 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptSkills: Learning Generalizable Optimization Skills from Problem Archetypes via Cluster-Based Distillation
May 28, 2026Leveraging Large Language Models (LLMs) to automatically formulate and solve optimization problems from natural language has emerged as an efficient paradigm for automated optimization. However, existing methods still exhibit limited generalization: they are sensitive to superficial narrative variations, reuse experience mainly at the case level, and struggle to adapt to shifted or emerging problem types. We propose OptSkills, an archetype-centric skill learning and reasoning agent system for optimization modeling and solving. To improve robust generalization, our system clusters problems by their underlying archetypes rather than surface narratives. To improve in-distribution generalization, it explores diverse modeling paradigms and solver configurations within each cluster, then distills successful trajectories into reusable workflow-level skills. To improve out-of-distribution generalization, it refines existing skills or expands the skill library using newly obtained trajectories. Our system achieves a state-of-the-art micro-averaged accuracy of 68.27% on datasets encompassing diverse problem types and scenarios. In addition, on MIPLIB-NL, a highly challenging large-scale and high-dimensional benchmark, it achieves 26.91% accuracy, outperforming DeepSeek-V3.2-Thinking by 4.53%. After skill learning on Nano-CO, it reaches 72.79% on the OOD NLCO benchmark. Code and skills are available at https://github.com/fujiwaranoM0kou/OptSkills.
Optimal Transport for LLM Reward Modeling from Noisy Preference
May 07, 2026Reward models are fundamental to Reinforcement Learning from Human Feedback (RLHF), yet real-world datasets are inevitably corrupted by noisy preference. Conventional training objectives tend to overfit these errors, while existing denoising approaches often rely on homogeneous noise assumptions that fail to capture the complexity of linguistic preferences. To handle these challenges, we propose SelectiveRM, a framework grounded in optimal transport. We first devise a Joint Consistency Discrepancy to align the distribution of model predictions with preference data. Furthermore, to address the limitation of strict mass conservation which compels the model to fit outliers, we incorporate a Mass Relaxation mechanism via partial transport. This enables the autonomous exclusion of samples with noisy preference that contradict semantic consistency. Theoretically, we demonstrate that SelectiveRM optimizes a tighter upper bound on the unobserved clean risk. Extensive experiments validate that our approach significantly outperforms state-of-the-art baselines across diverse benchmarks.
Unsupervised Multi-agent and Single-agent Perception from Cooperative Views
Apr 07, 2026The LiDAR-based multi-agent and single-agent perception has shown promising performance in environmental understanding for robots and automated vehicles. However, there is no existing method that simultaneously solves both multi-agent and single-agent perception in an unsupervised way. By sharing sensor data between multiple agents via communication, this paper discovers two key insights: 1) Improved point cloud density after the data sharing from cooperative views could benefit unsupervised object classification, 2) Cooperative view of multiple agents can be used as unsupervised guidance for the 3D object detection in the single view. Based on these two discovered insights, we propose an Unsupervised Multi-agent and Single-agent (UMS) perception framework that leverages multi-agent cooperation without human annotations to simultaneously solve multi-agent and single-agent perception. UMS combines a learning-based Proposal Purifying Filter to better classify the candidate proposals after multi-agent point cloud density cooperation, followed by a Progressive Proposal Stabilizing module to yield reliable pseudo labels by the easy-to-hard curriculum learning. Furthermore, we design a Cross-View Consensus Learning to use multi-agent cooperative view to guide detection in single-agent view. Experimental results on two public datasets V2V4Real and OPV2V show that our UMS method achieved significantly higher 3D detection performance than the state-of-the-art methods on both multi-agent and single-agent perception tasks in an unsupervised setting.
