 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA benchmark for video-based laparoscopic skill analysis and assessment
Feb 10, 2026Laparoscopic surgery is a complex surgical technique that requires extensive training. Recent advances in deep learning have shown promise in supporting this training by enabling automatic video-based assessment of surgical skills. However, the development and evaluation of deep learning models is currently hindered by the limited size of available annotated datasets. To address this gap, we introduce the Laparoscopic Skill Analysis and Assessment (LASANA) dataset, comprising 1270 stereo video recordings of four basic laparoscopic training tasks. Each recording is annotated with a structured skill rating, aggregated from three independent raters, as well as binary labels indicating the presence or absence of task-specific errors. The majority of recordings originate from a laparoscopic training course, thereby reflecting a natural variation in the skill of participants. To facilitate benchmarking of both existing and novel approaches for video-based skill assessment and error recognition, we provide predefined data splits for each task. Furthermore, we present baseline results from a deep learning model as a reference point for future comparisons.
One model to use them all: Training a segmentation model with complementary datasets
Feb 29, 2024Understanding a surgical scene is crucial for computer-assisted surgery systems to provide any intelligent assistance functionality. One way of achieving this scene understanding is via scene segmentation, where every pixel of a frame is classified and therefore identifies the visible structures and tissues. Progress on fully segmenting surgical scenes has been made using machine learning. However, such models require large amounts of annotated training data, containing examples of all relevant object classes. Such fully annotated datasets are hard to create, as every pixel in a frame needs to be annotated by medical experts and, therefore, are rarely available. In this work, we propose a method to combine multiple partially annotated datasets, which provide complementary annotations, into one model, enabling better scene segmentation and the use of multiple readily available datasets. Our method aims to combine available data with complementary labels by leveraging mutual exclusive properties to maximize information. Specifically, we propose to use positive annotations of other classes as negative samples and to exclude background pixels of binary annotations, as we cannot tell if they contain a class not annotated but predicted by the model. We evaluate our method by training a DeepLabV3 on the publicly available Dresden Surgical Anatomy Dataset, which provides multiple subsets of binary segmented anatomical structures. Our approach successfully combines 6 classes into one model, increasing the overall Dice Score by 4.4% compared to an ensemble of models trained on the classes individually. By including information on multiple classes, we were able to reduce confusion between stomach and colon by 24%. Our results demonstrate the feasibility of training a model on multiple datasets. This paves the way for future work further alleviating the need for one large, fully segmented datasets.
Exploring Semantic Consistency in Unpaired Image Translation to Generate Data for Surgical Applications
Sep 11, 2023In surgical computer vision applications, obtaining labeled training data is challenging due to data-privacy concerns and the need for expert annotation. Unpaired image-to-image translation techniques have been explored to automatically generate large annotated datasets by translating synthetic images to the realistic domain. However, preserving the structure and semantic consistency between the input and translated images presents significant challenges, mainly when there is a distributional mismatch in the semantic characteristics of the domains. This study empirically investigates unpaired image translation methods for generating suitable data in surgical applications, explicitly focusing on semantic consistency. We extensively evaluate various state-of-the-art image translation models on two challenging surgical datasets and downstream semantic segmentation tasks. We find that a simple combination of structural-similarity loss and contrastive learning yields the most promising results. Quantitatively, we show that the data generated with this approach yields higher semantic consistency and can be used more effectively as training data.
