 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Intelligence Emerges from Large-Scale Clinical Practice: A Retinal Foundation Model with Deployment Efficiency
Dec 16, 2025Current retinal foundation models remain constrained by curated research datasets that lack authentic clinical context, and require extensive task-specific optimization for each application, limiting their deployment efficiency in low-resource settings. Here, we show that these barriers can be overcome by building clinical native intelligence directly from real-world medical practice. Our key insight is that large-scale telemedicine programs, where expert centers provide remote consultations across distributed facilities, represent a natural reservoir for learning clinical image interpretation. We present ReVision, a retinal foundation model that learns from the natural alignment between 485,980 color fundus photographs and their corresponding diagnostic reports, accumulated through a decade-long telemedicine program spanning 162 medical institutions across China. Through extensive evaluation across 27 ophthalmic benchmarks, we demonstrate that ReVison enables deployment efficiency with minimal local resources. Without any task-specific training, ReVision achieves zero-shot disease detection with an average AUROC of 0.946 across 12 public benchmarks and 0.952 on 3 independent clinical cohorts. When minimal adaptation is feasible, ReVision matches extensively fine-tuned alternatives while requiring orders of magnitude fewer trainable parameters and labeled examples. The learned representations also transfer effectively to new clinical sites, imaging domains, imaging modalities, and systemic health prediction tasks. In a prospective reader study with 33 ophthalmologists, ReVision's zero-shot assistance improved diagnostic accuracy by 14.8% across all experience levels. These results demonstrate that clinical native intelligence can be directly extracted from clinical archives without any further annotation to build medical AI systems suited to various low-resource settings.
RetSTA: An LLM-Based Approach for Standardizing Clinical Fundus Image Reports
Mar 12, 2025



Standardization of clinical reports is crucial for improving the quality of healthcare and facilitating data integration. The lack of unified standards, including format, terminology, and style, is a great challenge in clinical fundus diagnostic reports, which increases the difficulty for large language models (LLMs) to understand the data. To address this, we construct a bilingual standard terminology, containing fundus clinical terms and commonly used descriptions in clinical diagnosis. Then, we establish two models, RetSTA-7B-Zero and RetSTA-7B. RetSTA-7B-Zero, fine-tuned on an augmented dataset simulating clinical scenarios, demonstrates powerful standardization behaviors. However, it encounters a challenge of limitation to cover a wider range of diseases. To further enhance standardization performance, we build RetSTA-7B, which integrates a substantial amount of standardized data generated by RetSTA-7B-Zero along with corresponding English data, covering diverse complex clinical scenarios and achieving report-level standardization for the first time. Experimental results demonstrate that RetSTA-7B outperforms other compared LLMs in bilingual standardization task, which validates its superior performance and generalizability. The checkpoints are available at https://github.com/AB-Story/RetSTA-7B.
ViLReF: A Chinese Vision-Language Retinal Foundation Model
Aug 20, 2024



Subtle semantic differences in retinal image and text data present great challenges for pre-training visual-language models. Moreover, false negative samples, i.e., image-text pairs having the same semantics but incorrectly regarded as negatives, disrupt the visual-language pre-training process and affect the model's learning ability. This work aims to develop a retinal foundation model, called ViLReF, by pre-training on a paired dataset comprising 451,956 retinal images and corresponding diagnostic text reports. In our vision-language pre-training strategy, we leverage expert knowledge to facilitate the extraction of labels and propose a novel constraint, the Weighted Similarity Coupling Loss, to adjust the speed of pushing sample pairs further apart dynamically within the feature space. Furthermore, we employ a batch expansion module with dynamic memory queues, maintained by momentum encoders, to supply extra samples and compensate for the vacancies caused by eliminating false negatives. Extensive experiments are conducted on multiple datasets for downstream classification and segmentation tasks. The experimental results demonstrate the powerful zero-shot and transfer learning capabilities of ViLReF, verifying the effectiveness of our pre-training strategy. Our ViLReF model is available at: https://github.com/T6Yang/ViLReF.
