 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperationalizing Pluralistic Values in Large Language Model Alignment Reveals Trade-offs in Safety, Inclusivity, and Model Behavior
Nov 18, 2025Although large language models (LLMs) are increasingly trained using human feedback for safety and alignment with human values, alignment decisions often overlook human social diversity. This study examines how incorporating pluralistic values affects LLM behavior by systematically evaluating demographic variation and design parameters in the alignment pipeline. We collected alignment data from US and German participants (N = 1,095, 27,375 ratings) who rated LLM responses across five dimensions: Toxicity, Emotional Awareness (EA), Sensitivity, Stereotypical Bias, and Helpfulness. We fine-tuned multiple Large Language Models and Large Reasoning Models using preferences from different social groups while varying rating scales, disagreement handling methods, and optimization techniques. The results revealed systematic demographic effects: male participants rated responses 18% less toxic than female participants; conservative and Black participants rated responses 27.9% and 44% more emotionally aware than liberal and White participants, respectively. Models fine-tuned on group-specific preferences exhibited distinct behaviors. Technical design choices showed strong effects: the preservation of rater disagreement achieved roughly 53% greater toxicity reduction than majority voting, and 5-point scales yielded about 22% more reduction than binary formats; and Direct Preference Optimization (DPO) consistently outperformed Group Relative Policy Optimization (GRPO) in multi-value optimization. These findings represent a preliminary step in answering a critical question: How should alignment balance expert-driven and user-driven signals to ensure both safety and fair representation?
Addressing Pitfalls in Auditing Practices of Automatic Speech Recognition Technologies: A Case Study of People with Aphasia
Jun 10, 2025



Automatic Speech Recognition (ASR) has transformed daily tasks from video transcription to workplace hiring. ASR systems' growing use warrants robust and standardized auditing approaches to ensure automated transcriptions of high and equitable quality. This is especially critical for people with speech and language disorders (such as aphasia) who may disproportionately depend on ASR systems to navigate everyday life. In this work, we identify three pitfalls in existing standard ASR auditing procedures, and demonstrate how addressing them impacts audit results via a case study of six popular ASR systems' performance for aphasia speakers. First, audits often adhere to a single method of text standardization during data pre-processing, which (a) masks variability in ASR performance from applying different standardization methods, and (b) may not be consistent with how users - especially those from marginalized speech communities - would want their transcriptions to be standardized. Second, audits often display high-level demographic findings without further considering performance disparities among (a) more nuanced demographic subgroups, and (b) relevant covariates capturing acoustic information from the input audio. Third, audits often rely on a single gold-standard metric -- the Word Error Rate -- which does not fully capture the extent of errors arising from generative AI models, such as transcription hallucinations. We propose a more holistic auditing framework that accounts for these three pitfalls, and exemplify its results in our case study, finding consistently worse ASR performance for aphasia speakers relative to a control group. We call on practitioners to implement these robust ASR auditing practices that remain flexible to the rapidly changing ASR landscape.
Characterizing Bias: Benchmarking Large Language Models in Simplified versus Traditional Chinese
May 28, 2025



While the capabilities of Large Language Models (LLMs) have been studied in both Simplified and Traditional Chinese, it is yet unclear whether LLMs exhibit differential performance when prompted in these two variants of written Chinese. This understanding is critical, as disparities in the quality of LLM responses can perpetuate representational harms by ignoring the different cultural contexts underlying Simplified versus Traditional Chinese, and can exacerbate downstream harms in LLM-facilitated decision-making in domains such as education or hiring. To investigate potential LLM performance disparities, we design two benchmark tasks that reflect real-world scenarios: regional term choice (prompting the LLM to name a described item which is referred to differently in Mainland China and Taiwan), and regional name choice (prompting the LLM to choose who to hire from a list of names in both Simplified and Traditional Chinese). For both tasks, we audit the performance of 11 leading commercial LLM services and open-sourced models -- spanning those primarily trained on English, Simplified Chinese, or Traditional Chinese. Our analyses indicate that biases in LLM responses are dependent on both the task and prompting language: while most LLMs disproportionately favored Simplified Chinese responses in the regional term choice task, they surprisingly favored Traditional Chinese names in the regional name choice task. We find that these disparities may arise from differences in training data representation, written character preferences, and tokenization of Simplified and Traditional Chinese. These findings highlight the need for further analysis of LLM biases; as such, we provide an open-sourced benchmark dataset to foster reproducible evaluations of future LLM behavior across Chinese language variants (https://github.com/brucelyu17/SC-TC-Bench).