Long-Term Temporally Consistent Unpaired Video Translation from Simulated Surgical 3D Data
Mar 31, 2021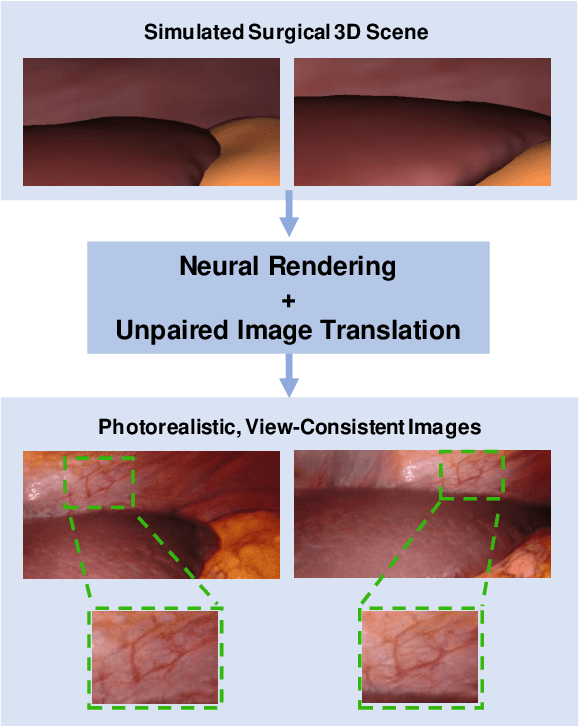
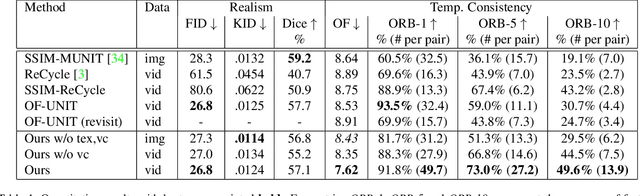
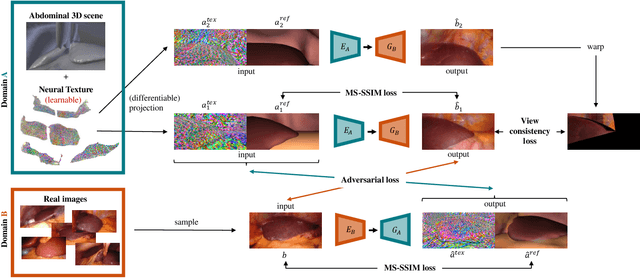
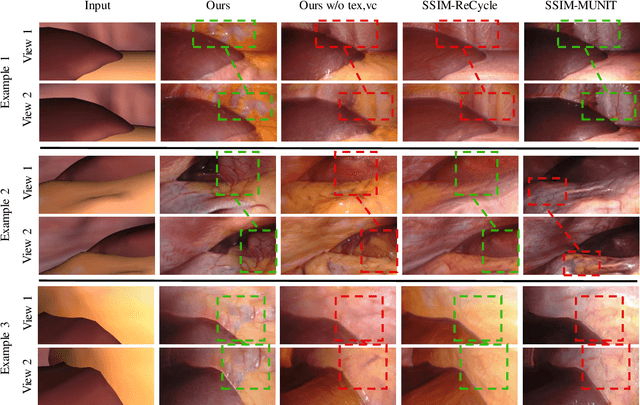
Research in unpaired video translation has mainly focused on short-term temporal consistency by conditioning on neighboring frames. However for transfer from simulated to photorealistic sequences, available information on the underlying geometry offers potential for achieving global consistency across views. We propose a novel approach which combines unpaired image translation with neural rendering to transfer simulated to photorealistic surgical abdominal scenes. By introducing global learnable textures and a lighting-invariant view-consistency loss, our method produces consistent translations of arbitrary views and thus enables long-term consistent video synthesis. We design and test our model to generate video sequences from minimally-invasive surgical abdominal scenes. Because labeled data is often limited in this domain, photorealistic data where ground truth information from the simulated domain is preserved is especially relevant. By extending existing image-based methods to view-consistent videos, we aim to impact the applicability of simulated training and evaluation environments for surgical applications. Code and data will be made publicly available soon.