RET-CLIP: A Retinal Image Foundation Model Pre-trained with Clinical Diagnostic Reports
May 23, 2024



The Vision-Language Foundation model is increasingly investigated in the fields of computer vision and natural language processing, yet its exploration in ophthalmology and broader medical applications remains limited. The challenge is the lack of labeled data for the training of foundation model. To handle this issue, a CLIP-style retinal image foundation model is developed in this paper. Our foundation model, RET-CLIP, is specifically trained on a dataset of 193,865 patients to extract general features of color fundus photographs (CFPs), employing a tripartite optimization strategy to focus on left eye, right eye, and patient level to reflect real-world clinical scenarios. Extensive experiments demonstrate that RET-CLIP outperforms existing benchmarks across eight diverse datasets spanning four critical diagnostic categories: diabetic retinopathy, glaucoma, multiple disease diagnosis, and multi-label classification of multiple diseases, which demonstrate the performance and generality of our foundation model. The sourse code and pre-trained model are available at https://github.com/sStonemason/RET-CLIP.
VisionFM: a Multi-Modal Multi-Task Vision Foundation Model for Generalist Ophthalmic Artificial Intelligence
Oct 08, 2023



We present VisionFM, a foundation model pre-trained with 3.4 million ophthalmic images from 560,457 individuals, covering a broad range of ophthalmic diseases, modalities, imaging devices, and demography. After pre-training, VisionFM provides a foundation to foster multiple ophthalmic artificial intelligence (AI) applications, such as disease screening and diagnosis, disease prognosis, subclassification of disease phenotype, and systemic biomarker and disease prediction, with each application enhanced with expert-level intelligence and accuracy. The generalist intelligence of VisionFM outperformed ophthalmologists with basic and intermediate levels in jointly diagnosing 12 common ophthalmic diseases. Evaluated on a new large-scale ophthalmic disease diagnosis benchmark database, as well as a new large-scale segmentation and detection benchmark database, VisionFM outperformed strong baseline deep neural networks. The ophthalmic image representations learned by VisionFM exhibited noteworthy explainability, and demonstrated strong generalizability to new ophthalmic modalities, disease spectrum, and imaging devices. As a foundation model, VisionFM has a large capacity to learn from diverse ophthalmic imaging data and disparate datasets. To be commensurate with this capacity, in addition to the real data used for pre-training, we also generated and leveraged synthetic ophthalmic imaging data. Experimental results revealed that synthetic data that passed visual Turing tests, can also enhance the representation learning capability of VisionFM, leading to substantial performance gains on downstream ophthalmic AI tasks. Beyond the ophthalmic AI applications developed, validated, and demonstrated in this work, substantial further applications can be achieved in an efficient and cost-effective manner using VisionFM as the foundation.
