 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMM-V2X: MoE-Enhanced Multi-Level Fusion for End-to-End Cooperative Autonomous Driving
Nov 12, 2025Autonomous driving holds transformative potential but remains fundamentally constrained by the limited perception and isolated decision-making with standalone intelligence. While recent multi-agent approaches introduce cooperation, they often focus merely on perception-level tasks, overlooking the alignment with downstream planning and control, or fall short in leveraging the full capacity of the recent emerging end-to-end autonomous driving. In this paper, we present UniMM-V2X, a novel end-to-end multi-agent framework that enables hierarchical cooperation across perception, prediction, and planning. At the core of our framework is a multi-level fusion strategy that unifies perception and prediction cooperation, allowing agents to share queries and reason cooperatively for consistent and safe decision-making. To adapt to diverse downstream tasks and further enhance the quality of multi-level fusion, we incorporate a Mixture-of-Experts (MoE) architecture to dynamically enhance the BEV representations. We further extend MoE into the decoder to better capture diverse motion patterns. Extensive experiments on the DAIR-V2X dataset demonstrate our approach achieves state-of-the-art (SOTA) performance with a 39.7% improvement in perception accuracy, a 7.2% reduction in prediction error, and a 33.2% improvement in planning performance compared with UniV2X, showcasing the strength of our MoE-enhanced multi-level cooperative paradigm.
Griffin: Aerial-Ground Cooperative Detection and Tracking Dataset and Benchmark
Mar 10, 2025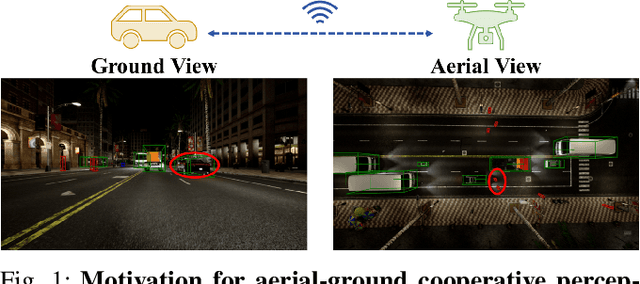

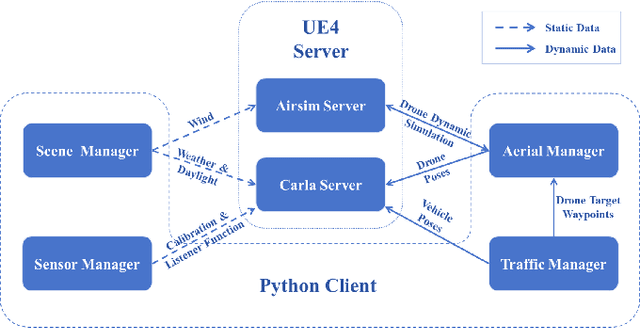

Despite significant advancements, autonomous driving systems continue to struggle with occluded objects and long-range detection due to the inherent limitations of single-perspective sensing. Aerial-ground cooperation offers a promising solution by integrating UAVs' aerial views with ground vehicles' local observations. However, progress in this emerging field has been hindered by the absence of public datasets and standardized evaluation benchmarks. To address this gap, this paper presents a comprehensive solution for aerial-ground cooperative 3D perception through three key contributions: (1) Griffin, a large-scale multi-modal dataset featuring over 200 dynamic scenes (30k+ frames) with varied UAV altitudes (20-60m), diverse weather conditions, and occlusion-aware 3D annotations, enhanced by CARLA-AirSim co-simulation for realistic UAV dynamics; (2) A unified benchmarking framework for aerial-ground cooperative detection and tracking tasks, including protocols for evaluating communication efficiency, latency tolerance, and altitude adaptability; (3) AGILE, an instance-level intermediate fusion baseline that dynamically aligns cross-view features through query-based interaction, achieving an advantageous balance between communication overhead and perception accuracy. Extensive experiments prove the effectiveness of aerial-ground cooperative perception and demonstrate the direction of further research. The dataset and codes are available at https://github.com/wang-jh18-SVM/Griffin.
LiDAR-based End-to-end Temporal Perception for Vehicle-Infrastructure Cooperation
Nov 22, 2024