Rethinking Anticipation Tasks: Uncertainty-aware Anticipation of Sparse Surgical Instrument Usage for Context-aware Assistance
Jul 16, 2020
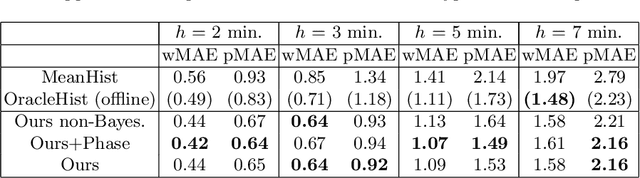
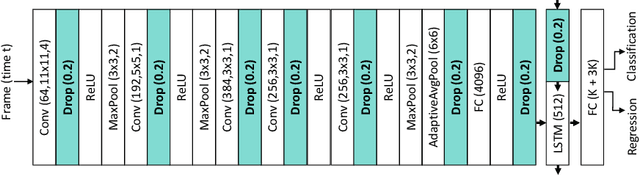
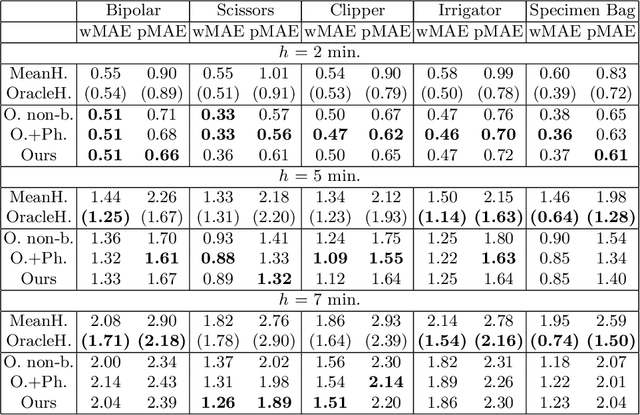
Intra-operative anticipation of instrument usage is a necessary component for context-aware assistance in surgery, e.g. for instrument preparation or semi-automation of robotic tasks. However, the sparsity of instrument occurrences in long videos poses a challenge. Current approaches are limited as they assume knowledge on the timing of future actions or require dense temporal segmentations during training and inference. We propose a novel learning task for anticipation of instrument usage in laparoscopic videos that overcomes these limitations. During training, only sparse instrument annotations are required and inference is done solely on image data. We train a probabilistic model to address the uncertainty associated with future events. Our approach outperforms several baselines and is competitive to a variant using richer annotations. We demonstrate the model's ability to quantify task-relevant uncertainties. To the best of our knowledge, we are the first to propose a method for anticipating instruments in surgery.
Non-Rigid Volume to Surface Registration using a Data-Driven Biomechanical Model
May 29, 2020

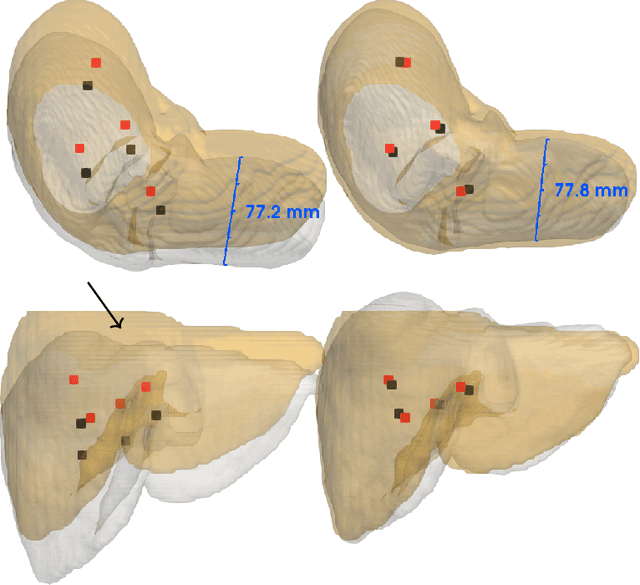
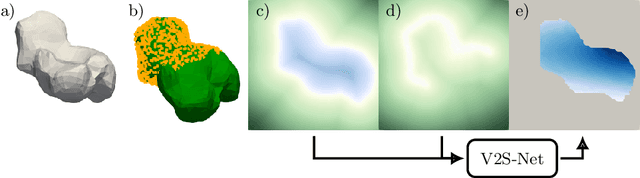
Non-rigid registration is a key component in soft-tissue navigation. We focus on laparoscopic liver surgery, where we register the organ model obtained from a preoperative CT scan to the intraoperative partial organ surface, reconstructed from the laparoscopic video. This is a challenging task due to sparse and noisy intraoperative data, real-time requirements and many unknowns - such as tissue properties and boundary conditions. Furthermore, establishing correspondences between pre- and intraoperative data can be extremely difficult since the liver usually lacks distinct surface features and the used imaging modalities suffer from very different types of noise. In this work, we train a convolutional neural network to perform both the search for surface correspondences as well as the non-rigid registration in one step. The network is trained on physically accurate biomechanical simulations of randomly generated, deforming organ-like structures. This enables the network to immediately generalize to a new patient organ without the need to re-train. We add various amounts of noise to the intraoperative surfaces during training, making the network robust to noisy intraoperative data. During inference, the network outputs the displacement field which matches the preoperative volume to the partial intraoperative surface. In multiple experiments, we show that the network translates well to real data while maintaining a high inference speed. Our code is made available online.
