 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFMLinker: Universal Link Predictor by Graph In-Context Learning with Tabular Foundation Models
Feb 09, 2026Link prediction is a fundamental task in graph machine learning with widespread applications such as recommendation systems, drug discovery, knowledge graphs, etc. In the foundation model era, how to develop universal link prediction methods across datasets and domains becomes a key problem, with some initial attempts adopting Graph Foundation Models utilizing Graph Neural Networks and Large Language Models. However, the existing methods face notable limitations, including limited pre-training scale or heavy reliance on textual information. Motivated by the success of tabular foundation models (TFMs) in achieving universal prediction across diverse tabular datasets, we explore an alternative approach by TFMs, which are pre-trained on diverse synthetic datasets sampled from structural causal models and support strong in-context learning independent of textual attributes. Nevertheless, adapting TFMs for link prediction faces severe technical challenges such as how to obtain the necessary context and capture link-centric topological information. To solve these challenges, we propose TFMLinker (Tabular Foundation Model for Link Predictor), aiming to leverage the in-context learning capabilities of TFMs to perform link prediction across diverse graphs without requiring dataset-specific fine-tuning. Specifically, we first develop a prototype-augmented local-global context module to construct context that captures both graph-specific and cross-graph transferable patterns. Next, we design a universal topology-aware link encoder to capture link-centric topological information and generate link representations as inputs for the TFM. Finally, we employ the TFM to predict link existence through in-context learning. Experiments on 6 graph benchmarks across diverse domains demonstrate the superiority of our method over state-of-the-art baselines without requiring dataset-specific finetuning.
Invariant Graph Transformer for Out-of-Distribution Generalization
Aug 01, 2025Graph Transformers (GTs) have demonstrated great effectiveness across various graph analytical tasks. However, the existing GTs focus on training and testing graph data originated from the same distribution, but fail to generalize under distribution shifts. Graph invariant learning, aiming to capture generalizable graph structural patterns with labels under distribution shifts, is potentially a promising solution, but how to design attention mechanisms and positional and structural encodings (PSEs) based on graph invariant learning principles remains challenging. To solve these challenges, we introduce Graph Out-Of-Distribution generalized Transformer (GOODFormer), aiming to learn generalized graph representations by capturing invariant relationships between predictive graph structures and labels through jointly optimizing three modules. Specifically, we first develop a GT-based entropy-guided invariant subgraph disentangler to separate invariant and variant subgraphs while preserving the sharpness of the attention function. Next, we design an evolving subgraph positional and structural encoder to effectively and efficiently capture the encoding information of dynamically changing subgraphs during training. Finally, we propose an invariant learning module utilizing subgraph node representations and encodings to derive generalizable graph representations that can to unseen graphs. We also provide theoretical justifications for our method. Extensive experiments on benchmark datasets demonstrate the superiority of our method over state-of-the-art baselines under distribution shifts.