Fairness Practices in Industry: A Case Study in Machine Learning Teams Building Recommender Systems
May 26, 2025The rapid proliferation of recommender systems necessitates robust fairness practices to address inherent biases. Assessing fairness, though, is challenging due to constantly evolving metrics and best practices. This paper analyzes how industry practitioners perceive and incorporate these changing fairness standards in their workflows. Through semi-structured interviews with 11 practitioners from technical teams across a range of large technology companies, we investigate industry implementations of fairness in recommendation system products. We focus on current debiasing practices, applied metrics, collaborative strategies, and integrating academic research into practice. Findings show a preference for multi-dimensional debiasing over traditional demographic methods, and a reliance on intuitive rather than academic metrics. This study also highlights the difficulties in balancing fairness with both the practitioner's individual (bottom-up) roles and organizational (top-down) workplace constraints, including the interplay with legal and compliance experts. Finally, we offer actionable recommendations for the recommender system community and algorithmic fairness practitioners, underlining the need to refine fairness practices continually.
Tasks and Roles in Legal AI: Data Curation, Annotation, and Verification
Apr 02, 2025The application of AI tools to the legal field feels natural: large legal document collections could be used with specialized AI to improve workflow efficiency for lawyers and ameliorate the "justice gap" for underserved clients. However, legal documents differ from the web-based text that underlies most AI systems. The challenges of legal AI are both specific to the legal domain, and confounded with the expectation of AI's high performance in high-stakes settings. We identify three areas of special relevance to practitioners: data curation, data annotation, and output verification. First, it is difficult to obtain usable legal texts. Legal collections are inconsistent, analog, and scattered for reasons technical, economic, and jurisdictional. AI tools can assist document curation efforts, but the lack of existing data also limits AI performance. Second, legal data annotation typically requires significant expertise to identify complex phenomena such as modes of judicial reasoning or controlling precedents. We describe case studies of AI systems that have been developed to improve the efficiency of human annotation in legal contexts and identify areas of underperformance. Finally, AI-supported work in the law is valuable only if results are verifiable and trustworthy. We describe both the abilities of AI systems to support evaluation of their outputs, as well as new approaches to systematic evaluation of computational systems in complex domains. We call on both legal and AI practitioners to collaborate across disciplines and to release open access materials to support the development of novel, high-performing, and reliable AI tools for legal applications.
Automate or Assist? The Role of Computational Models in Identifying Gendered Discourse in US Capital Trial Transcripts
Jul 17, 2024The language used by US courtroom actors in criminal trials has long been studied for biases. However, systematic studies for bias in high-stakes court trials have been difficult, due to the nuanced nature of bias and the legal expertise required. New large language models offer the possibility to automate annotation, saving time and cost. But validating these approaches requires both high quantitative performance as well as an understanding of how automated methods fit in existing workflows, and what they really offer. In this paper we present a case study of adding an automated system to a complex and high-stakes problem: identifying gender-biased language in US capital trials for women defendants. Our team of experienced death-penalty lawyers and NLP technologists pursued a three-phase study: first annotating manually, then training and evaluating computational models, and finally comparing human annotations to model predictions. Unlike many typical NLP tasks, annotating for gender bias in months-long capital trials was a complicated task that involves with many individual judgment calls. In contrast to standard arguments for automation that are based on efficiency and scalability, legal experts found the computational models most useful in challenging their personal bias in annotation and providing opportunities to refine and build consensus on rules for annotation. This suggests that seeking to replace experts with computational models is both unrealistic and undesirable. Rather, computational models offer valuable opportunities to assist the legal experts in annotation-based studies.
Careless Whisper: Speech-to-Text Hallucination Harms
Feb 12, 2024



Speech-to-text services aim to transcribe input audio as accurately as possible. They increasingly play a role in everyday life, for example in personal voice assistants or in customer-company interactions. We evaluate Open AI's Whisper, a state-of-the-art service outperforming industry competitors. While many of Whisper's transcriptions were highly accurate, we found that roughly 1% of audio transcriptions contained entire hallucinated phrases or sentences, which did not exist in any form in the underlying audio. We thematically analyze the Whisper-hallucinated content, finding that 38% of hallucinations include explicit harms such as violence, made up personal information, or false video-based authority. We further provide hypotheses on why hallucinations occur, uncovering potential disparities due to speech type by health status. We call on industry practitioners to ameliorate these language-model-based hallucinations in Whisper, and to raise awareness of potential biases in downstream applications of speech-to-text models.
Should I Stop or Should I Go: Early Stopping with Heterogeneous Populations
Jun 26, 2023Randomized experiments often need to be stopped prematurely due to the treatment having an unintended harmful effect. Existing methods that determine when to stop an experiment early are typically applied to the data in aggregate and do not account for treatment effect heterogeneity. In this paper, we study the early stopping of experiments for harm on heterogeneous populations. We first establish that current methods often fail to stop experiments when the treatment harms a minority group of participants. We then use causal machine learning to develop CLASH, the first broadly-applicable method for heterogeneous early stopping. We demonstrate CLASH's performance on simulated and real data and show that it yields effective early stopping for both clinical trials and A/B tests.