Temporal perception, the ability to detect and track objects over time, is critical in autonomous driving for maintaining a comprehensive understanding of dynamic environments. However, this task is hindered by significant challenges, including incomplete perception caused by occluded objects and observational blind spots, which are common in single-vehicle perception systems. To address these issues, we introduce LET-VIC, a LiDAR-based End-to-End Tracking framework for Vehicle-Infrastructure Cooperation (VIC). LET-VIC leverages Vehicle-to-Everything (V2X) communication to enhance temporal perception by fusing spatial and temporal data from both vehicle and infrastructure sensors. First, it spatially integrates Bird's Eye View (BEV) features from vehicle-side and infrastructure-side LiDAR data, creating a comprehensive view that mitigates occlusions and compensates for blind spots. Second, LET-VIC incorporates temporal context across frames, allowing the model to leverage historical data for enhanced tracking stability and accuracy. To further improve robustness, LET-VIC includes a Calibration Error Compensation (CEC) module to address sensor misalignments and ensure precise feature alignment. Experiments on the V2X-Seq-SPD dataset demonstrate that LET-VIC significantly outperforms baseline models, achieving at least a 13.7% improvement in mAP and a 13.1% improvement in AMOTA without considering communication delays. This work offers a practical solution and a new research direction for advancing temporal perception in autonomous driving through vehicle-infrastructure cooperation.
MEDCO: Medical Education Copilots Based on A Multi-Agent Framework
Aug 22, 2024



Large language models (LLMs) have had a significant impact on diverse research domains, including medicine and healthcare. However, the potential of LLMs as copilots in medical education remains underexplored. Current AI-assisted educational tools are limited by their solitary learning approach and inability to simulate the multi-disciplinary and interactive nature of actual medical training. To address these limitations, we propose MEDCO (Medical EDucation COpilots), a novel multi-agent-based copilot system specially developed to emulate real-world medical training environments. MEDCO incorporates three primary agents: an agentic patient, an expert doctor, and a radiologist, facilitating a multi-modal and interactive learning environment. Our framework emphasizes the learning of proficient question-asking skills, multi-disciplinary collaboration, and peer discussions between students. Our experiments show that simulated virtual students who underwent training with MEDCO not only achieved substantial performance enhancements comparable to those of advanced models, but also demonstrated human-like learning behaviors and improvements, coupled with an increase in the number of learning samples. This work contributes to medical education by introducing a copilot that implements an interactive and collaborative learning approach. It also provides valuable insights into the effectiveness of AI-integrated training paradigms.
Leveraging Temporal Contexts to Enhance Vehicle-Infrastructure Cooperative Perception
Aug 20, 2024Infrastructure sensors installed at elevated positions offer a broader perception range and encounter fewer occlusions. Integrating both infrastructure and ego-vehicle data through V2X communication, known as vehicle-infrastructure cooperation, has shown considerable advantages in enhancing perception capabilities and addressing corner cases encountered in single-vehicle autonomous driving. However, cooperative perception still faces numerous challenges, including limited communication bandwidth and practical communication interruptions. In this paper, we propose CTCE, a novel framework for cooperative 3D object detection. This framework transmits queries with temporal contexts enhancement, effectively balancing transmission efficiency and performance to accommodate real-world communication conditions. Additionally, we propose a temporal-guided fusion module to further improve performance. The roadside temporal enhancement and vehicle-side spatial-temporal fusion together constitute a multi-level temporal contexts integration mechanism, fully leveraging temporal information to enhance performance. Furthermore, a motion-aware reconstruction module is introduced to recover lost roadside queries due to communication interruptions. Experimental results on V2X-Seq and V2X-Sim datasets demonstrate that CTCE outperforms the baseline QUEST, achieving improvements of 3.8% and 1.3% in mAP, respectively. Experiments under communication interruption conditions validate CTCE's robustness to communication interruptions.
End-to-End Autonomous Driving through V2X Cooperation
Mar 31, 2024



Cooperatively utilizing both ego-vehicle and infrastructure sensor data via V2X communication has emerged as a promising approach for advanced autonomous driving. However, current research mainly focuses on improving individual modules, rather than taking end-to-end learning to optimize final planning performance, resulting in underutilized data potential. In this paper, we introduce UniV2X, a pioneering cooperative autonomous driving framework that seamlessly integrates all key driving modules across diverse views into a unified network. We propose a sparse-dense hybrid data transmission and fusion mechanism for effective vehicle-infrastructure cooperation, offering three advantages: 1) Effective for simultaneously enhancing agent perception, online mapping, and occupancy prediction, ultimately improving planning performance. 2) Transmission-friendly for practical and limited communication conditions. 3) Reliable data fusion with interpretability of this hybrid data. We implement UniV2X, as well as reproducing several benchmark methods, on the challenging DAIR-V2X, the real-world cooperative driving dataset. Experimental results demonstrate the effectiveness of UniV2X in significantly enhancing planning performance, as well as all intermediate output performance. Code is at https://github.com/AIR-THU/UniV2X.
RCooper: A Real-world Large-scale Dataset for Roadside Cooperative Perception
Mar 31, 2024