Semantic-Discriminative Mixup for Generalizable Sensor-based Cross-domain Activity Recognition
Jun 14, 2022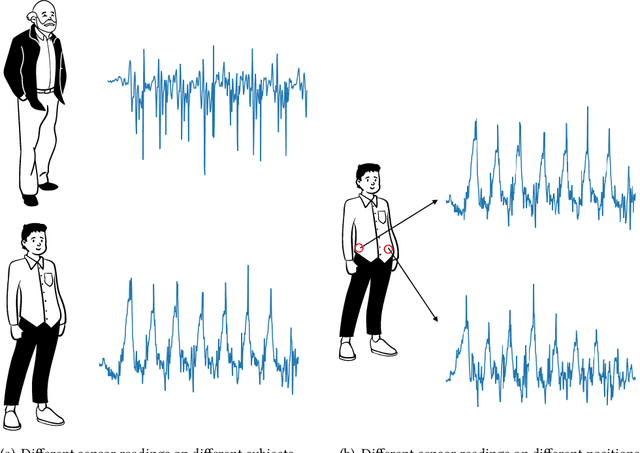
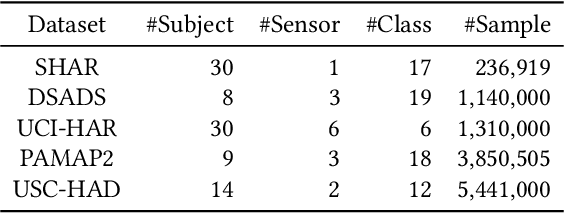
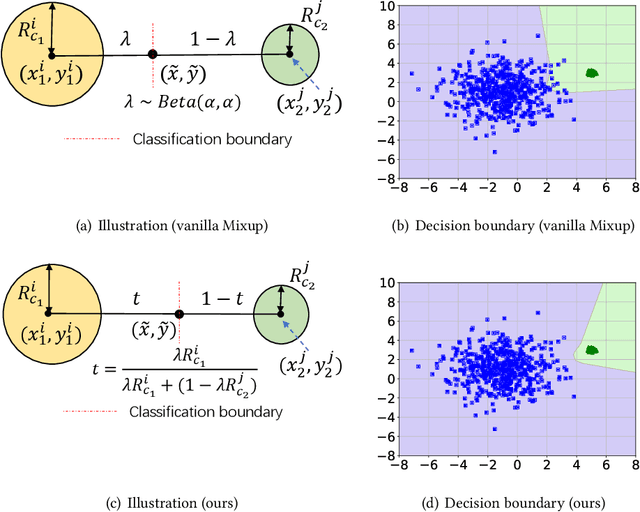
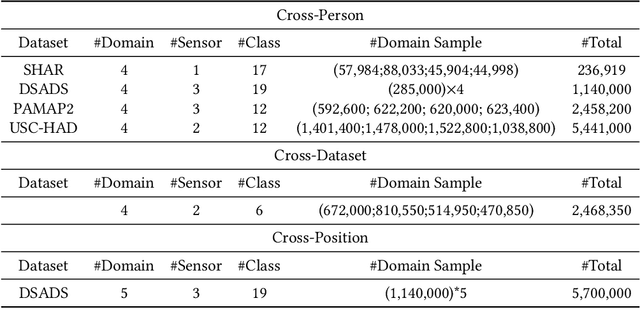
It is expensive and time-consuming to collect sufficient labeled data to build human activity recognition (HAR) models. Training on existing data often makes the model biased towards the distribution of the training data, thus the model might perform terribly on test data with different distributions. Although existing efforts on transfer learning and domain adaptation try to solve the above problem, they still need access to unlabeled data on the target domain, which may not be possible in real scenarios. Few works pay attention to training a model that can generalize well to unseen target domains for HAR. In this paper, we propose a novel method called Semantic-Discriminative Mixup (SDMix) for generalizable cross-domain HAR. Firstly, we introduce semantic-aware Mixup that considers the activity semantic ranges to overcome the semantic inconsistency brought by domain differences. Secondly, we introduce the large margin loss to enhance the discrimination of Mixup to prevent misclassification brought by noisy virtual labels. Comprehensive generalization experiments on five public datasets demonstrate that our SDMix substantially outperforms the state-of-the-art approaches with 6% average accuracy improvement on cross-person, cross-dataset, and cross-position HAR.
A Benchmark of Ocular Disease Intelligent Recognition: One Shot for Multi-disease Detection
Feb 16, 2021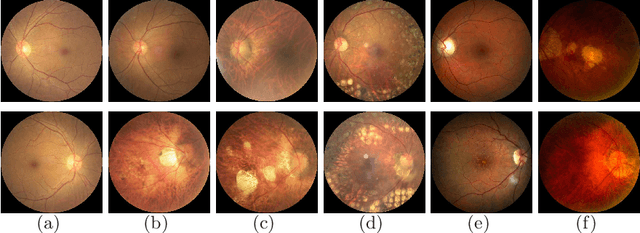
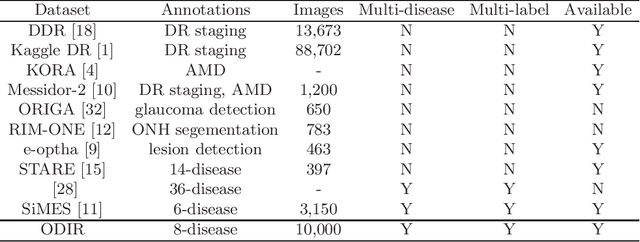
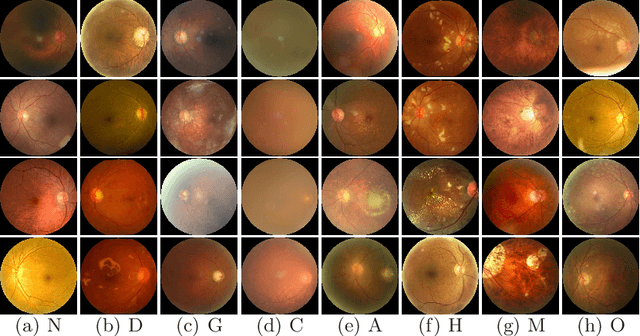
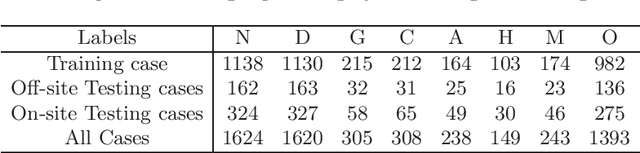
In ophthalmology, early fundus screening is an economic and effective way to prevent blindness caused by ophthalmic diseases. Clinically, due to the lack of medical resources, manual diagnosis is time-consuming and may delay the condition. With the development of deep learning, some researches on ophthalmic diseases have achieved good results, however, most of them are just based on one disease. During fundus screening, ophthalmologists usually give diagnoses of multi-disease on binocular fundus image, so we release a dataset with 8 diseases to meet the real medical scene, which contains 10,000 fundus images from both eyes of 5,000 patients. We did some benchmark experiments on it through some state-of-the-art deep neural networks. We found simply increasing the scale of network cannot bring good results for multi-disease classification, and a well-structured feature fusion method combines characteristics of multi-disease is needed. Through this work, we hope to advance the research of related fields.
