 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoX: Towards Mitigating Acoustic-Semantic Gap via Echo Training for Speech-to-Speech LLMs
Sep 11, 2025Speech-to-speech large language models (SLLMs) are attracting increasing attention. Derived from text-based large language models (LLMs), SLLMs often exhibit degradation in knowledge and reasoning capabilities. We hypothesize that this limitation arises because current training paradigms for SLLMs fail to bridge the acoustic-semantic gap in the feature representation space. To address this issue, we propose EchoX, which leverages semantic representations and dynamically generates speech training targets. This approach integrates both acoustic and semantic learning, enabling EchoX to preserve strong reasoning abilities as a speech LLM. Experimental results demonstrate that EchoX, with about six thousand hours of training data, achieves advanced performance on multiple knowledge-based question-answering benchmarks. The project is available at https://github.com/FreedomIntelligence/EchoX.
NE-PADD: Leveraging Named Entity Knowledge for Robust Partial Audio Deepfake Detection via Attention Aggregation
Sep 04, 2025



Different from traditional sentence-level audio deepfake detection (ADD), partial audio deepfake detection (PADD) requires frame-level positioning of the location of fake speech. While some progress has been made in this area, leveraging semantic information from audio, especially named entities, remains an underexplored aspect. To this end, we propose NE-PADD, a novel method for Partial Audio Deepfake Detection (PADD) that leverages named entity knowledge through two parallel branches: Speech Name Entity Recognition (SpeechNER) and PADD. The approach incorporates two attention aggregation mechanisms: Attention Fusion (AF) for combining attention weights and Attention Transfer (AT) for guiding PADD with named entity semantics using an auxiliary loss. Built on the PartialSpoof-NER dataset, experiments show our method outperforms existing baselines, proving the effectiveness of integrating named entity knowledge in PADD. The code is available at https://github.com/AI-S2-Lab/NE-PADD.
Interpolating Speaker Identities in Embedding Space for Data Expansion
Aug 26, 2025



The success of deep learning-based speaker verification systems is largely attributed to access to large-scale and diverse speaker identity data. However, collecting data from more identities is expensive, challenging, and often limited by privacy concerns. To address this limitation, we propose INSIDE (Interpolating Speaker Identities in Embedding Space), a novel data expansion method that synthesizes new speaker identities by interpolating between existing speaker embeddings. Specifically, we select pairs of nearby speaker embeddings from a pretrained speaker embedding space and compute intermediate embeddings using spherical linear interpolation. These interpolated embeddings are then fed to a text-to-speech system to generate corresponding speech waveforms. The resulting data is combined with the original dataset to train downstream models. Experiments show that models trained with INSIDE-expanded data outperform those trained only on real data, achieving 3.06\% to 5.24\% relative improvements. While INSIDE is primarily designed for speaker verification, we also validate its effectiveness on gender classification, where it yields a 13.44\% relative improvement. Moreover, INSIDE is compatible with other augmentation techniques and can serve as a flexible, scalable addition to existing training pipelines.
ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Aug 20, 2025



Despite the success of large language models (LLMs) in various domains, their potential in Traditional Chinese Medicine (TCM) remains largely underexplored due to two critical barriers: (1) the scarcity of high-quality TCM data and (2) the inherently multimodal nature of TCM diagnostics, which involve looking, listening, smelling, and pulse-taking. These sensory-rich modalities are beyond the scope of conventional LLMs. To address these challenges, we present ShizhenGPT, the first multimodal LLM tailored for TCM. To overcome data scarcity, we curate the largest TCM dataset to date, comprising 100GB+ of text and 200GB+ of multimodal data, including 1.2M images, 200 hours of audio, and physiological signals. ShizhenGPT is pretrained and instruction-tuned to achieve deep TCM knowledge and multimodal reasoning. For evaluation, we collect recent national TCM qualification exams and build a visual benchmark for Medicinal Recognition and Visual Diagnosis. Experiments demonstrate that ShizhenGPT outperforms comparable-scale LLMs and competes with larger proprietary models. Moreover, it leads in TCM visual understanding among existing multimodal LLMs and demonstrates unified perception across modalities like sound, pulse, smell, and vision, paving the way toward holistic multimodal perception and diagnosis in TCM. Datasets, models, and code are publicly available. We hope this work will inspire further exploration in this field.
