 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallel Approach to Counting Exact Covers Based on Decomposability Property
Apr 16, 2026The exact cover problem is a classical NP-hard problem with broad applications in the area of AI. Algorithm DXZ is a method to count exact covers representing by zero-suppressed binary decision diagrams (ZBDDs). In this paper, we propose a zero-suppressed variant of decision decomposable negation normal form (in short, decision-ZDNNF), which is strictly more succinct than ZBDDs. We then design a novel parallel algorithm, namely DXD, which constructs a decision-ZDNNF representing the set of all exact covers. Furthermore, we improve DXD by dynamically updating connected components. The experimental results demonstrate that the improved DXD algorithm outperforms all of state-of-the-art methods.
An Exhaustive DPLL Approach to Model Counting over Integer Linear Constraints with Simplification Techniques
Sep 17, 2025Linear constraints are one of the most fundamental constraints in fields such as computer science, operations research and optimization. Many applications reduce to the task of model counting over integer linear constraints (MCILC). In this paper, we design an exact approach to MCILC based on an exhaustive DPLL architecture. To improve the efficiency, we integrate several effective simplification techniques from mixed integer programming into the architecture. We compare our approach to state-of-the-art MCILC counters and propositional model counters on 2840 random and 4131 application benchmarks. Experimental results show that our approach significantly outperforms all exact methods in random benchmarks solving 1718 instances while the state-of-the-art approach only computes 1470 instances. In addition, our approach is the only approach to solve all 4131 application instances.
De-singularity Subgradient for the $q$-th-Powered $\ell_p$-Norm Weber Location Problem
Dec 20, 2024The Weber location problem is widely used in several artificial intelligence scenarios. However, the gradient of the objective does not exist at a considerable set of singular points. Recently, a de-singularity subgradient method has been proposed to fix this problem, but it can only handle the $q$-th-powered $\ell_2$-norm case ($1\leqslant q<2$), which has only finite singular points. In this paper, we further establish the de-singularity subgradient for the $q$-th-powered $\ell_p$-norm case with $1\leqslant q\leqslant p$ and $1\leqslant p<2$, which includes all the rest unsolved situations in this problem. This is a challenging task because the singular set is a continuum. The geometry of the objective function is also complicated so that the characterizations of the subgradients, minimum and descent direction are very difficult. We develop a $q$-th-powered $\ell_p$-norm Weiszfeld Algorithm without Singularity ($q$P$p$NWAWS) for this problem, which ensures convergence and the descent property of the objective function. Extensive experiments on six real-world data sets demonstrate that $q$P$p$NWAWS successfully solves the singularity problem and achieves a linear computational convergence rate in practical scenarios.
A De-singularity Subgradient Approach for the Extended Weber Location Problem
May 11, 2024



The extended Weber location problem is a classical optimization problem that has inspired some new works in several machine learning scenarios recently. However, most existing algorithms may get stuck due to the singularity at the data points when the power of the cost function $1\leqslant q<2$, such as the widely-used iterative Weiszfeld approach. In this paper, we establish a de-singularity subgradient approach for this problem. We also provide a complete proof of convergence which has fixed some incomplete statements of the proofs for some previous Weiszfeld algorithms. Moreover, we deduce a new theoretical result of superlinear convergence for the iteration sequence in a special case where the minimum point is a singular point. We conduct extensive experiments in a real-world machine learning scenario to show that the proposed approach solves the singularity problem, produces the same results as in the non-singularity cases, and shows a reasonable rate of linear convergence. The results also indicate that the $q$-th power case ($1<q<2$) is more advantageous than the $1$-st power case and the $2$-nd power case in some situations. Hence the de-singularity subgradient approach is beneficial to advancing both theory and practice for the extended Weber location problem.
Variants of Tagged Sentential Decision Diagrams
Nov 16, 2023