Applications of Deep Learning in Fundus Images: A Review
Jan 25, 2021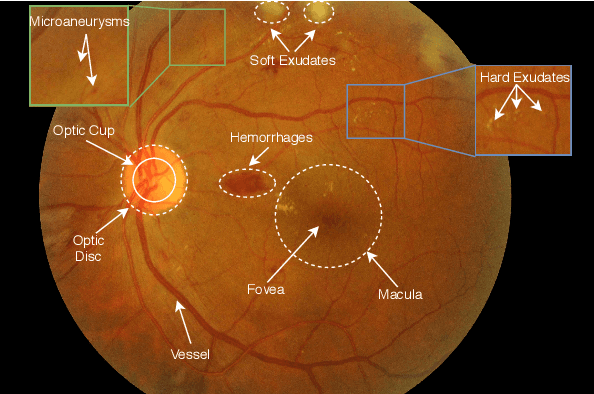
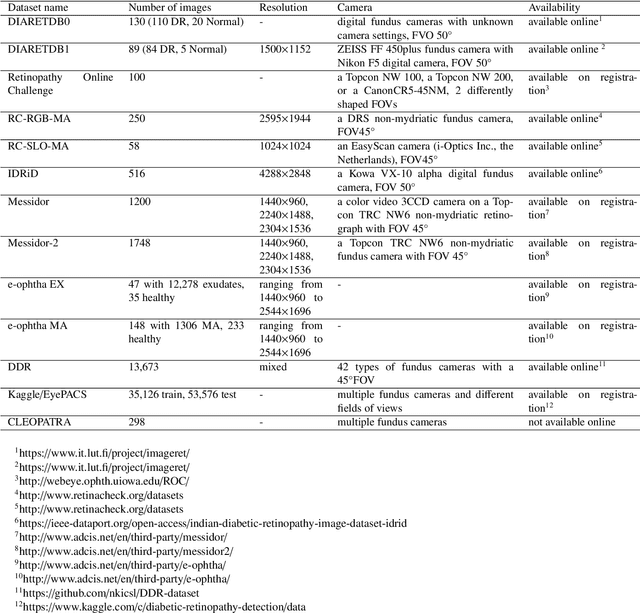
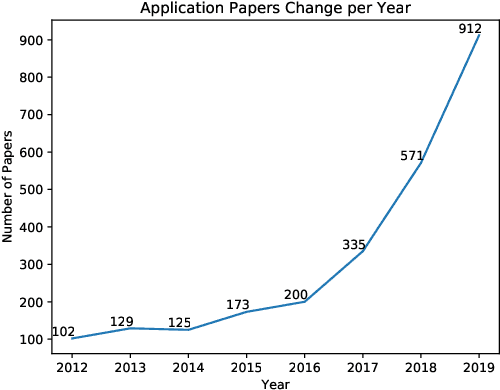
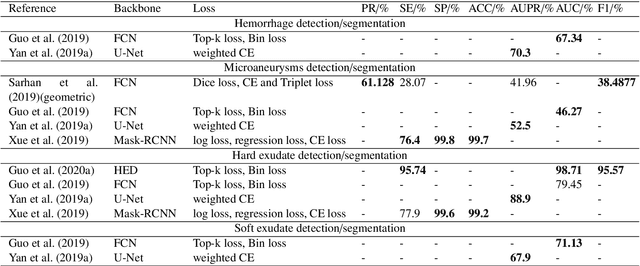
The use of fundus images for the early screening of eye diseases is of great clinical importance. Due to its powerful performance, deep learning is becoming more and more popular in related applications, such as lesion segmentation, biomarkers segmentation, disease diagnosis and image synthesis. Therefore, it is very necessary to summarize the recent developments in deep learning for fundus images with a review paper. In this review, we introduce 143 application papers with a carefully designed hierarchy. Moreover, 33 publicly available datasets are presented. Summaries and analyses are provided for each task. Finally, limitations common to all tasks are revealed and possible solutions are given. We will also release and regularly update the state-of-the-art results and newly-released datasets at https://github.com/nkicsl/Fundus Review to adapt to the rapid development of this field.