Unsupervised Temporal Video Segmentation as an Auxiliary Task for Predicting the Remaining Surgery Duration
Feb 26, 2020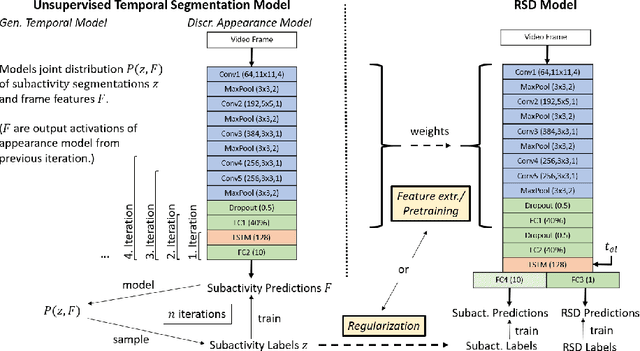
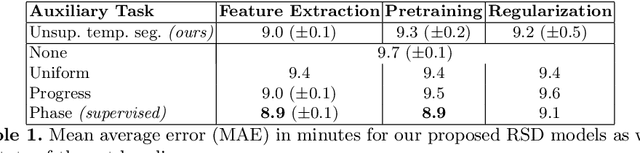

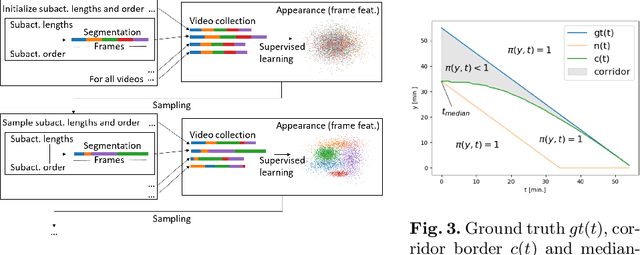
Estimating the remaining surgery duration (RSD) during surgical procedures can be useful for OR planning and anesthesia dose estimation. With the recent success of deep learning-based methods in computer vision, several neural network approaches have been proposed for fully automatic RSD prediction based solely on visual data from the endoscopic camera. We investigate whether RSD prediction can be improved using unsupervised temporal video segmentation as an auxiliary learning task. As opposed to previous work, which presented supervised surgical phase recognition as auxiliary task, we avoid the need for manual annotations by proposing a similar but unsupervised learning objective which clusters video sequences into temporally coherent segments. In multiple experimental setups, results obtained by learning the auxiliary task are incorporated into a deep RSD model through feature extraction, pretraining or regularization. Further, we propose a novel loss function for RSD training which attempts to counteract unfavorable characteristics of the RSD ground truth. Using our unsupervised method as an auxiliary task for RSD training, we outperform other self-supervised methods and are comparable to the supervised state-of-the-art. Combined with the novel RSD loss, we slightly outperform the supervised approach.