Auditing Cross-Cultural Consistency of Human-Annotated Labels for Recommendation Systems
May 10, 2023



Recommendation systems increasingly depend on massive human-labeled datasets; however, the human annotators hired to generate these labels increasingly come from homogeneous backgrounds. This poses an issue when downstream predictive models -- based on these labels -- are applied globally to a heterogeneous set of users. We study this disconnect with respect to the labels themselves, asking whether they are ``consistently conceptualized'' across annotators of different demographics. In a case study of video game labels, we conduct a survey on 5,174 gamers, identify a subset of inconsistently conceptualized game labels, perform causal analyses, and suggest both cultural and linguistic reasons for cross-country differences in label annotation. We further demonstrate that predictive models of game annotations perform better on global train sets as opposed to homogeneous (single-country) train sets. Finally, we provide a generalizable framework for practitioners to audit their own data annotation processes for consistent label conceptualization, and encourage practitioners to consider global inclusivity in recommendation systems starting from the early stages of annotator recruitment and data-labeling.
Trucks Don't Mean Trump: Diagnosing Human Error in Image Analysis
May 15, 2022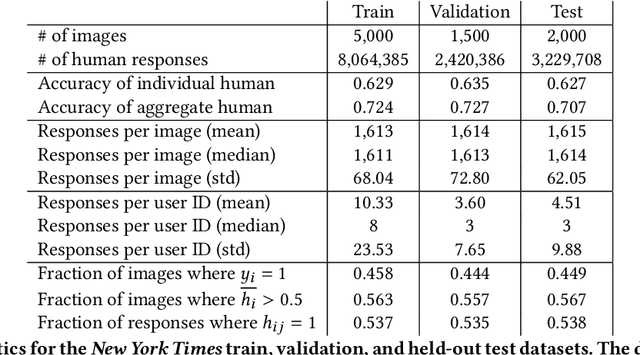
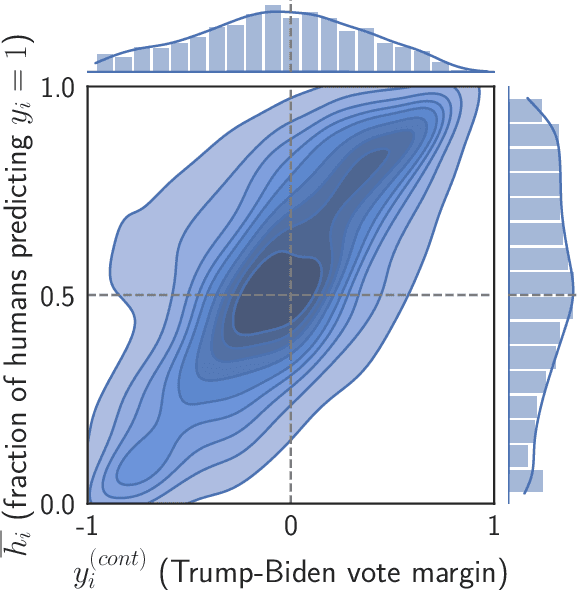
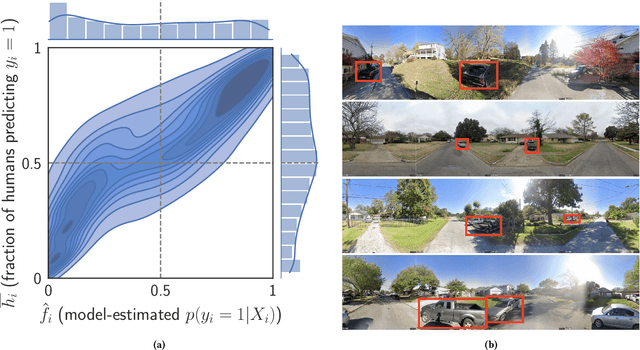
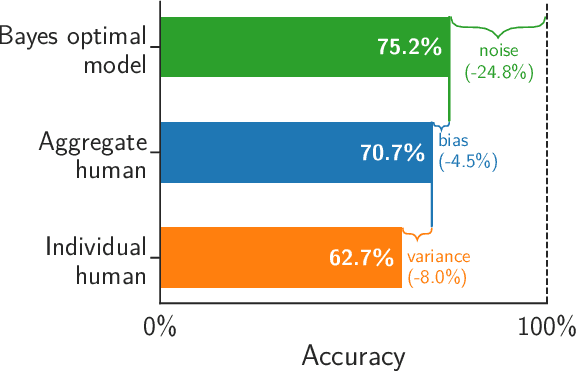
Algorithms provide powerful tools for detecting and dissecting human bias and error. Here, we develop machine learning methods to to analyze how humans err in a particular high-stakes task: image interpretation. We leverage a unique dataset of 16,135,392 human predictions of whether a neighborhood voted for Donald Trump or Joe Biden in the 2020 US election, based on a Google Street View image. We show that by training a machine learning estimator of the Bayes optimal decision for each image, we can provide an actionable decomposition of human error into bias, variance, and noise terms, and further identify specific features (like pickup trucks) which lead humans astray. Our methods can be applied to ensure that human-in-the-loop decision-making is accurate and fair and are also applicable to black-box algorithmic systems.