 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe XPRESS Challenge: Xray Projectomic Reconstruction -- Extracting Segmentation with Skeletons
Feb 24, 2023



The wiring and connectivity of neurons form a structural basis for the function of the nervous system. Advances in volume electron microscopy (EM) and image segmentation have enabled mapping of circuit diagrams (connectomics) within local regions of the mouse brain. However, applying volume EM over the whole brain is not currently feasible due to technological challenges. As a result, comprehensive maps of long-range connections between brain regions are lacking. Recently, we demonstrated that X-ray holographic nanotomography (XNH) can provide high-resolution images of brain tissue at a much larger scale than EM. In particular, XNH is wellsuited to resolve large, myelinated axon tracts (white matter) that make up the bulk of long-range connections (projections) and are critical for inter-region communication. Thus, XNH provides an imaging solution for brain-wide projectomics. However, because XNH data is typically collected at lower resolutions and larger fields-of-view than EM, accurate segmentation of XNH images remains an important challenge that we present here. In this task, we provide volumetric XNH images of cortical white matter axons from the mouse brain along with ground truth annotations for axon trajectories. Manual voxel-wise annotation of ground truth is a time-consuming bottleneck for training segmentation networks. On the other hand, skeleton-based ground truth is much faster to annotate, and sufficient to determine connectivity. Therefore, we encourage participants to develop methods to leverage skeleton-based training. To this end, we provide two types of ground-truth annotations: a small volume of voxel-wise annotations and a larger volume with skeleton-based annotations. Entries will be evaluated on how accurately the submitted segmentations agree with the ground-truth skeleton annotations.
An Out-of-Domain Synapse Detection Challenge for Microwasp Brain Connectomes
Feb 01, 2023



The size of image stacks in connectomics studies now reaches the terabyte and often petabyte scales with a great diversity of appearance across brain regions and samples. However, manual annotation of neural structures, e.g., synapses, is time-consuming, which leads to limited training data often smaller than 0.001\% of the test data in size. Domain adaptation and generalization approaches were proposed to address similar issues for natural images, which were less evaluated on connectomics data due to a lack of out-of-domain benchmarks.
QuantArt: Quantizing Image Style Transfer Towards High Visual Fidelity
Dec 20, 2022The mechanism of existing style transfer algorithms is by minimizing a hybrid loss function to push the generated image toward high similarities in both content and style. However, this type of approach cannot guarantee visual fidelity, i.e., the generated artworks should be indistinguishable from real ones. In this paper, we devise a new style transfer framework called QuantArt for high visual-fidelity stylization. QuantArt pushes the latent representation of the generated artwork toward the centroids of the real artwork distribution with vector quantization. By fusing the quantized and continuous latent representations, QuantArt allows flexible control over the generated artworks in terms of content preservation, style similarity, and visual fidelity. Experiments on various style transfer settings show that our QuantArt framework achieves significantly higher visual fidelity compared with the existing style transfer methods.
ShadowDiffusion: When Degradation Prior Meets Diffusion Model for Shadow Removal
Dec 13, 2022Recent deep learning methods have achieved promising results in image shadow removal. However, their restored images still suffer from unsatisfactory boundary artifacts, due to the lack of degradation prior embedding and the deficiency in modeling capacity. Our work addresses these issues by proposing a unified diffusion framework that integrates both the image and degradation priors for highly effective shadow removal. In detail, we first propose a shadow degradation model, which inspires us to build a novel unrolling diffusion model, dubbed ShandowDiffusion. It remarkably improves the model's capacity in shadow removal via progressively refining the desired output with both degradation prior and diffusive generative prior, which by nature can serve as a new strong baseline for image restoration. Furthermore, ShadowDiffusion progressively refines the estimated shadow mask as an auxiliary task of the diffusion generator, which leads to more accurate and robust shadow-free image generation. We conduct extensive experiments on three popular public datasets, including ISTD, ISTD+, and SRD, to validate our method's effectiveness. Compared to the state-of-the-art methods, our model achieves a significant improvement in terms of PSNR, increasing from 31.69dB to 34.73dB over SRD dataset.
