 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-Guided Point Cloud Completion
Apr 13, 2021
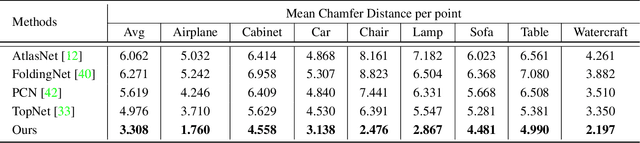
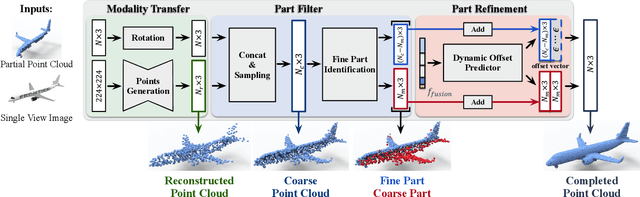
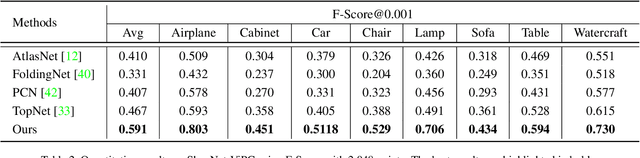
This paper presents a view-guided solution for the task of point cloud completion. Unlike most existing methods directly inferring the missing points using shape priors, we address this task by introducing ViPC (view-guided point cloud completion) that takes the missing crucial global structure information from an extra single-view image. By leveraging a framework that sequentially performs effective cross-modality and cross-level fusions, our method achieves significantly superior results over typical existing solutions on a new large-scale dataset we collect for the view-guided point cloud completion task.
Structural Similarity of Boundary Conditions and an Efficient Local Search Algorithm for Goal Conflict Identification
Feb 23, 2021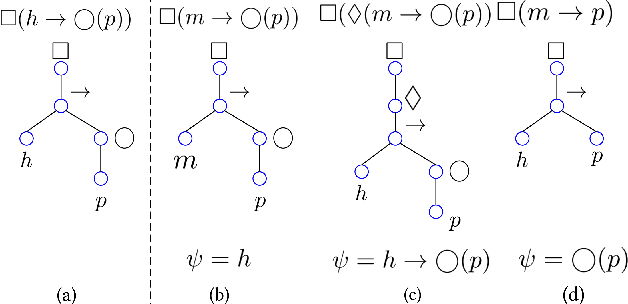
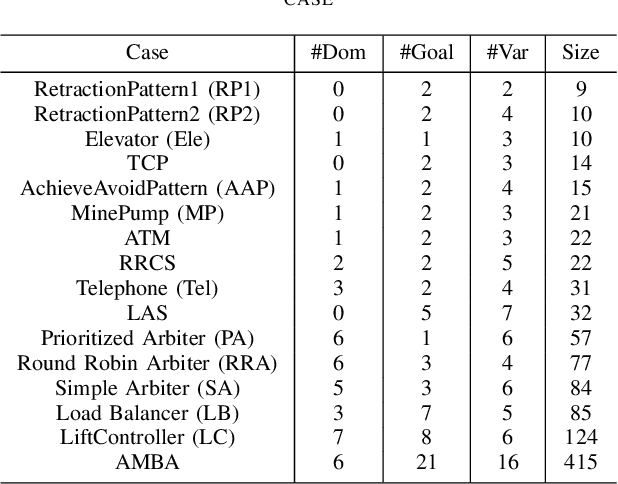
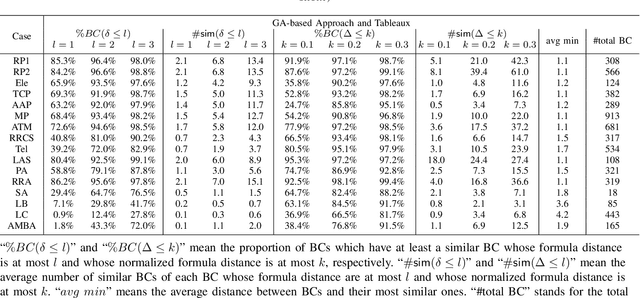
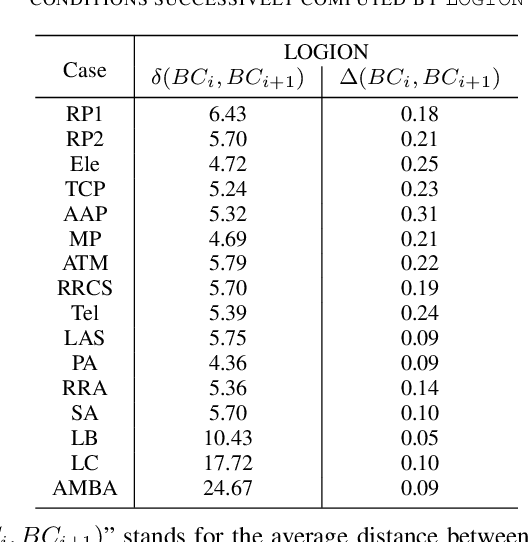
In goal-oriented requirements engineering, goal conflict identification is of fundamental importance for requirements analysis. The task aims to find the feasible situations which make the goals diverge within the domain, called boundary conditions (BCs). However, the existing approaches for goal conflict identification fail to find sufficient BCs and general BCs which cover more combinations of circumstances. From the BCs found by these existing approaches, we have observed an interesting phenomenon that there are some pairs of BCs are similar in formula structure, which occurs frequently in the experimental cases. In other words, once a BC is found, a new BC may be discovered quickly by slightly changing the former. It inspires us to develop a local search algorithm named LOGION to find BCs, in which the structural similarity is captured by the neighborhood relation of formulae. Based on structural similarity, LOGION can find a lot of BCs in a short time. Moreover, due to the large number of BCs identified, it potentially selects more general BCs from them. By taking experiments