UniTalker: Conversational Speech-Visual Synthesis
Aug 06, 2025Conversational Speech Synthesis (CSS) is a key task in the user-agent interaction area, aiming to generate more expressive and empathetic speech for users. However, it is well-known that "listening" and "eye contact" play crucial roles in conveying emotions during real-world interpersonal communication. Existing CSS research is limited to perceiving only text and speech within the dialogue context, which restricts its effectiveness. Moreover, speech-only responses further constrain the interactive experience. To address these limitations, we introduce a Conversational Speech-Visual Synthesis (CSVS) task as an extension of traditional CSS. By leveraging multimodal dialogue context, it provides users with coherent audiovisual responses. To this end, we develop a CSVS system named UniTalker, which is a unified model that seamlessly integrates multimodal perception and multimodal rendering capabilities. Specifically, it leverages a large-scale language model to comprehensively understand multimodal cues in the dialogue context, including speaker, text, speech, and the talking-face animations. After that, it employs multi-task sequence prediction to first infer the target utterance's emotion and then generate empathetic speech and natural talking-face animations. To ensure that the generated speech-visual content remains consistent in terms of emotion, content, and duration, we introduce three key optimizations: 1) Designing a specialized neural landmark codec to tokenize and reconstruct facial expression sequences. 2) Proposing a bimodal speech-visual hard alignment decoding strategy. 3) Applying emotion-guided rendering during the generation stage. Comprehensive objective and subjective experiments demonstrate that our model synthesizes more empathetic speech and provides users with more natural and emotionally consistent talking-face animations.
Accent Normalization Using Self-Supervised Discrete Tokens with Non-Parallel Data
Jul 23, 2025Accent normalization converts foreign-accented speech into native-like speech while preserving speaker identity. We propose a novel pipeline using self-supervised discrete tokens and non-parallel training data. The system extracts tokens from source speech, converts them through a dedicated model, and synthesizes the output using flow matching. Our method demonstrates superior performance over a frame-to-frame baseline in naturalness, accentedness reduction, and timbre preservation across multiple English accents. Through token-level phonetic analysis, we validate the effectiveness of our token-based approach. We also develop two duration preservation methods, suitable for applications such as dubbing.
VP-SelDoA: Visual-prompted Selective DoA Estimation of Target Sound via Semantic-Spatial Matching
Jul 10, 2025Audio-visual sound source localization (AV-SSL) identifies the position of a sound source by exploiting the complementary strengths of auditory and visual signals. However, existing AV-SSL methods encounter three major challenges: 1) inability to selectively isolate the target sound source in multi-source scenarios, 2) misalignment between semantic visual features and spatial acoustic features, and 3) overreliance on paired audio-visual data. To overcome these limitations, we introduce Cross-Instance Audio-Visual Localization (CI-AVL), a novel task that leverages images from different instances of the same sound event category to localize target sound sources, thereby reducing dependence on paired data while enhancing generalization capabilities. Our proposed VP-SelDoA tackles this challenging task through a semantic-level modality fusion and employs a Frequency-Temporal ConMamba architecture to generate target-selective masks for sound isolation. We further develop a Semantic-Spatial Matching mechanism that aligns the heterogeneous semantic and spatial features via integrated cross- and self-attention mechanisms. To facilitate the CI-AVL research, we construct a large-scale dataset named VGG-SSL, comprising 13,981 spatial audio clips across 296 sound event categories. Extensive experiments show that our proposed method outperforms state-of-the-art audio-visual localization methods, achieving a mean absolute error (MAE) of 12.04 and an accuracy (ACC) of 78.23%.
