 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Good and The Bad: Exploring Privacy Issues in Retrieval-Augmented Generation
Feb 23, 2024



Retrieval-augmented generation (RAG) is a powerful technique to facilitate language model with proprietary and private data, where data privacy is a pivotal concern. Whereas extensive research has demonstrated the privacy risks of large language models (LLMs), the RAG technique could potentially reshape the inherent behaviors of LLM generation, posing new privacy issues that are currently under-explored. In this work, we conduct extensive empirical studies with novel attack methods, which demonstrate the vulnerability of RAG systems on leaking the private retrieval database. Despite the new risk brought by RAG on the retrieval data, we further reveal that RAG can mitigate the leakage of the LLMs' training data. Overall, we provide new insights in this paper for privacy protection of retrieval-augmented LLMs, which benefit both LLMs and RAG systems builders. Our code is available at https://github.com/phycholosogy/RAG-privacy.
Copyright Protection in Generative AI: A Technical Perspective
Feb 04, 2024



Generative AI has witnessed rapid advancement in recent years, expanding their capabilities to create synthesized content such as text, images, audio, and code. The high fidelity and authenticity of contents generated by these Deep Generative Models (DGMs) have sparked significant copyright concerns. There have been various legal debates on how to effectively safeguard copyrights in DGMs. This work delves into this issue by providing a comprehensive overview of copyright protection from a technical perspective. We examine from two distinct viewpoints: the copyrights pertaining to the source data held by the data owners and those of the generative models maintained by the model builders. For data copyright, we delve into methods data owners can protect their content and DGMs can be utilized without infringing upon these rights. For model copyright, our discussion extends to strategies for preventing model theft and identifying outputs generated by specific models. Finally, we highlight the limitations of existing techniques and identify areas that remain unexplored. Furthermore, we discuss prospective directions for the future of copyright protection, underscoring its importance for the sustainable and ethical development of Generative AI.
A Scalable Network-Aware Multi-Agent Reinforcement Learning Framework for Decentralized Inverter-based Voltage Control
Dec 07, 2023This paper addresses the challenges associated with decentralized voltage control in power grids due to an increase in distributed generations (DGs). Traditional model-based voltage control methods struggle with the rapid energy fluctuations and uncertainties of these DGs. While multi-agent reinforcement learning (MARL) has shown potential for decentralized secondary control, scalability issues arise when dealing with a large number of DGs. This problem lies in the dominant centralized training and decentralized execution (CTDE) framework, where the critics take global observations and actions. To overcome these challenges, we propose a scalable network-aware (SNA) framework that leverages network structure to truncate the input to the critic's Q-function, thereby improving scalability and reducing communication costs during training. Further, the SNA framework is theoretically grounded with provable approximation guarantee, and it can seamlessly integrate with multiple multi-agent actor-critic algorithms. The proposed SNA framework is successfully demonstrated in a system with 114 DGs, providing a promising solution for decentralized voltage control in increasingly complex power grid systems.
Exploring Memorization in Fine-tuned Language Models
Oct 10, 2023



LLMs have shown great capabilities in various tasks but also exhibited memorization of training data, thus raising tremendous privacy and copyright concerns. While prior work has studied memorization during pre-training, the exploration of memorization during fine-tuning is rather limited. Compared with pre-training, fine-tuning typically involves sensitive data and diverse objectives, thus may bring unique memorization behaviors and distinct privacy risks. In this work, we conduct the first comprehensive analysis to explore LMs' memorization during fine-tuning across tasks. Our studies with open-sourced and our own fine-tuned LMs across various tasks indicate that fine-tuned memorization presents a strong disparity among tasks. We provide an understanding of this task disparity via sparse coding theory and unveil a strong correlation between memorization and attention score distribution. By investigating its memorization behavior, multi-task fine-tuning paves a potential strategy to mitigate fine-tuned memorization.
FT-Shield: A Watermark Against Unauthorized Fine-tuning in Text-to-Image Diffusion Models
Oct 03, 2023