on a set of cases, we show that LOGION effectively exploits the structural similarity of BCs. We also compare our algorithm against the two state-of-the-art approaches. The experimental results show that LOGION produces one order of magnitude more BCs than the state-of-the-art approaches and confirm that LOGION finds out more general BCs thanks to a large number of BCs.
Refining HTN Methods via Task Insertion with Preferences
Nov 29, 2019


Hierarchical Task Network (HTN) planning is showing its power in real-world planning. Although domain experts have partial hierarchical domain knowledge, it is time-consuming to specify all HTN methods, leaving them incomplete. On the other hand, traditional HTN learning approaches focus only on declarative goals, omitting the hierarchical domain knowledge. In this paper, we propose a novel learning framework to refine HTN methods via task insertion with completely preserving the original methods. As it is difficult to identify incomplete methods without designating declarative goals for compound tasks, we introduce the notion of prioritized preference to capture the incompleteness possibility of methods. Specifically, the framework first computes the preferred completion profile w.r.t. the prioritized preference to refine the incomplete methods. Then it finds the minimal set of refined methods via a method substitution operation. Experimental analysis demonstrates that our approach is effective, especially in solving new HTN planning instances.
Representation Learning for Classical Planning from Partially Observed Traces
Jul 19, 2019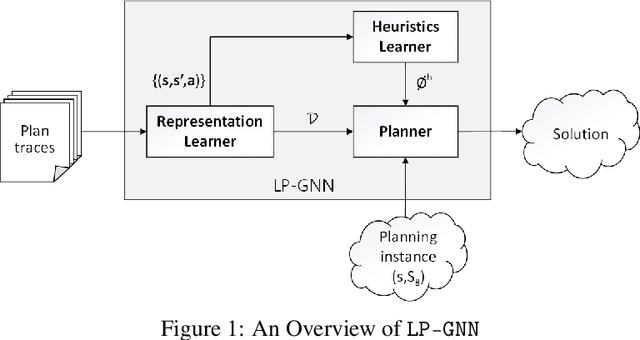
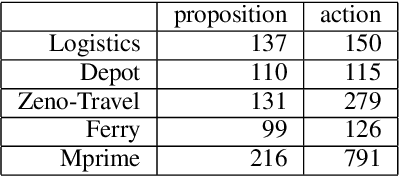
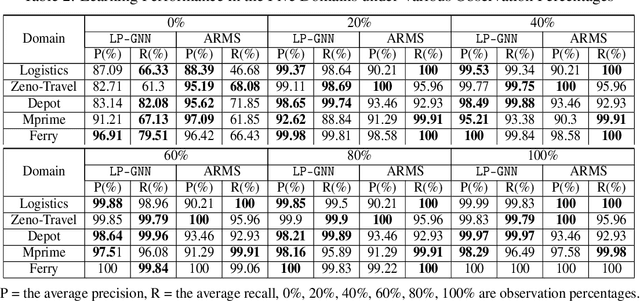
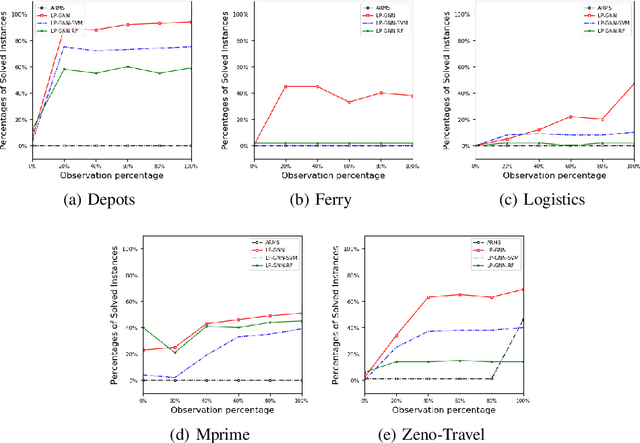
Specifying a complete domain model is time-consuming, which has been a bottleneck of AI planning technique application in many real-world scenarios. Most classical domain-model learning approaches output a domain model in the form of the declarative planning language, such as STRIPS or PDDL, and solve new planning instances by invoking an existing planner. However, planning in such a representation is sensitive to the accuracy of the learned domain model which