Difficulty-aware Glaucoma Classification with Multi-Rater Consensus Modeling
Jul 29, 2020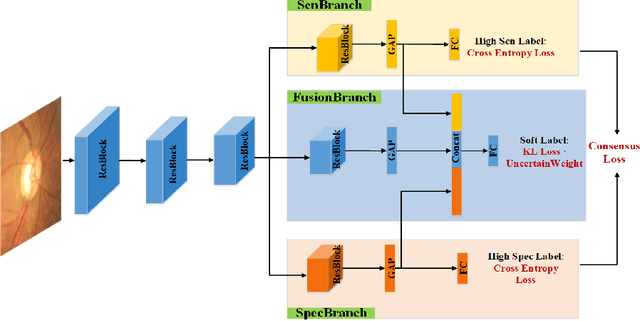
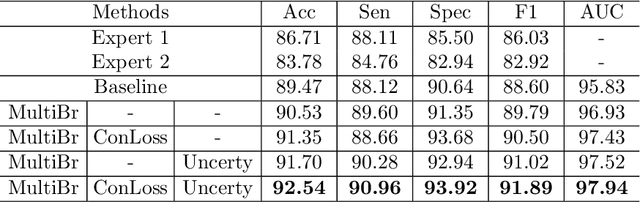
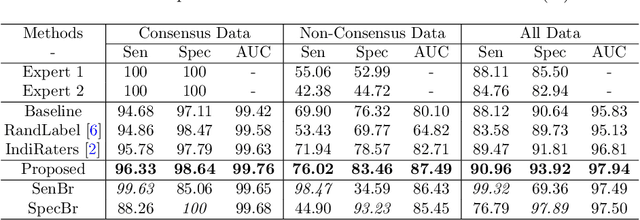
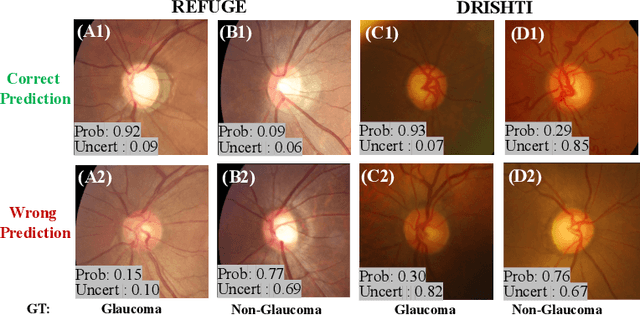
Medical images are generally labeled by multiple experts before the final ground-truth labels are determined. Consensus or disagreement among experts regarding individual images reflects the gradeability and difficulty levels of the image. However, when being used for model training, only the final ground-truth label is utilized, while the critical information contained in the raw multi-rater gradings regarding the image being an easy/hard case is discarded. In this paper, we aim to take advantage of the raw multi-rater gradings to improve the deep learning model performance for the glaucoma classification task. Specifically, a multi-branch model structure is proposed to predict the most sensitive, most specifical and a balanced fused result for the input images. In order to encourage the sensitivity branch and specificity branch to generate consistent results for consensus labels and opposite results for disagreement labels, a consensus loss is proposed to constrain the output of the two branches. Meanwhile, the consistency/inconsistency between the prediction results of the two branches implies the image being an easy/hard case, which is further utilized to encourage the balanced fusion branch to concentrate more on the hard cases. Compared with models trained only with the final ground-truth labels, the proposed method using multi-rater consensus information has achieved superior performance, and it is also able to estimate the difficulty levels of individual input images when making the prediction.