Using 3D Convolutional Neural Networks to Learn Spatiotemporal Features for Automatic Surgical Gesture Recognition in Video
Jul 26, 2019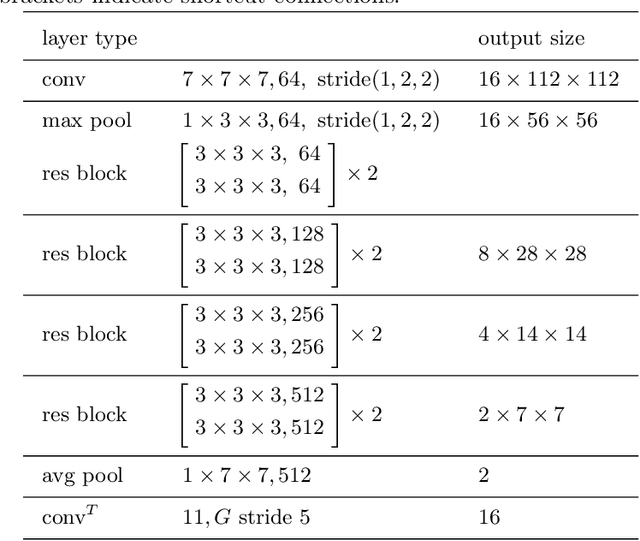


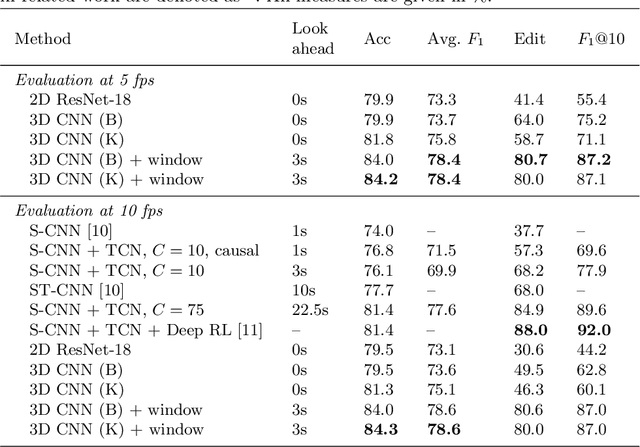
Automatically recognizing surgical gestures is a crucial step towards a thorough understanding of surgical skill. Possible areas of application include automatic skill assessment, intra-operative monitoring of critical surgical steps, and semi-automation of surgical tasks. Solutions that rely only on the laparoscopic video and do not require additional sensor hardware are especially attractive as they can be implemented at low cost in many scenarios. However, surgical gesture recognition based only on video is a challenging problem that requires effective means to extract both visual and temporal information from the video. Previous approaches mainly rely on frame-wise feature extractors, either handcrafted or learned, which fail to capture the dynamics in surgical video. To address this issue, we propose to use a 3D Convolutional Neural Network (CNN) to learn spatiotemporal features from consecutive video frames. We evaluate our approach on recordings of robot-assisted suturing on a bench-top model, which are taken from the publicly available JIGSAWS dataset. Our approach achieves high frame-wise surgical gesture recognition accuracies of more than 84%, outperforming comparable models that either extract only spatial features or model spatial and low-level temporal information separately. For the first time, these results demonstrate the benefit of spatiotemporal CNNs for video-based surgical gesture recognition.
Generating large labeled data sets for laparoscopic image processing tasks using unpaired image-to-image translation
Jul 05, 2019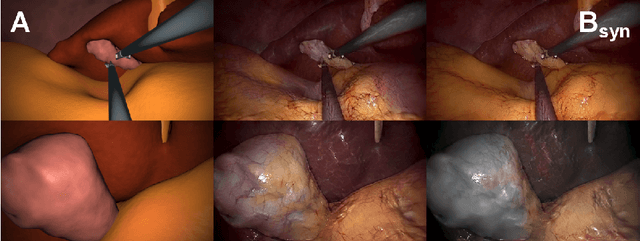
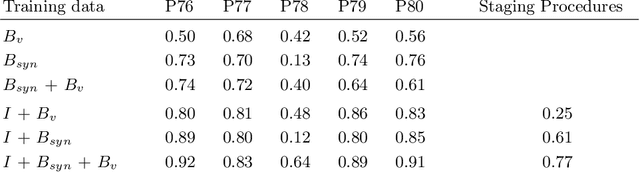
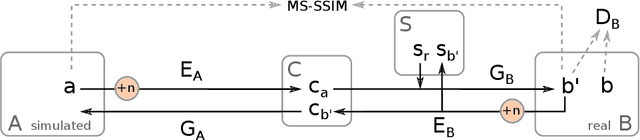
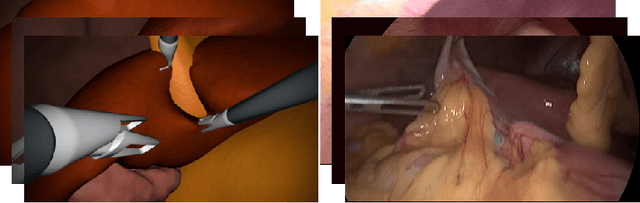
In the medical domain, the lack of large training data sets and benchmarks is often a limiting factor for training deep neural networks. In contrast to expensive manual labeling, computer simulations can generate large and fully labeled data sets with a minimum of manual effort. However, models that are trained on simulated data usually do not translate well to real scenarios. To bridge the domain gap between simulated and real laparoscopic images, we exploit recent advances in unpaired image-to-image translation. We extent an image-to-image translation method to generate a diverse multitude of realistically looking synthetic images based on images from a simple laparoscopy simulation. By incorporating means to ensure that the image content is preserved during the translation process, we ensure that the labels given for the simulated images remain valid for their realistically looking translations. This way, we are able to generate a large, fully labeled synthetic data set of laparoscopic images with realistic appearance. We show that this data set can be used to train models for the task of liver segmentation of laparoscopic images. We achieve average dice scores of up to 0.89 in some patients without manually labeling a single laparoscopic image and show that using our synthetic data to pre-train models can greatly improve their performance. The synthetic data set will be made publicly available, fully labeled with segmentation maps, depth maps, normal maps, and positions of tools and camera (http://opencas.dkfz.de/image2image).