Human or Machine? Turing Tests for Vision and Language
Nov 23, 2022As AI algorithms increasingly participate in daily activities that used to be the sole province of humans, we are inevitably called upon to consider how much machines are really like us. To address this question, we turn to the Turing test and systematically benchmark current AIs in their abilities to imitate humans. We establish a methodology to evaluate humans versus machines in Turing-like tests and systematically evaluate a representative set of selected domains, parameters, and variables. The experiments involved testing 769 human agents, 24 state-of-the-art AI agents, 896 human judges, and 8 AI judges, in 21,570 Turing tests across 6 tasks encompassing vision and language modalities. Surprisingly, the results reveal that current AIs are not far from being able to impersonate human judges across different ages, genders, and educational levels in complex visual and language challenges. In contrast, simple AI judges outperform human judges in distinguishing human answers versus machine answers. The curated large-scale Turing test datasets introduced here and their evaluation metrics provide valuable insights to assess whether an agent is human or not. The proposed formulation to benchmark human imitation ability in current AIs paves a way for the research community to expand Turing tests to other research areas and conditions. All of source code and data are publicly available at https://tinyurl.com/8x8nha7p
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task
Oct 25, 2022



Language models show a surprising range of capabilities, but the source of their apparent competence is unclear. Do these networks just memorize a collection of surface statistics, or do they rely on internal representations of the process that generates the sequences they see? We investigate this question by applying a variant of the GPT model to the task of predicting legal moves in a simple board game, Othello. Although the network has no a priori knowledge of the game or its rules, we uncover evidence of an emergent nonlinear internal representation of the board state. Interventional experiments indicate this representation can be used to control the output of the network and create "latent saliency maps" that can help explain predictions in human terms.
RibSeg v2: A Large-scale Benchmark for Rib Labeling and Anatomical Centerline Extraction