probably cannot be used to solve real planning problems. In this paper, to represent domain models in a vectorization representation way, we propose a novel framework based on graph neural network (GNN) integrating model-free learning and model-based planning, called LP-GNN. By embedding propositions and actions in a graph, the latent relationship between them is explored to form a domain-specific heuristics. We evaluate our approach on five classical planning domains, comparing with the classical domain-model learner ARMS. The experimental results show that the domain models learned by our approach are much more effective on solving real planning problems.
CoAPI: An Efficient Two-Phase Algorithm Using Core-Guided Over-Approximate Cover for Prime Compilation of Non-Clausal Formulae
Jun 07, 2019
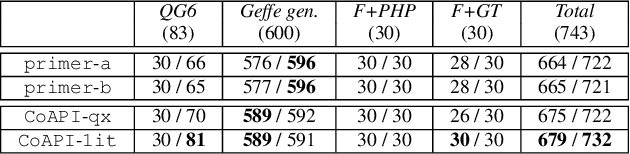
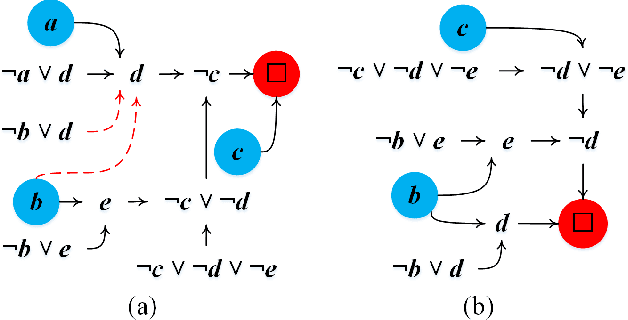
Prime compilation, i.e., the generation of all prime implicates or implicants (primes for short) of formulae, is a prominent fundamental issue for AI. Recently, the prime compilation for non-clausal formulae has received great attention. The state-of-the-art approaches generate all primes along with a prime cover constructed by prime implicates using dual rail encoding. However, the dual rail encoding potentially expands search space. In addition, constructing a prime cover, which is necessary for their methods, is time-consuming. To address these issues, we propose a novel two-phase method -- CoAPI. The two phases are the key to construct a cover without using dual rail encoding. Specifically, given a non-clausal formula, we first propose a core-guided method to rewrite the non-clausal formula into a cover constructed by over-approximate implicates in the first phase. Then, we generate all the primes based on the cover in the second phase. In order to reduce the size of the cover, we provide a multi-order based shrinking method, with a good tradeoff between the small size and efficiency, to compress the size of cover considerably. The experimental results show that CoAPI outperforms state-of-the-art approaches. Particularly, for generating all prime implicates, CoAPI consumes about one order of magnitude less time.