DarkDriving: A Real-World Day and Night Aligned Dataset for Autonomous Driving in the Dark Environment
Mar 18, 2026The low-light conditions are challenging to the vision-centric perception systems for autonomous driving in the dark environment. In this paper, we propose a new benchmark dataset (named DarkDriving) to investigate the low-light enhancement for autonomous driving. The existing real-world low-light enhancement benchmark datasets can be collected by controlling various exposures only in small-ranges and static scenes. The dark images of the current nighttime driving datasets do not have the precisely aligned daytime counterparts. The extreme difficulty to collect a real-world day and night aligned dataset in the dynamic driving scenes significantly limited the research in this area. With a proposed automatic day-night Trajectory Tracking based Pose Matching (TTPM) method in a large real-world closed driving test field (area: 69 acres), we collected the first real-world day and night aligned dataset for autonomous driving in the dark environment. The DarkDriving dataset has 9,538 day and night image pairs precisely aligned in location and spatial contents, whose alignment error is in just several centimeters. For each pair, we also manually label the object 2D bounding boxes. DarkDriving introduces four perception related tasks, including low-light enhancement, generalized low-light enhancement, and low-light enhancement for 2D detection and 3D detection of autonomous driving in the dark environment. The experimental results show that our DarkDriving dataset provides a comprehensive benchmark for evaluating low-light enhancement for autonomous driving and it can also be generalized to enhance dark images and promote detection in some other low-light driving environment, such as nuScenes.
Stealthy Multi-Task Adversarial Attacks
Nov 26, 2024



Deep Neural Networks exhibit inherent vulnerabilities to adversarial attacks, which can significantly compromise their outputs and reliability. While existing research primarily focuses on attacking single-task scenarios or indiscriminately targeting all tasks in multi-task environments, we investigate selectively targeting one task while preserving performance in others within a multi-task framework. This approach is motivated by varying security priorities among tasks in real-world applications, such as autonomous driving, where misinterpreting critical objects (e.g., signs, traffic lights) poses a greater security risk than minor depth miscalculations. Consequently, attackers may hope to target security-sensitive tasks while avoiding non-critical tasks from being compromised, thus evading being detected before compromising crucial functions. In this paper, we propose a method for the stealthy multi-task attack framework that utilizes multiple algorithms to inject imperceptible noise into the input. This novel method demonstrates remarkable efficacy in compromising the target task while simultaneously maintaining or even enhancing performance across non-targeted tasks - a criterion hitherto unexplored in the field. Additionally, we introduce an automated approach for searching the weighting factors in the loss function, further enhancing attack efficiency. Experimental results validate our framework's ability to successfully attack the target task while preserving the performance of non-targeted tasks. The automated loss function weight searching method demonstrates comparable efficacy to manual tuning, establishing a state-of-the-art multi-task attack framework.