A recently proposed canonical form of Boolean functions, namely tagged sentential decision diagrams (TSDDs), exploits both the standard and zero-suppressed trimming rules. The standard ones minimize the size of sentential decision diagrams (SDDs) while the zero-suppressed trimming rules have the same objective as the standard ones but for zero-suppressed sentential decision diagrams (ZSDDs). The original TSDDs, which we call zero-suppressed TSDDs (ZTSDDs), firstly fully utilize the zero-suppressed trimming rules, and then the standard ones. In this paper, we present a variant of TSDDs which we call standard TSDDs (STSDDs) by reversing the order of trimming rules. We then prove the canonicity of STSDDs and present the algorithms for binary operations on TSDDs. In addition, we offer two kinds of implementations of STSDDs and ZTSDDs and acquire three variations of the original TSDDs. Experimental evaluations demonstrate that the four versions of TSDDs have the size advantage over SDDs and ZSDDs.
An Investigation of Darwiche and Pearl's Postulates for Iterated Belief Update
Oct 28, 2023


Belief revision and update, two significant types of belief change, both focus on how an agent modify her beliefs in presence of new information. The most striking difference between them is that the former studies the change of beliefs in a static world while the latter concentrates on a dynamically-changing world. The famous AGM and KM postulates were proposed to capture rational belief revision and update, respectively. However, both of them are too permissive to exclude some unreasonable changes in the iteration. In response to this weakness, the DP postulates and its extensions for iterated belief revision were presented. Furthermore, Rodrigues integrated these postulates in belief update. Unfortunately, his approach does not meet the basic requirement of iterated belief update. This paper is intended to solve this problem of Rodrigues's approach. Firstly, we present a modification of the original KM postulates based on belief states. Subsequently, we migrate several well-known postulates for iterated belief revision to iterated belief update. Moreover, we provide the exact semantic characterizations based on partial preorders for each of the proposed postulates. Finally, we analyze the compatibility between the above iterated postulates and the KM postulates for belief update.
VSRQ: Quantitative Assessment Method for Safety Risk of Vehicle Intelligent Connected System
May 03, 2023



The field of intelligent connected in modern vehicles continues to expand, and the functions of vehicles become more and more complex with the development of the times. This has also led to an increasing number of vehicle vulnerabilities and many safety issues. Therefore, it is particularly important to identify high-risk vehicle intelligent connected systems, because it can inform security personnel which systems are most vulnerable to attacks, allowing them to conduct more thorough inspections and tests. In this paper, we develop a new model for vehicle risk assessment by combining I-FAHP with FCA clustering: VSRQ model. We extract important indicators related to vehicle safety, use fuzzy cluster analys (FCA) combined with fuzzy analytic hierarchy process (FAHP) to mine the vulnerable components of the vehicle intelligent connected system, and conduct priority testing on vulnerable components to reduce risks and ensure vehicle safety. We evaluate the model on OpenPilot and experimentally demonstrate the effectiveness of the VSRQ model in identifying the safety of vehicle intelligent connected systems. The experiment fully complies with ISO 26262 and ISO/SAE 21434 standards, and our model has a higher accuracy rate than other models. These results provide a promising new research direction for predicting the security risks of vehicle intelligent connected systems and provide typical application tasks for VSRQ. The experimental results show that the accuracy rate is 94.36%, and the recall rate is 73.43%, which is at least 14.63% higher than all other known indicators.
A Mask-Based Adversarial Defense Scheme
Apr 21, 2022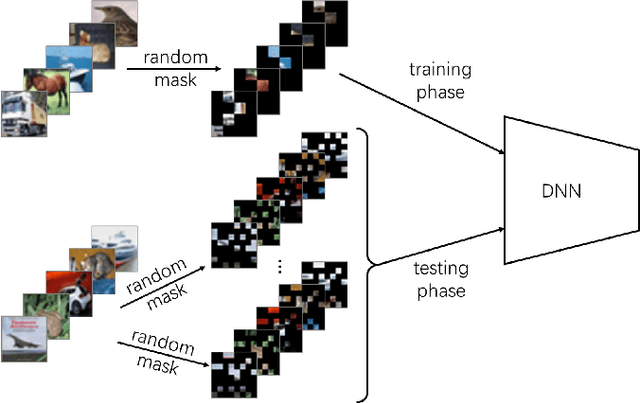