Combining Reinforcement Learning and Configuration Checking for Maximum k-plex Problem
Jun 06, 2019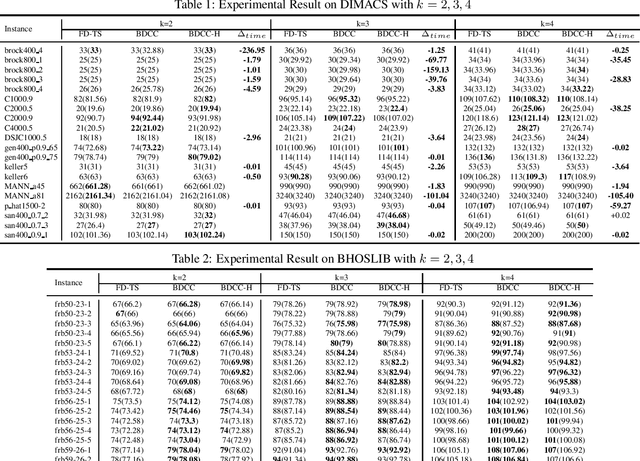
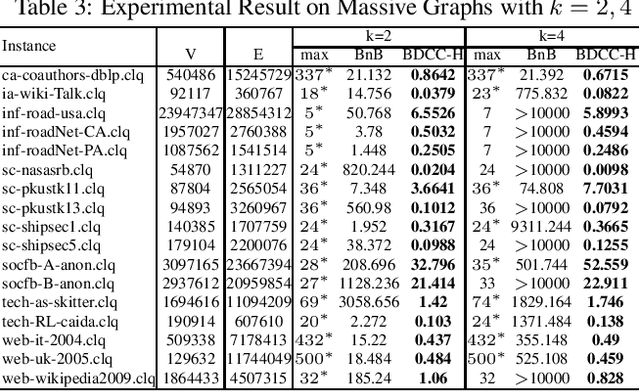
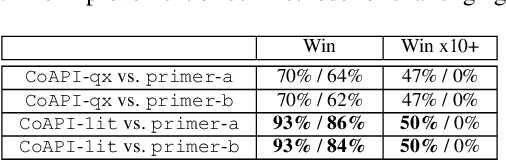
The Maximum k-plex Problem is an important combinatorial optimization problem with increasingly wide applications. Due to its exponential time complexity, many heuristic methods have been proposed which can return a good-quality solution in a reasonable time. However, most of the heuristic algorithms are memoryless and unable to utilize the experience during the search. Inspired by the multi-armed bandit (MAB) problem in reinforcement learning (RL), we propose a novel perturbation mechanism named BLP, which can learn online to select a good vertex for perturbation when getting stuck in local optima. To our best of knowledge, this is the first attempt to combine local search with RL for the maximum $ k $-plex problem. Besides, we also propose a novel strategy, named Dynamic-threshold Configuration Checking (DTCC), which extends the original Configuration Checking (CC) strategy from two aspects. Based on the BLP and DTCC, we develop a local search algorithm named BDCC and improve it by a hyperheuristic strategy. The experimental result shows that our algorithms dominate on the standard DIMACS and BHOSLIB benchmarks and achieve state-of-the-art performance on massive graphs.
