VI-SLAM system in a consistent way, even upon large changes in state estimates due to loop-closures. We thoroughly validate our system in both real and simulated forest environments with high tree densities in excess of 400 trees per hectare and at speeds up to 3 m/s - while not encountering a single collision or system failure. To the best of our knowledge this is the first system which achieves this level of performance in such unstructured environment using low-cost passive visual sensors and fully on-board computation including VI-SLAM.
FuncGrasp: Learning Object-Centric Neural Grasp Functions from Single Annotated Example Object
Feb 22, 2024We present FuncGrasp, a framework that can infer dense yet reliable grasp configurations for unseen objects using one annotated object and single-view RGB-D observation via categorical priors. Unlike previous works that only transfer a set of grasp poses, FuncGrasp aims to transfer infinite configurations parameterized by an object-centric continuous grasp function across varying instances. To ease the transfer process, we propose Neural Surface Grasping Fields (NSGF), an effective neural representation defined on the surface to densely encode grasp configurations. Further, we exploit function-to-function transfer using sphere primitives to establish semantically meaningful categorical correspondences, which are learned in an unsupervised fashion without any expert knowledge. We showcase the effectiveness through extensive experiments in both simulators and the real world. Remarkably, our framework significantly outperforms several strong baseline methods in terms of density and reliability for generated grasps.
Anthropomorphic Grasping with Neural Object Shape Completion
Nov 09, 2023



The progressive prevalence of robots in human-suited environments has given rise to a myriad of object manipulation techniques, in which dexterity plays a paramount role. It is well-established that humans exhibit extraordinary dexterity when handling objects. Such dexterity seems to derive from a robust understanding of object properties (such as weight, size, and shape), as well as a remarkable capacity to interact with them. Hand postures commonly demonstrate the influence of specific regions on objects that need to be grasped, especially when objects are partially visible. In this work, we leverage human-like object understanding by reconstructing and completing their full geometry from partial observations, and manipulating them using a 7-DoF anthropomorphic robot hand. Our approach has significantly improved the grasping success rates of baselines with only partial reconstruction by nearly 30% and achieved over 150 successful grasps with three different object categories. This demonstrates our approach's consistent ability to predict and execute grasping postures based on the completed object shapes from various directions and positions in real-world scenarios. Our work opens up new possibilities for enhancing robotic applications that require precise grasping and manipulation skills of real-world reconstructed objects.
TexPose: Neural Texture Learning for Self-Supervised 6D Object Pose Estimation
Dec 25, 2022In this paper, we introduce neural texture learning for 6D object pose estimation from synthetic data and a few unlabelled real images. Our major contribution is a novel learning scheme which removes the drawbacks of previous works, namely the strong dependency on co-modalities or additional refinement. These have been previously necessary to provide training signals for convergence. We formulate such a scheme as two sub-optimisation problems on texture learning and pose learning. We separately learn to predict realistic texture of objects from real image collections and learn pose estimation from pixel-perfect synthetic data. Combining these two capabilities allows then to synthesise photorealistic novel views to supervise the pose estimator with accurate geometry. To alleviate pose noise and segmentation imperfection present during the texture learning phase, we propose a surfel-based adversarial training loss together with texture regularisation from synthetic data. We demonstrate that the proposed approach significantly outperforms the recent state-of-the-art methods without ground-truth pose annotations and demonstrates substantial generalisation improvements towards unseen scenes. Remarkably, our scheme improves the adopted pose estimators substantially even when initialised with much inferior performance.
Attention meets Geometry: Geometry Guided Spatial-Temporal Attention for Consistent Self-Supervised Monocular Depth Estimation
Oct 15, 2021
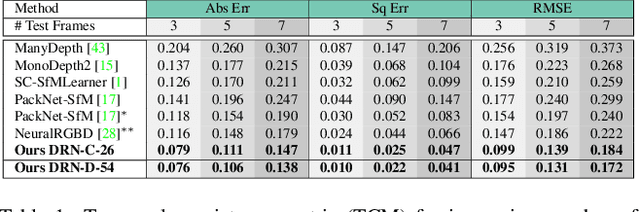

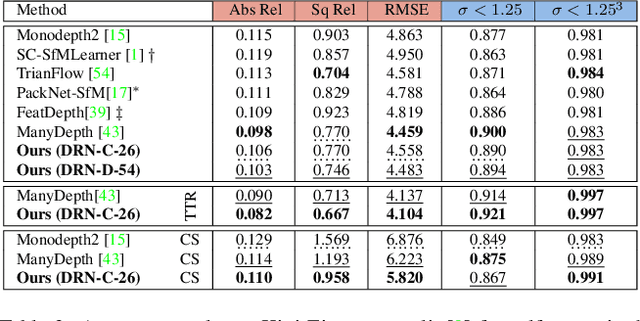
Inferring geometrically consistent dense 3D scenes across a tuple of temporally consecutive images remains challenging for self-supervised monocular depth prediction pipelines. This paper explores how the increasingly popular transformer architecture, together with novel regularized loss formulations, can improve depth consistency while preserving accuracy. We propose a spatial attention module that correlates coarse depth predictions to aggregate local geometric information. A novel temporal attention mechanism further processes the local geometric information in a global context across consecutive images. Additionally, we introduce geometric constraints between frames regularized by photometric cycle consistency. By combining our proposed regularization and the novel spatial-temporal-attention module we fully leverage both the geometric and appearance-based consistency across monocular frames. This yields geometrically meaningful attention and improves temporal depth stability and accuracy compared to previous methods.