Text-to-image generative models based on latent diffusion models (LDM) have demonstrated their outstanding ability in generating high-quality and high-resolution images according to language prompt. Based on these powerful latent diffusion models, various fine-tuning methods have been proposed to achieve the personalization of text-to-image diffusion models such as artistic style adaptation and human face transfer. However, the unauthorized usage of data for model personalization has emerged as a prevalent concern in relation to copyright violations. For example, a malicious user may use the fine-tuning technique to generate images which mimic the style of a painter without his/her permission. In light of this concern, we have proposed FT-Shield, a watermarking approach specifically designed for the fine-tuning of text-to-image diffusion models to aid in detecting instances of infringement. We develop a novel algorithm for the generation of the watermark to ensure that the watermark on the training images can be quickly and accurately transferred to the generated images of text-to-image diffusion models. A watermark will be detected on an image by a binary watermark detector if the image is generated by a model that has been fine-tuned using the protected watermarked images. Comprehensive experiments were conducted to validate the effectiveness of FT-Shield.
On the Generalization of Training-based ChatGPT Detection Methods
Oct 03, 2023ChatGPT is one of the most popular language models which achieve amazing performance on various natural language tasks. Consequently, there is also an urgent need to detect the texts generated ChatGPT from human written. One of the extensively studied methods trains classification models to distinguish both. However, existing studies also demonstrate that the trained models may suffer from distribution shifts (during test), i.e., they are ineffective to predict the generated texts from unseen language tasks or topics. In this work, we aim to have a comprehensive investigation on these methods' generalization behaviors under distribution shift caused by a wide range of factors, including prompts, text lengths, topics, and language tasks. To achieve this goal, we first collect a new dataset with human and ChatGPT texts, and then we conduct extensive studies on the collected dataset. Our studies unveil insightful findings which provide guidance for developing future methodologies or data collection strategies for ChatGPT detection.
Diff-Retinex: Rethinking Low-light Image Enhancement with A Generative Diffusion Model
Aug 25, 2023In this paper, we rethink the low-light image enhancement task and propose a physically explainable and generative diffusion model for low-light image enhancement, termed as Diff-Retinex. We aim to integrate the advantages of the physical model and the generative network. Furthermore, we hope to supplement and even deduce the information missing in the low-light image through the generative network. Therefore, Diff-Retinex formulates the low-light image enhancement problem into Retinex decomposition and conditional image generation. In the Retinex decomposition, we integrate the superiority of attention in Transformer and meticulously design a Retinex Transformer decomposition network (TDN) to decompose the image into illumination and reflectance maps. Then, we design multi-path generative diffusion networks to reconstruct the normal-light Retinex probability distribution and solve the various degradations in these components respectively, including dark illumination, noise, color deviation, loss of scene contents, etc. Owing to generative diffusion model, Diff-Retinex puts the restoration of low-light subtle detail into practice. Extensive experiments conducted on real-world low-light datasets qualitatively and quantitatively demonstrate the effectiveness, superiority, and generalization of the proposed method.
Transferable Unlearnable Examples
Oct 18, 2022
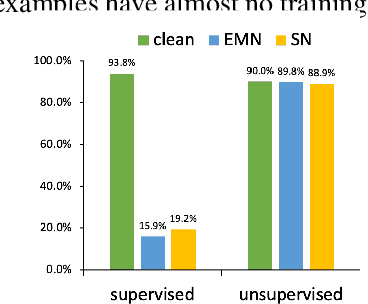


With more people publishing their personal data online, unauthorized data usage has become a serious concern. The unlearnable strategies have been introduced to prevent third parties from training on the data without permission. They add perturbations to the users' data before publishing, which aims to make the models trained on the perturbed published dataset invalidated. These perturbations have been generated for a specific training setting and a target dataset. However, their unlearnable effects significantly decrease when used in other training settings and datasets. To tackle this issue, we propose a novel unlearnable strategy based on Classwise Separability Discriminant (CSD), which aims to better transfer the unlearnable effects to other training settings and datasets by enhancing the linear separability. Extensive experiments demonstrate the transferability of the proposed unlearnable examples across training settings and datasets.
Towards Fair Classification against Poisoning Attacks
Oct 18, 2022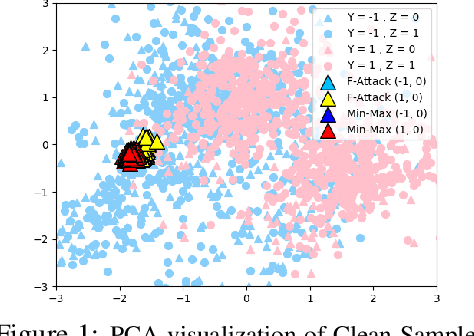