A General Multi-agent Epistemic Planner Based on Higher-order Belief Change
Aug 14, 2018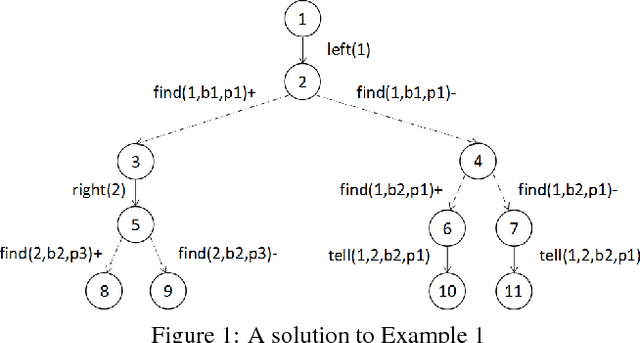
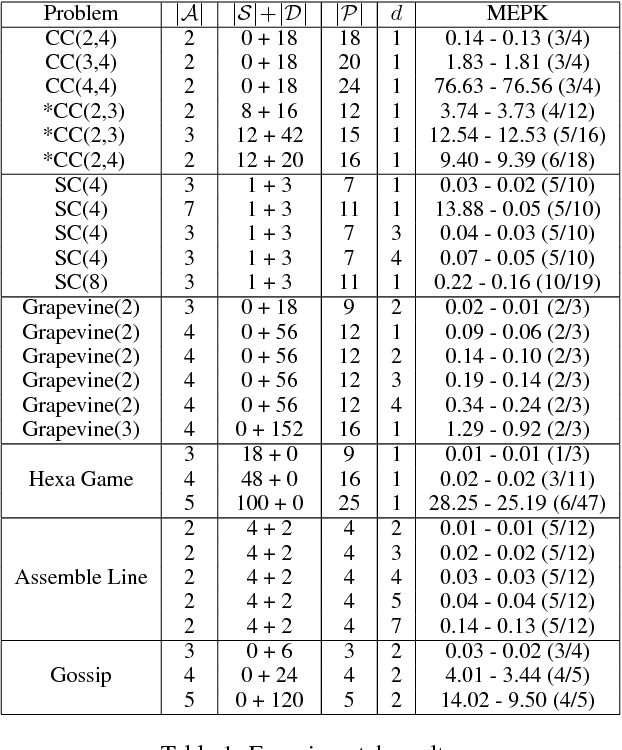
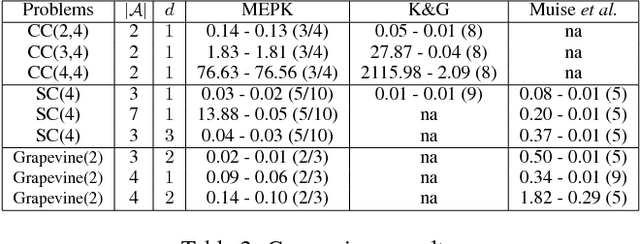
In recent years, multi-agent epistemic planning has received attention from both dynamic logic and planning communities. Existing implementations of multi-agent epistemic planning are based on compilation into classical planning and suffer from various limitations, such as generating only linear plans, restriction to public actions, and incapability to handle disjunctive beliefs. In this paper, we propose a general representation language for multi-agent epistemic planning where the initial KB and the goal, the preconditions and effects of actions can be arbitrary multi-agent epistemic formulas, and the solution is an action tree branching on sensing results. To support efficient reasoning in the multi-agent KD45 logic, we make use of a normal form called alternating cover disjunctive formulas (ACDFs). We propose basic revision and update algorithms for ACDFs. We also handle static propositional common knowledge, which we call constraints. Based on our reasoning, revision and update algorithms, adapting the PrAO algorithm for contingent planning from the literature, we implemented a multi-agent epistemic planner called MEPK. Our experimental results show the viability of our approach.
* One of the authors think it's not appropriate to show this work there days. Then we discussed, we want submit a new work and this one together later
Adversarial Attribute-Image Person Re-identification
Jul 04, 2018
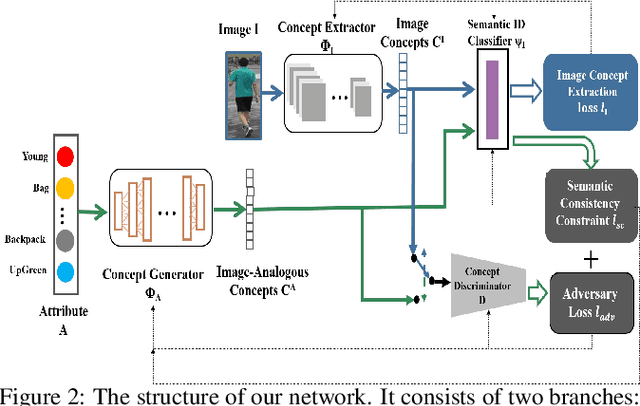
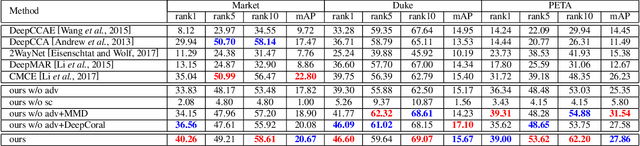
While attributes have been widely used for person re-identification (Re-ID) which aims at matching the same person images across disjoint camera views, they are used either as extra features or for performing multi-task learning to assist the image-image matching task. However, how to find a set of person images according to a given attribute description, which is very practical in many surveillance applications, remains a rarely investigated cross-modality matching problem in person Re-ID. In this work, we present this challenge and formulate this task as a joint space learning problem. By imposing an attribute-guided attention mechanism for images and a semantic consistent adversary strategy for attributes, each modality, i.e., images and attributes, successfully learns semantically correlated concepts under the guidance of the other. We conducted extensive experiments on three attribute datasets and demonstrated that the proposed joint space learning method is so far the most effective method for the attribute-image cross-modality person Re-ID problem.