Human or Machine? Turing Tests for Vision and Language
Nov 23, 2022As AI algorithms increasingly participate in daily activities that used to be the sole province of humans, we are inevitably called upon to consider how much machines are really like us. To address this question, we turn to the Turing test and systematically benchmark current AIs in their abilities to imitate humans. We establish a methodology to evaluate humans versus machines in Turing-like tests and systematically evaluate a representative set of selected domains, parameters, and variables. The experiments involved testing 769 human agents, 24 state-of-the-art AI agents, 896 human judges, and 8 AI judges, in 21,570 Turing tests across 6 tasks encompassing vision and language modalities. Surprisingly, the results reveal that current AIs are not far from being able to impersonate human judges across different ages, genders, and educational levels in complex visual and language challenges. In contrast, simple AI judges outperform human judges in distinguishing human answers versus machine answers. The curated large-scale Turing test datasets introduced here and their evaluation metrics provide valuable insights to assess whether an agent is human or not. The proposed formulation to benchmark human imitation ability in current AIs paves a way for the research community to expand Turing tests to other research areas and conditions. All of source code and data are publicly available at https://tinyurl.com/8x8nha7p
Improving Graph Representation Learning by Contrastive Regularization
Jan 27, 2021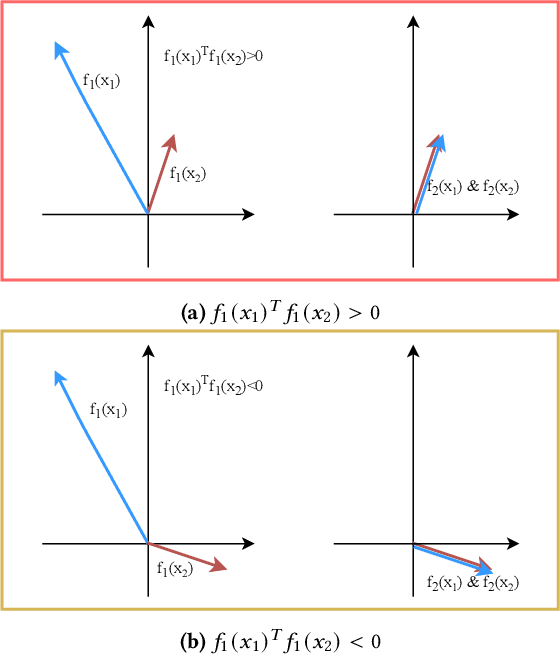
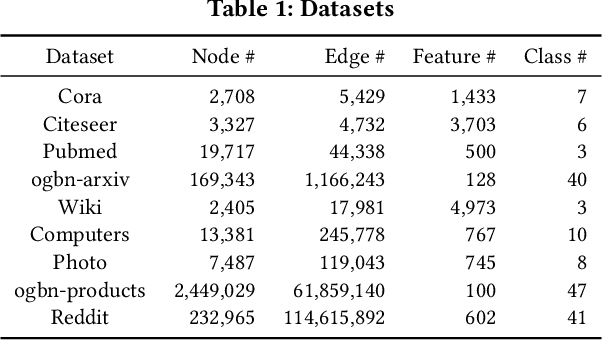
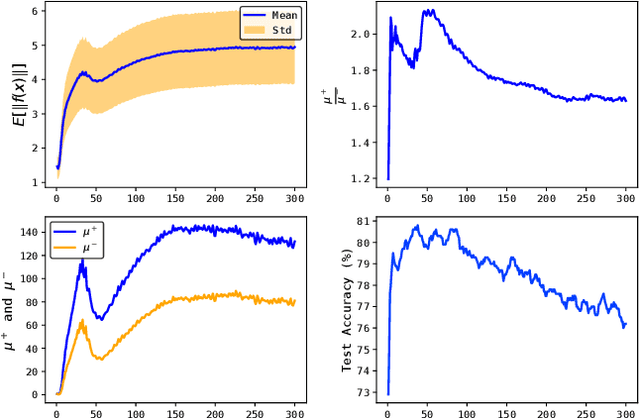
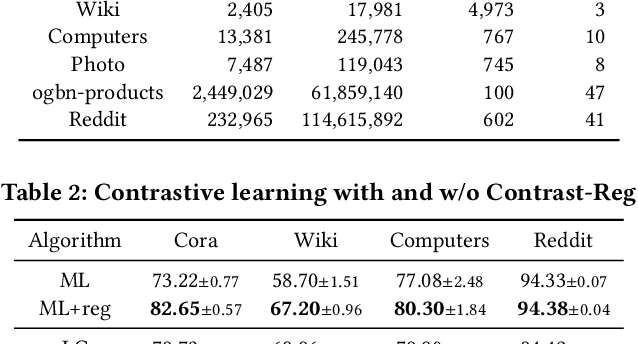
Graph representation learning is an important task with applications in various areas such as online social networks, e-commerce networks, WWW, and semantic webs. For unsupervised graph representation learning, many algorithms such as Node2Vec and Graph-SAGE make use of "negative sampling" and/or noise contrastive estimation loss. This bears similar ideas to contrastive learning, which "contrasts" the node representation similarities of semantically similar (positive) pairs against those of negative pairs. However, despite the success of contrastive learning, we found that directly applying this technique to graph representation learning models (e.g., graph convolutional networks) does not always work. We theoretically analyze the generalization performance and propose a light-weight regularization term that avoids the high scales of node representations' norms and the high variance among them to improve the generalization performance. Our experimental results further validate that this regularization term significantly improves the representation quality across different node similarity definitions and outperforms the state-of-the-art methods.