 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeFlow: Edge-Map Augmented VLM-Based Flowchart Processing for Industrial Requirements Engineering
May 26, 2026Flowcharts are widely used in industrial requirements, but usually remain embedded as static images. Vision Language Models (VLMs) show promise in the conversion of these flowcharts into machine-readable models for RE activities, yet, when directly applied to flowchart conversion, they often fail on topology-critical visual details. To address this, we propose EdgeFlow that augments a VLM's original input with a deterministically extracted Canny edge map-acting as a structural prior-to improve flowchart-to-Mermaid conversion, without requiring annotated training data or domain-specific model fine-tuning. We evaluate EdgeFlow on IndusReqFlow, a dataset sourced from real-world requirements. Compared with off-the-shelf VLMs, EdgeFlow improves node-level F1 by 17.39 percentage points and edge-level F1 by 16.94 percentage points. At the path level, EdgeFlow improves path F1 by 11.06 percentage points, enabling better support for model-based testing. These results demonstrate that EdgeFlow provides a practical, training-free means to improve topology-preserving flowchart-to-Mermaid conversion for industrial RE. Cross-dataset evaluation results on a public synthetic benchmark show no significant improvement; this highlights the need for diverse benchmarks incorporating industrial data for the comprehensive evaluation of future VLM-based RE tools.
Accurate and Consistent Graph Model Generation from Text with Large Language Models
Aug 01, 2025



Graph model generation from natural language description is an important task with many applications in software engineering. With the rise of large language models (LLMs), there is a growing interest in using LLMs for graph model generation. Nevertheless, LLM-based graph model generation typically produces partially correct models that suffer from three main issues: (1) syntax violations: the generated model may not adhere to the syntax defined by its metamodel, (2) constraint inconsistencies: the structure of the model might not conform to some domain-specific constraints, and (3) inaccuracy: due to the inherent uncertainty in LLMs, the models can include inaccurate, hallucinated elements. While the first issue is often addressed through techniques such as constraint decoding or filtering, the latter two remain largely unaddressed. Motivated by recent self-consistency approaches in LLMs, we propose a novel abstraction-concretization framework that enhances the consistency and quality of generated graph models by considering multiple outputs from an LLM. Our approach first constructs a probabilistic partial model that aggregates all candidate outputs and then refines this partial model into the most appropriate concrete model that satisfies all constraints. We evaluate our framework on several popular open-source and closed-source LLMs using diverse datasets for model generation tasks. The results demonstrate that our approach significantly improves both the consistency and quality of the generated graph models.
CoAPI: An Efficient Two-Phase Algorithm Using Core-Guided Over-Approximate Cover for Prime Compilation of Non-Clausal Formulae
Jun 07, 2019
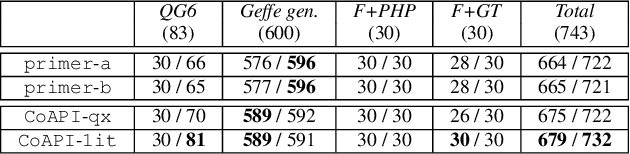
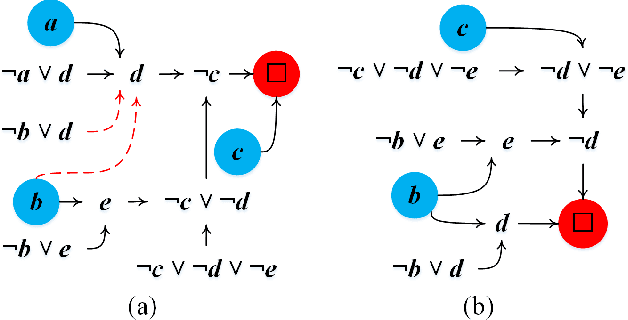
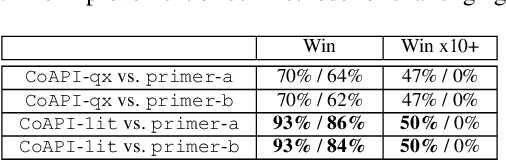
Prime compilation, i.e., the generation of all prime implicates or implicants (primes for short) of formulae, is a prominent fundamental issue for AI. Recently, the prime compilation for non-clausal formulae has received great attention. The state-of-the-art approaches generate all primes along with a prime cover constructed by prime implicates using dual rail encoding. However, the dual rail encoding potentially expands search space. In addition, constructing a prime cover, which is necessary for their methods, is time-consuming. To address these issues, we propose a novel two-phase method -- CoAPI. The two phases are the key to construct a cover without using dual rail encoding. Specifically, given a non-clausal formula, we first propose a core-guided method to rewrite the non-clausal formula into a cover constructed by over-approximate implicates in the first phase. Then, we generate all the primes based on the cover in the second phase. In order to reduce the size of the cover, we provide a multi-order based shrinking method, with a good tradeoff between the small size and efficiency, to compress the size of cover considerably. The experimental results show that CoAPI outperforms state-of-the-art approaches. Particularly, for generating all prime implicates, CoAPI consumes about one order of magnitude less time.