Dependence in Propositional Logic: Formula-Formula Dependence and Formula Forgetting -- Application to Belief Update and Conservative Extension
Jun 29, 2018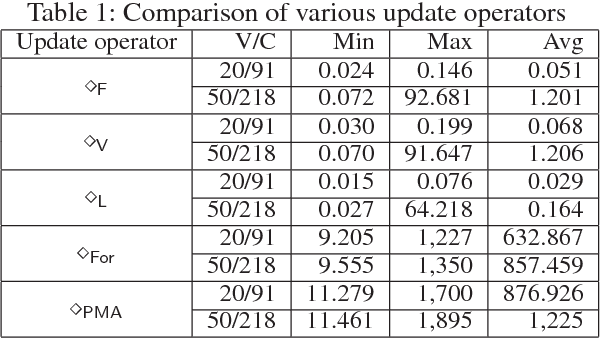
Dependence is an important concept for many tasks in artificial intelligence. A task can be executed more efficiently by discarding something independent from the task. In this paper, we propose two novel notions of dependence in propositional logic: formula-formula dependence and formula forgetting. The first is a relation between formulas capturing whether a formula depends on another one, while the second is an operation that returns the strongest consequence independent of a formula. We also apply these two notions in two well-known issues: belief update and conservative extension. Firstly, we define a new update operator based on formula-formula dependence. Furthermore, we reduce conservative extension to formula forgetting.
Query Answering with Inconsistent Existential Rules under Stable Model Semantics
Feb 18, 2016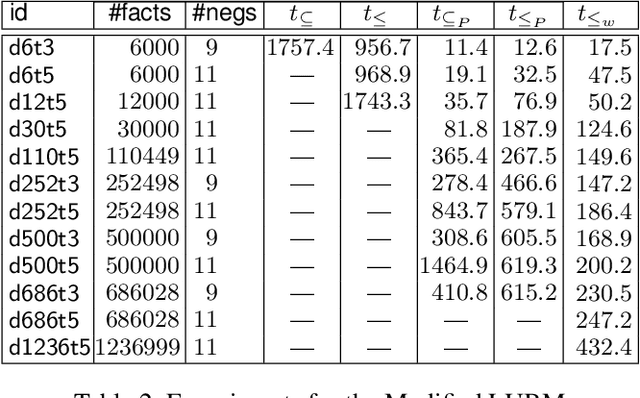
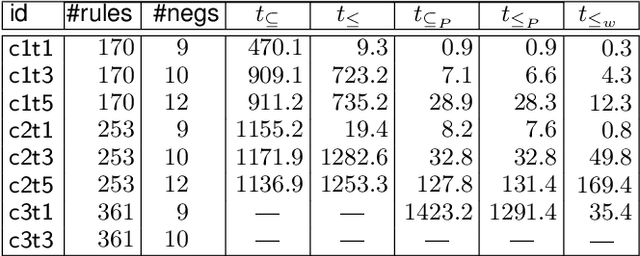
Traditional inconsistency-tolerent query answering in ontology-based data access relies on selecting maximal components of an ABox/database which are consistent with the ontology. However, some rules in ontologies might be unreliable if they are extracted from ontology learning or written by unskillful knowledge engineers. In this paper we present a framework of handling inconsistent existential rules under stable model semantics, which is defined by a notion called rule repairs to select maximal components of the existential rules. Surprisingly, for R-acyclic existential rules with R-stratified or guarded existential rules with stratified negations, both the data complexity and combined complexity of query answering under the rule {repair semantics} remain the same as that under the conventional query answering semantics. This leads us to propose several approaches to handle the rule {repair semantics} by calling answer set programming solvers. An experimental evaluation shows that these approaches have good scalability of query answering under rule repairs on realistic cases.