Leveraging Undiagnosed Data for Glaucoma Classification with Teacher-Student Learning
Jul 22, 2020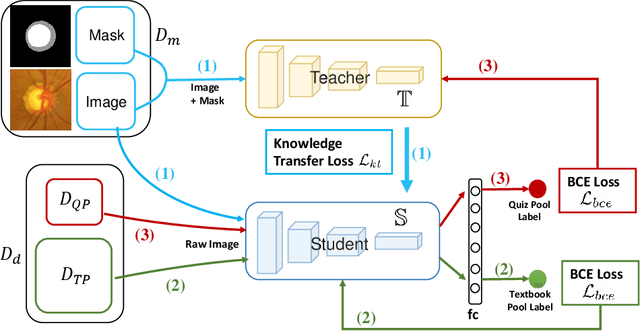
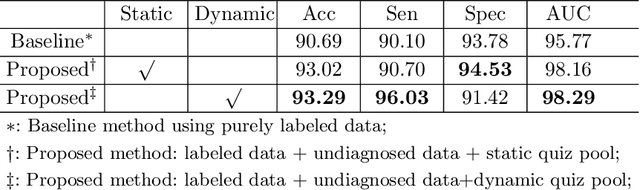
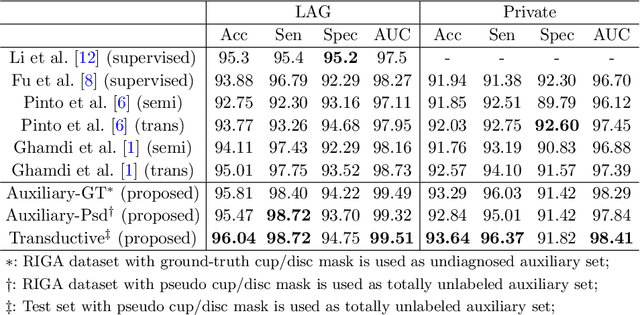
Recently, deep learning has been adopted to the glaucoma classification task with performance comparable to that of human experts. However, a well trained deep learning model demands a large quantity of properly labeled data, which is relatively expensive since the accurate labeling of glaucoma requires years of specialist training. In order to alleviate this problem, we propose a glaucoma classification framework which takes advantage of not only the properly labeled images, but also undiagnosed images without glaucoma labels. To be more specific, the proposed framework is adapted from the teacher-student-learning paradigm. The teacher model encodes the wrapped information of undiagnosed images to a latent feature space, meanwhile the student model learns from the teacher through knowledge transfer to improve the glaucoma classification. For the model training procedure, we propose a novel training strategy that simulates the real-world teaching practice named as 'Learning To Teach with Knowledge Transfer (L2T-KT)', and establish a 'Quiz Pool' as the teacher's optimization target. Experiments show that the proposed framework is able to utilize the undiagnosed data effectively to improve the glaucoma prediction performance.
Attention Based Glaucoma Detection: A Large-scale Database and CNN Model
Mar 28, 2019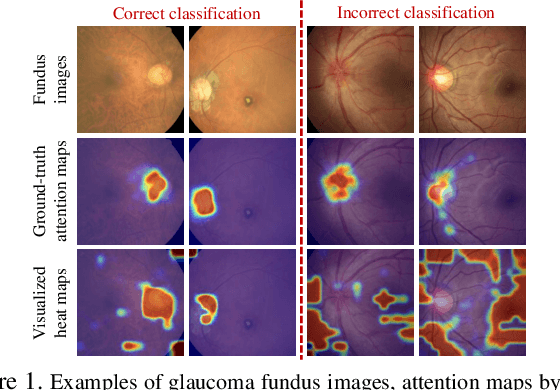


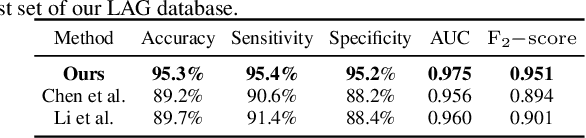
Recently, the attention mechanism has been successfully applied in convolutional neural networks (CNNs), significantly boosting the performance of many computer vision tasks. Unfortunately, few medical image recognition approaches incorporate the attention mechanism in the CNNs. In particular, there exists high redundancy in fundus images for glaucoma detection, such that the attention mechanism has potential in improving the performance of CNN-based glaucoma detection. This paper proposes an attention-based CNN for glaucoma detection (AG-CNN). Specifically, we first establish a large-scale attention based glaucoma (LAG) database, which includes 5,824 fundus images labeled with either positive glaucoma (2,392) or negative glaucoma (3,432). The attention maps of the ophthalmologists are also collected in LAG database through a simulated eye-tracking experiment. Then, a new structure of AG-CNN is designed, including an attention prediction subnet, a pathological area localization subnet and a glaucoma classification subnet. Different from other attention-based CNN methods, the features are also visualized as the localized pathological area, which can advance the performance of glaucoma detection. Finally, the experiment results show that the proposed AG-CNN approach significantly advances state-of-the-art glaucoma detection.