Video-based surgical skill assessment using 3D convolutional neural networks
Mar 06, 2019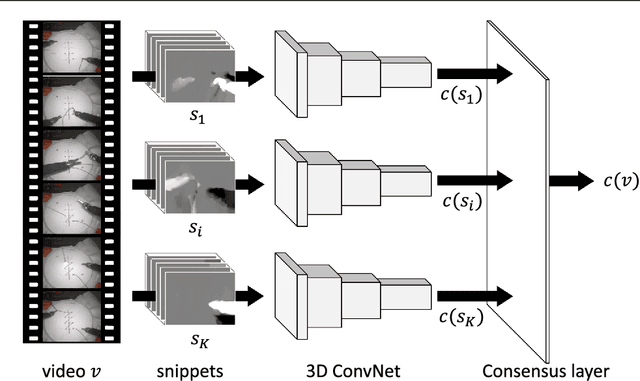
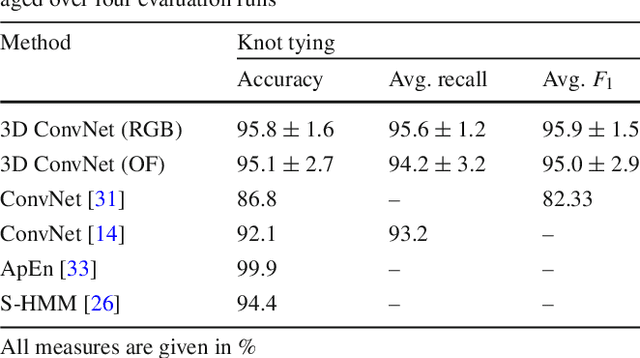

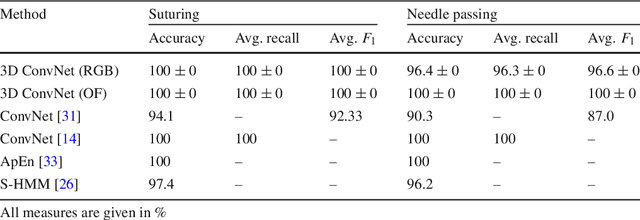
Purpose: A profound education of novice surgeons is crucial to ensure that surgical interventions are effective and safe. One important aspect is the teaching of technical skills for minimally invasive or robot-assisted procedures. This includes the objective and preferably automatic assessment of surgical skill. Recent studies presented good results for automatic, objective skill evaluation by collecting and analyzing motion data such as trajectories of surgical instruments. However, obtaining the motion data generally requires additional equipment for instrument tracking or the availability of a robotic surgery system to capture kinematic data. In contrast, we investigate a method for automatic, objective skill assessment that requires video data only. This has the advantage that video can be collected effortlessly during minimally invasive and robot-assisted training scenarios. Methods: Our method builds on recent advances in deep learning-based video classification. Specifically, we propose to use an inflated 3D ConvNet to classify snippets of optical flow extracted from surgical video. The network is extended into a Temporal Segment Network during training. Results: On the publicly available JIGSAWS dataset, our approach achieves high skill classification accuracies ranging from 95.1% to 100.0%. Conclusions: Our results demonstrate the feasibility of deep learning-based assessment of technical skill from surgical video. The 3D ConvNet is able to learn meaningful patterns directly from the data, alleviating the need for manual feature engineering. Further evaluation will require more annotated data for training and testing.