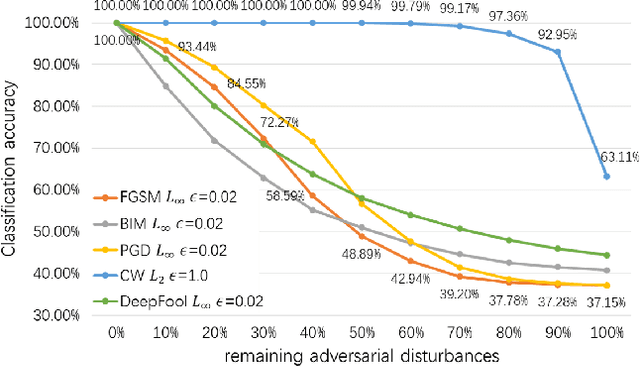
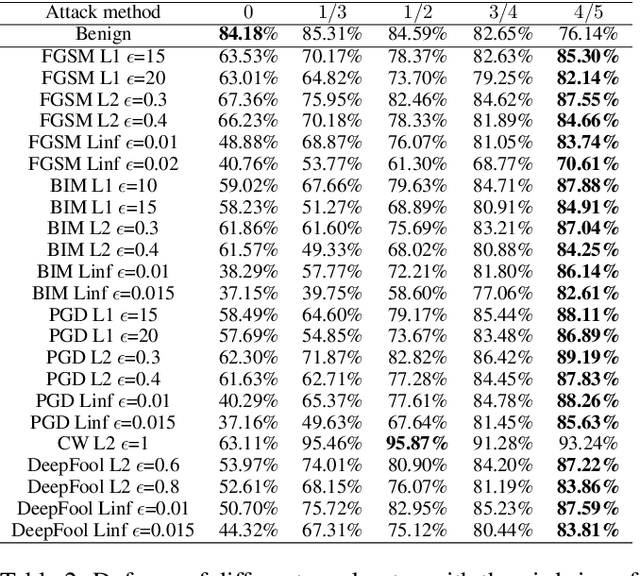
Adversarial attacks hamper the functionality and accuracy of Deep Neural Networks (DNNs) by meddling with subtle perturbations to their inputs.In this work, we propose a new Mask-based Adversarial Defense scheme (MAD) for DNNs to mitigate the negative effect from adversarial attacks. To be precise, our method promotes the robustness of a DNN by randomly masking a portion of potential adversarial images, and as a result, the %classification result output of the DNN becomes more tolerant to minor input perturbations. Compared with existing adversarial defense techniques, our method does not need any additional denoising structure, nor any change to a DNN's design. We have tested this approach on a collection of DNN models for a variety of data sets, and the experimental results confirm that the proposed method can effectively improve the defense abilities of the DNNs against all of the tested adversarial attack methods. In certain scenarios, the DNN models trained with MAD have improved classification accuracy by as much as 20% to 90% compared to the original models that are given adversarial inputs.
Dependence in Propositional Logic: Formula-Formula Dependence and Formula Forgetting -- Application to Belief Update and Conservative Extension
Jun 29, 2018
Dependence is an important concept for many tasks in artificial intelligence. A task can be executed more efficiently by discarding something independent from the task. In this paper, we propose two novel notions of dependence in propositional logic: formula-formula dependence and formula forgetting. The first is a relation between formulas capturing whether a formula depends on another one, while the second is an operation that returns the strongest consequence independent of a formula. We also apply these two notions in two well-known issues: belief update and conservative extension. Firstly, we define a new update operator based on formula-formula dependence. Furthermore, we reduce conservative extension to formula forgetting.
Knowledge Compilation in Multi-Agent Epistemic Logics
Jun 28, 2018


Epistemic logics are a primary formalism for multi-agent systems but major reasoning tasks in such epistemic logics are intractable, which impedes applications of multi-agent epistemic logics in automatic planning. Knowledge compilation provides a promising way of resolving the intractability by identifying expressive fragments of epistemic logics that are tractable for important reasoning tasks such as satisfiability and forgetting. The property of logical separability allows to decompose a formula into some of its subformulas and thus modular algorithms for various reasoning tasks can be developed. In this paper, by employing logical separability, we propose an approach to knowledge compilation for the logic Kn by defining a normal form SDNF. Among several novel results, we show that every epistemic formula can be equivalently compiled into a formula in SDNF, major reasoning tasks in SDNF are tractable, and formulas in SDNF enjoy the logical separability. Our results shed some lights on modular approaches to knowledge compilation. Furthermore, we apply our results in the multi-agent epistemic planning. Finally, we extend the above result to the logic K45n that is Kn extended by introspection axioms 4 and 5.