Oct 18, 2022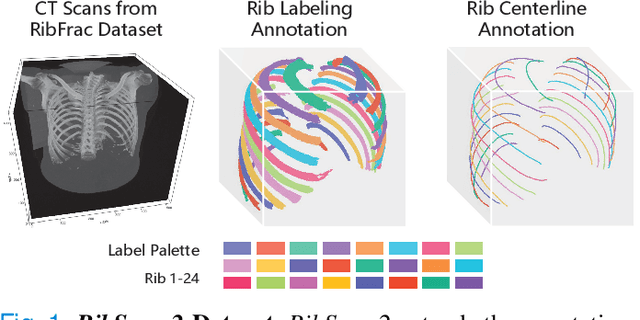

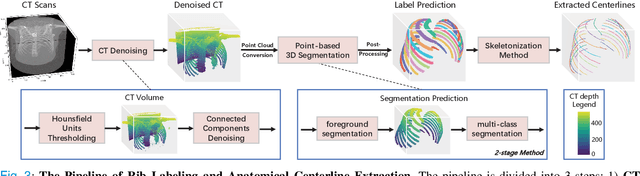
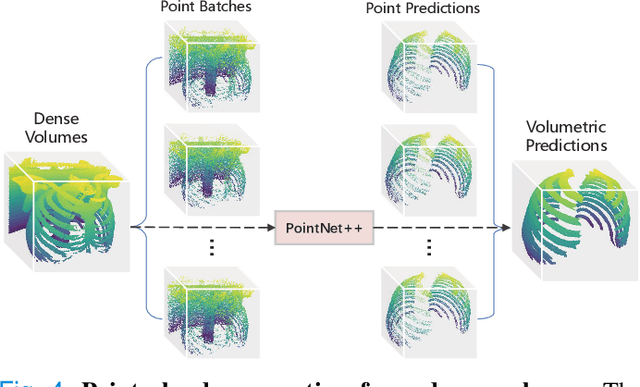
Automatic rib labeling and anatomical centerline extraction are common prerequisites for various clinical applications. Prior studies either use in-house datasets that are inaccessible to communities, or focus on rib segmentation that neglects the clinical significance of rib labeling. To address these issues, we extend our prior dataset (RibSeg) on the binary rib segmentation task to a comprehensive benchmark, named RibSeg v2, with 660 CT scans (15,466 individual ribs in total) and annotations manually inspected by experts for rib labeling and anatomical centerline extraction. Based on the RibSeg v2, we develop a pipeline including deep learning-based methods for rib labeling, and a skeletonization-based method for centerline extraction. To improve computational efficiency, we propose a sparse point cloud representation of CT scans and compare it with standard dense voxel grids. Moreover, we design and analyze evaluation metrics to address the key challenges of each task. Our dataset, code, and model are available online to facilitate open research at https://github.com/M3DV/RibSeg
Interactive and Visual Prompt Engineering for Ad-hoc Task Adaptation with Large Language Models
Aug 16, 2022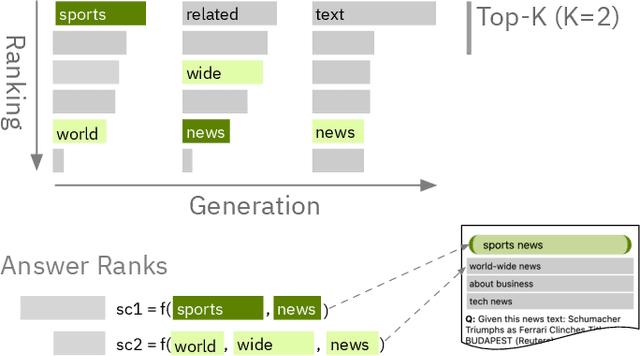

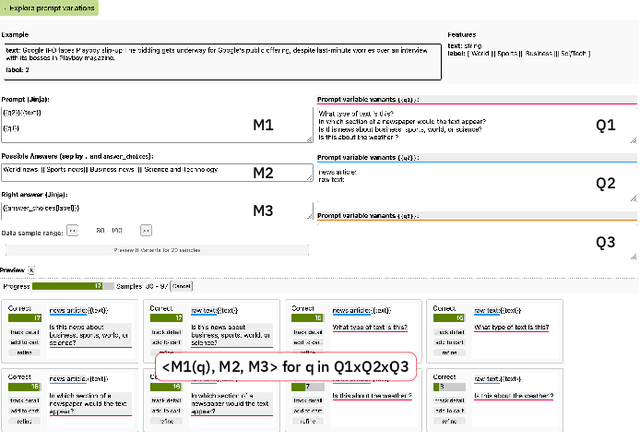
State-of-the-art neural language models can now be used to solve ad-hoc language tasks through zero-shot prompting without the need for supervised training. This approach has gained popularity in recent years, and researchers have demonstrated prompts that achieve strong accuracy on specific NLP tasks. However, finding a prompt for new tasks requires experimentation. Different prompt templates with different wording choices lead to significant accuracy differences. PromptIDE allows users to experiment with prompt variations, visualize prompt performance, and iteratively optimize prompts. We developed a workflow that allows users to first focus on model feedback using small data before moving on to a large data regime that allows empirical grounding of promising prompts using quantitative measures of the task. The tool then allows easy deployment of the newly created ad-hoc models. We demonstrate the utility of PromptIDE (demo at http://prompt.vizhub.ai) and our workflow using several real-world use cases.
What makes domain generalization hard?