Applications of Deep Learning in Fundus Images: A Review
Jan 25, 2021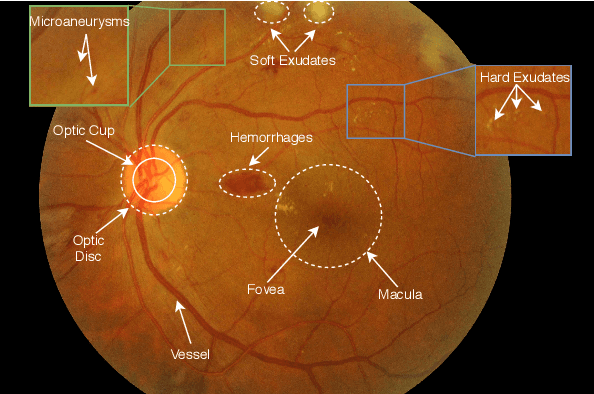
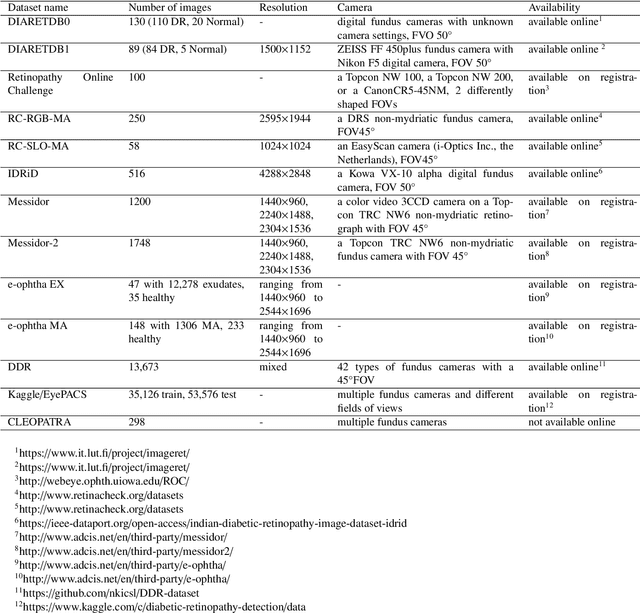
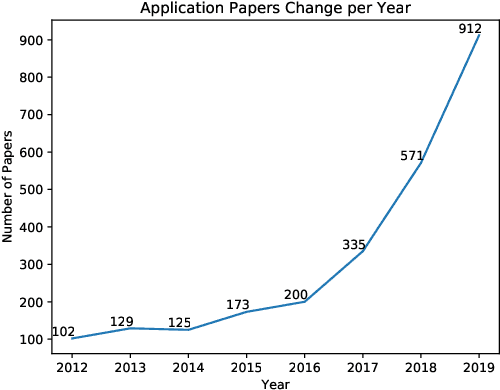
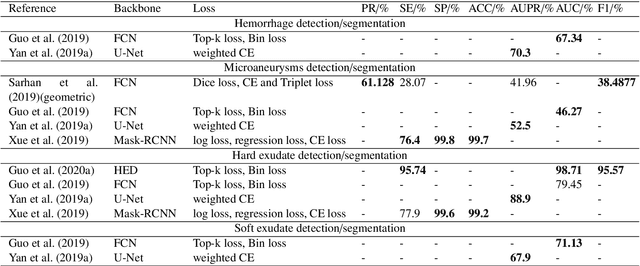
The use of fundus images for the early screening of eye diseases is of great clinical importance. Due to its powerful performance, deep learning is becoming more and more popular in related applications, such as lesion segmentation, biomarkers segmentation, disease diagnosis and image synthesis. Therefore, it is very necessary to summarize the recent developments in deep learning for fundus images with a review paper. In this review, we introduce 143 application papers with a carefully designed hierarchy. Moreover, 33 publicly available datasets are presented. Summaries and analyses are provided for each task. Finally, limitations common to all tasks are revealed and possible solutions are given. We will also release and regularly update the state-of-the-art results and newly-released datasets at https://github.com/nkicsl/Fundus Review to adapt to the rapid development of this field.