IML-Spikeformer: Input-aware Multi-Level Spiking Transformer for Speech Processing
Jul 10, 2025
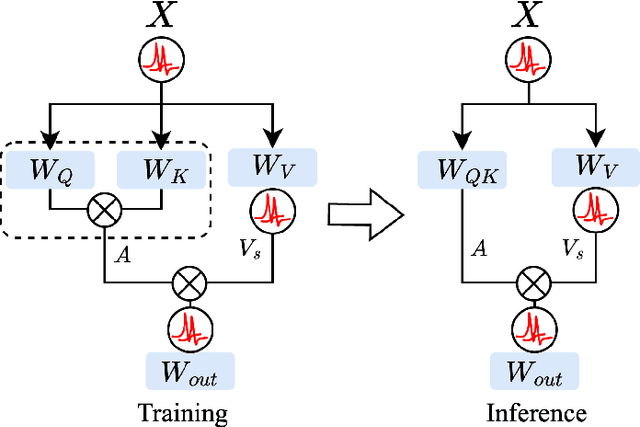


Spiking Neural Networks (SNNs), inspired by biological neural mechanisms, represent a promising neuromorphic computing paradigm that offers energy-efficient alternatives to traditional Artificial Neural Networks (ANNs). Despite proven effectiveness, SNN architectures have struggled to achieve competitive performance on large-scale speech processing task. Two key challenges hinder progress: (1) the high computational overhead during training caused by multi-timestep spike firing, and (2) the absence of large-scale SNN architectures tailored to speech processing tasks. To overcome the issues, we introduce Input-aware Multi-Level Spikeformer, i.e. IML-Spikeformer, a spiking Transformer architecture specifically designed for large-scale speech processing. Central to our design is the Input-aware Multi-Level Spike (IMLS) mechanism, which simulate multi-timestep spike firing within a single timestep using an adaptive, input-aware thresholding scheme. IML-Spikeformer further integrates a Reparameterized Spiking Self-Attention (RepSSA) module with a Hierarchical Decay Mask (HDM), forming the HD-RepSSA module. This module enhances the precision of attention maps and enables modeling of multi-scale temporal dependencies in speech signals. Experiments demonstrate that IML-Spikeformer achieves word error rates of 6.0\% on AiShell-1 and 3.4\% on Librispeech-960, comparable to conventional ANN transformers while reducing theoretical inference energy consumption by 4.64$\times$ and 4.32$\times$ respectively. IML-Spikeformer marks an advance of scalable SNN architectures for large-scale speech processing in both task performance and energy efficiency.
SpeechRefiner: Towards Perceptual Quality Refinement for Front-End Algorithms
Jun 16, 2025Speech pre-processing techniques such as denoising, de-reverberation, and separation, are commonly employed as front-ends for various downstream speech processing tasks. However, these methods can sometimes be inadequate, resulting in residual noise or the introduction of new artifacts. Such deficiencies are typically not captured by metrics like SI-SNR but are noticeable to human listeners. To address this, we introduce SpeechRefiner, a post-processing tool that utilizes Conditional Flow Matching (CFM) to improve the perceptual quality of speech. In this study, we benchmark SpeechRefiner against recent task-specific refinement methods and evaluate its performance within our internal processing pipeline, which integrates multiple front-end algorithms. Experiments show that SpeechRefiner exhibits strong generalization across diverse impairment sources, significantly enhancing speech perceptual quality. Audio demos can be found at https://speechrefiner.github.io/SpeechRefiner/.
Incorporating Linguistic Constraints from External Knowledge Source for Audio-Visual Target Speech Extraction
Jun 11, 2025Audio-visual target speaker extraction (AV-TSE) models primarily rely on target visual cues to isolate the target speaker's voice from others. We know that humans leverage linguistic knowledge, such as syntax and semantics, to support speech perception. Inspired by this, we explore the potential of pre-trained speech-language models (PSLMs) and pre-trained language models (PLMs) as auxiliary knowledge sources for AV-TSE. In this study, we propose incorporating the linguistic constraints from PSLMs or PLMs for the AV-TSE model as additional supervision signals. Without introducing any extra computational cost during inference, the proposed approach consistently improves speech quality and intelligibility. Furthermore, we evaluate our method in multi-language settings and visual cue-impaired scenarios and show robust performance gains.