Jun 15, 2022
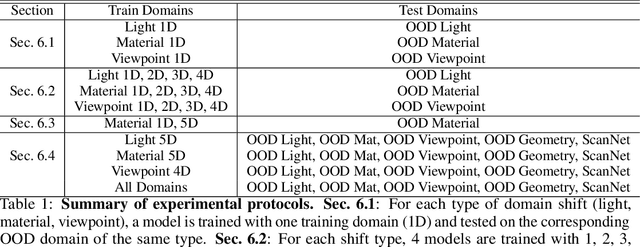
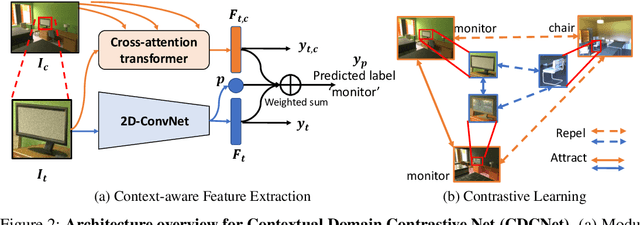
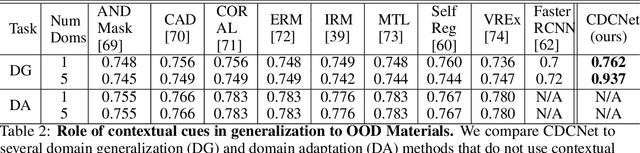
While several methodologies have been proposed for the daunting task of domain generalization, understanding what makes this task challenging has received little attention. Here we present SemanticDG (Semantic Domain Generalization): a benchmark with 15 photo-realistic domains with the same geometry, scene layout and camera parameters as the popular 3D ScanNet dataset, but with controlled domain shifts in lighting, materials, and viewpoints. Using this benchmark, we investigate the impact of each of these semantic shifts on generalization independently. Visual recognition models easily generalize to novel lighting, but struggle with distribution shifts in materials and viewpoints. Inspired by human vision, we hypothesize that scene context can serve as a bridge to help models generalize across material and viewpoint domain shifts and propose a context-aware vision transformer along with a contrastive loss over material and viewpoint changes to address these domain shifts. Our approach (dubbed as CDCNet) outperforms existing domain generalization methods by over an 18% margin. As a critical benchmark, we also conduct psychophysics experiments and find that humans generalize equally well across lighting, materials and viewpoints. The benchmark and computational model introduced here help understand the challenges associated with generalization across domains and provide initial steps towards extrapolation to semantic distribution shifts. We include all data and source code in the supplement.
Diagnosing Ensemble Few-Shot Classifiers
Jun 09, 2022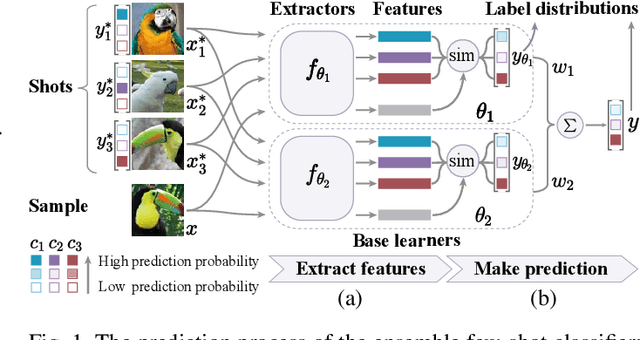
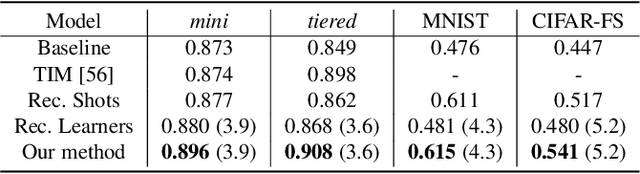
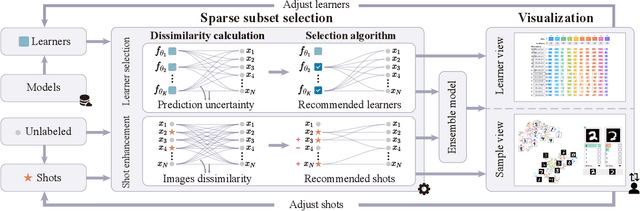

The base learners and labeled samples (shots) in an ensemble few-shot classifier greatly affect the model performance. When the performance is not satisfactory, it is usually difficult to understand the underlying causes and make improvements. To tackle this issue, we propose a visual analysis method, FSLDiagnotor. Given a set of base learners and a collection of samples with a few shots, we consider two problems: 1) finding a subset of base learners that well predict the sample collections; and 2) replacing the low-quality shots with more representative ones to adequately represent the sample collections. We formulate both problems as sparse subset selection and develop two selection algorithms to recommend appropriate learners and shots, respectively. A matrix visualization and a scatterplot are combined to explain the recommended learners and shots in context and facilitate users in adjusting them. Based on the adjustment, the algorithm updates the recommendation results for another round of improvement. Two case studies are conducted to demonstrate that FSLDiagnotor helps build a few-shot classifier efficiently and increases the accuracy by 12% and 21%, respectively.