The value of roadside perception, which could extend the boundaries of autonomous driving and traffic management, has gradually become more prominent and acknowledged in recent years. However, existing roadside perception approaches only focus on the single-infrastructure sensor system, which cannot realize a comprehensive understanding of a traffic area because of the limited sensing range and blind spots. Orienting high-quality roadside perception, we need Roadside Cooperative Perception (RCooper) to achieve practical area-coverage roadside perception for restricted traffic areas. Rcooper has its own domain-specific challenges, but further exploration is hindered due to the lack of datasets. We hence release the first real-world, large-scale RCooper dataset to bloom the research on practical roadside cooperative perception, including detection and tracking. The manually annotated dataset comprises 50k images and 30k point clouds, including two representative traffic scenes (i.e., intersection and corridor). The constructed benchmarks prove the effectiveness of roadside cooperation perception and demonstrate the direction of further research. Codes and dataset can be accessed at: https://github.com/AIR-THU/DAIR-RCooper.
RoboCodeX: Multimodal Code Generation for Robotic Behavior Synthesis
Feb 25, 2024



Robotic behavior synthesis, the problem of understanding multimodal inputs and generating precise physical control for robots, is an important part of Embodied AI. Despite successes in applying multimodal large language models for high-level understanding, it remains challenging to translate these conceptual understandings into detailed robotic actions while achieving generalization across various scenarios. In this paper, we propose a tree-structured multimodal code generation framework for generalized robotic behavior synthesis, termed RoboCodeX. RoboCodeX decomposes high-level human instructions into multiple object-centric manipulation units consisting of physical preferences such as affordance and safety constraints, and applies code generation to introduce generalization ability across various robotics platforms. To further enhance the capability to map conceptual and perceptual understanding into control commands, a specialized multimodal reasoning dataset is collected for pre-training and an iterative self-updating methodology is introduced for supervised fine-tuning. Extensive experiments demonstrate that RoboCodeX achieves state-of-the-art performance in both simulators and real robots on four different kinds of manipulation tasks and one navigation task.
Flow-Based Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
Nov 03, 2023Cooperatively utilizing both ego-vehicle and infrastructure sensor data can significantly enhance autonomous driving perception abilities. However, the uncertain temporal asynchrony and limited communication conditions can lead to fusion misalignment and constrain the exploitation of infrastructure data. To address these issues in vehicle-infrastructure cooperative 3D (VIC3D) object detection, we propose the Feature Flow Net (FFNet), a novel cooperative detection framework. FFNet is a flow-based feature fusion framework that uses a feature flow prediction module to predict future features and compensate for asynchrony. Instead of transmitting feature maps extracted from still-images, FFNet transmits feature flow, leveraging the temporal coherence of sequential infrastructure frames. Furthermore, we introduce a self-supervised training approach that enables FFNet to generate feature flow with feature prediction ability from raw infrastructure sequences. Experimental results demonstrate that our proposed method outperforms existing cooperative detection methods while only requiring about 1/100 of the transmission cost of raw data and covers all latency in one model on the DAIR-V2X dataset. The code is available at \href{https://github.com/haibao-yu/FFNet-VIC3D}{https://github.com/haibao-yu/FFNet-VIC3D}.
Learning Cooperative Trajectory Representations for Motion Forecasting
Nov 01, 2023



Motion forecasting is an essential task for autonomous driving, and the effective information utilization from infrastructure and other vehicles can enhance motion forecasting capabilities. Existing research have primarily focused on leveraging single-frame cooperative information to enhance the limited perception capability of the ego vehicle, while underutilizing the motion and interaction information of traffic participants observed from cooperative devices. In this paper, we first propose the cooperative trajectory representations learning paradigm. Specifically, we present V2X-Graph, the first interpretable and end-to-end learning framework for cooperative motion forecasting. V2X-Graph employs an interpretable graph to fully leverage the cooperative motion and interaction contexts. Experimental results on the vehicle-to-infrastructure (V2I) motion forecasting dataset, V2X-Seq, demonstrate the effectiveness of V2X-Graph. To further evaluate on V2X scenario, we construct the first real-world vehicle-to-everything (V2X) motion forecasting dataset V2X-Traj, and the performance shows the advantage of our method. We hope both V2X-Graph and V2X-Traj can facilitate the further development of cooperative motion forecasting. Find project at https://github.com/AIR-THU/V2X-Graph, find data at https://github.com/AIR-THU/DAIR-V2X-Seq.