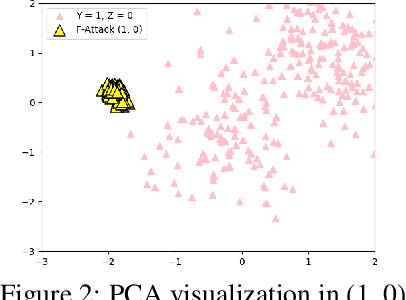
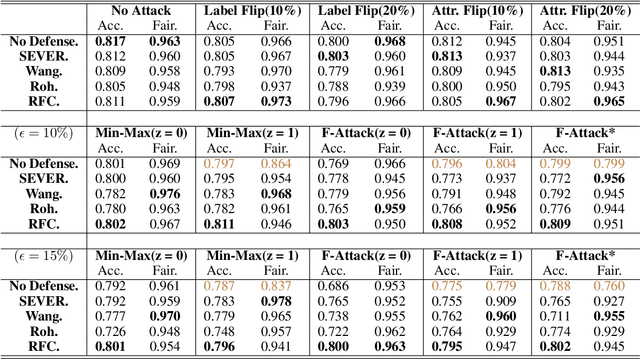
Fair classification aims to stress the classification models to achieve the equality (treatment or prediction quality) among different sensitive groups. However, fair classification can be under the risk of poisoning attacks that deliberately insert malicious training samples to manipulate the trained classifiers' performance. In this work, we study the poisoning scenario where the attacker can insert a small fraction of samples into training data, with arbitrary sensitive attributes as well as other predictive features. We demonstrate that the fairly trained classifiers can be greatly vulnerable to such poisoning attacks, with much worse accuracy & fairness trade-off, even when we apply some of the most effective defenses (originally proposed to defend traditional classification tasks). As countermeasures to defend fair classification tasks, we propose a general and theoretically guaranteed framework which accommodates traditional defense methods to fair classification against poisoning attacks. Through extensive experiments, the results validate that the proposed defense framework obtains better robustness in terms of accuracy and fairness than representative baseline methods.
Probabilistic Categorical Adversarial Attack & Adversarial Training
Oct 17, 2022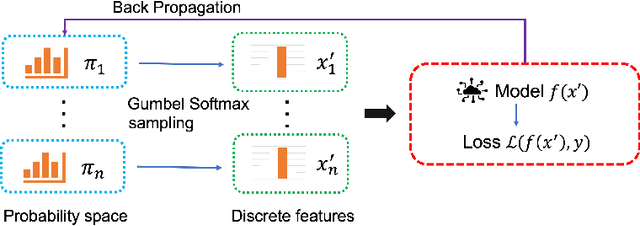
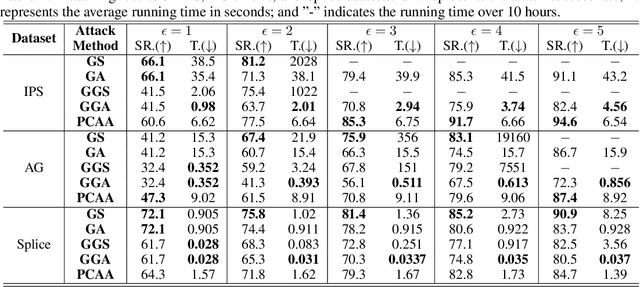
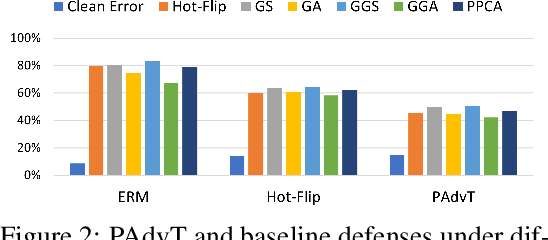

The existence of adversarial examples brings huge concern for people to apply Deep Neural Networks (DNNs) in safety-critical tasks. However, how to generate adversarial examples with categorical data is an important problem but lack of extensive exploration. Previously established methods leverage greedy search method, which can be very time-consuming to conduct successful attack. This also limits the development of adversarial training and potential defenses for categorical data. To tackle this problem, we propose Probabilistic Categorical Adversarial Attack (PCAA), which transfers the discrete optimization problem to a continuous problem that can be solved efficiently by Projected Gradient Descent. In our paper, we theoretically analyze its optimality and time complexity to demonstrate its significant advantage over current greedy based attacks. Moreover, based on our attack, we propose an efficient adversarial training framework. Through a comprehensive empirical study, we justify the effectiveness of our proposed attack and defense algorithms.